本文主要是介绍深入海洋:探索船只/垃圾/污染数据集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、船只类型数据集
介绍
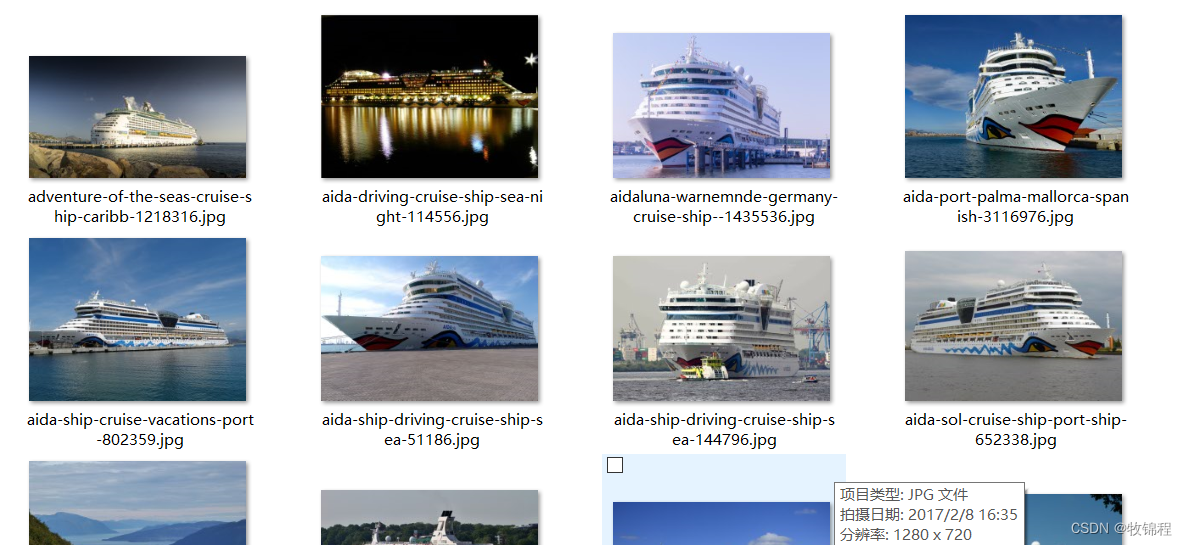
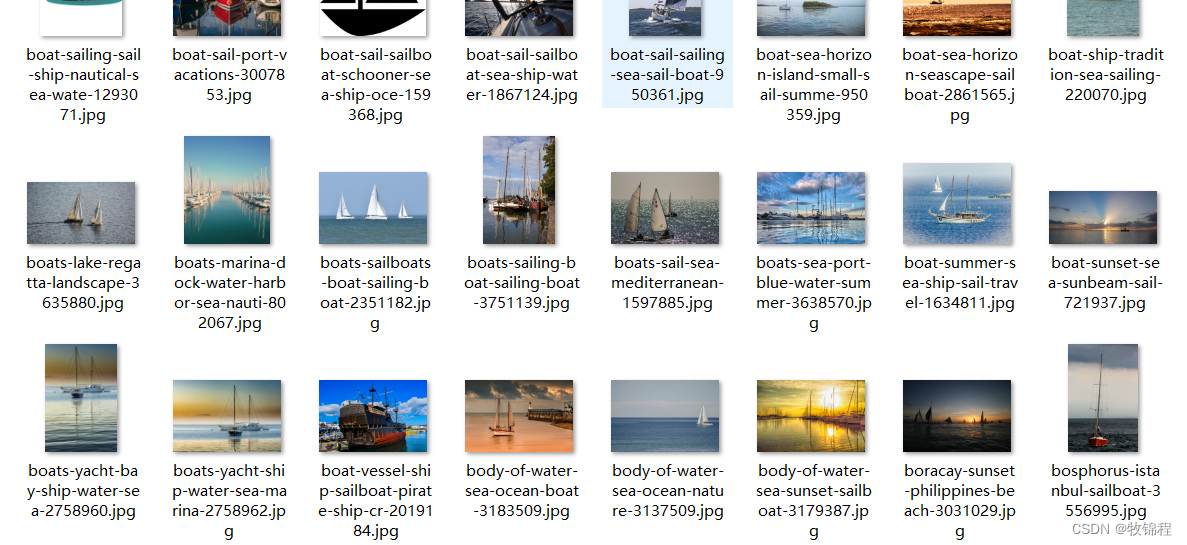
该数据集大约 1,500 张不同大小的船图片,
按不同类型分类:浮标、游轮、渡船、货船、贡多拉、充气船、皮划艇、纸船、帆船。
相关图片


二、AquaTrash垃圾识别数据集
介绍
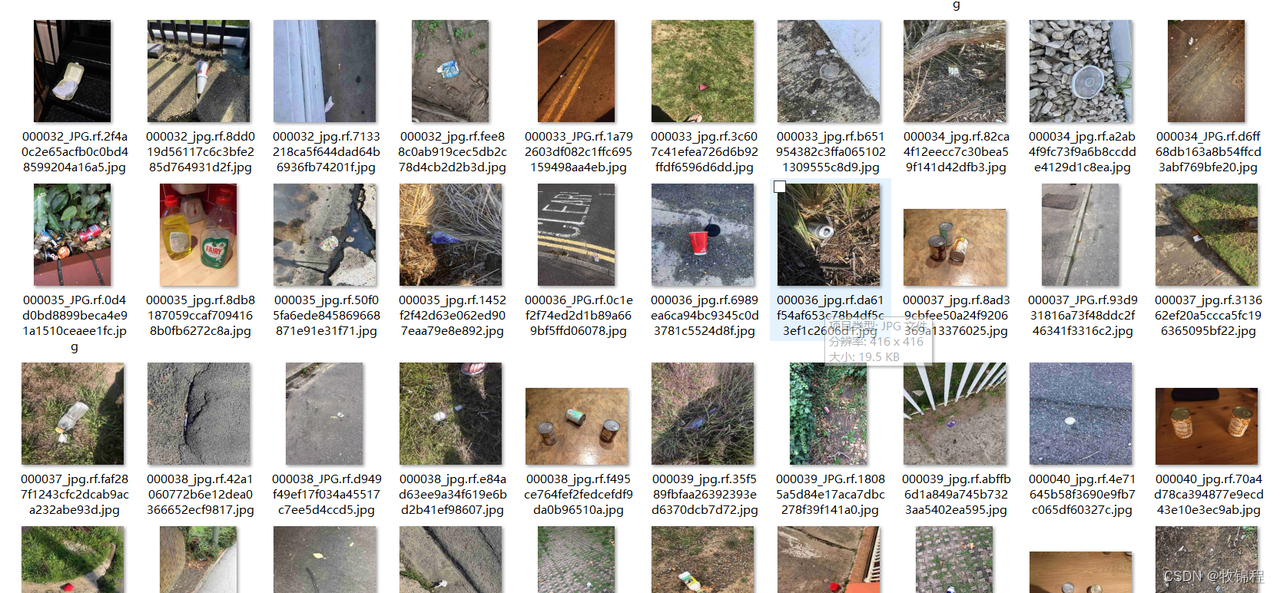
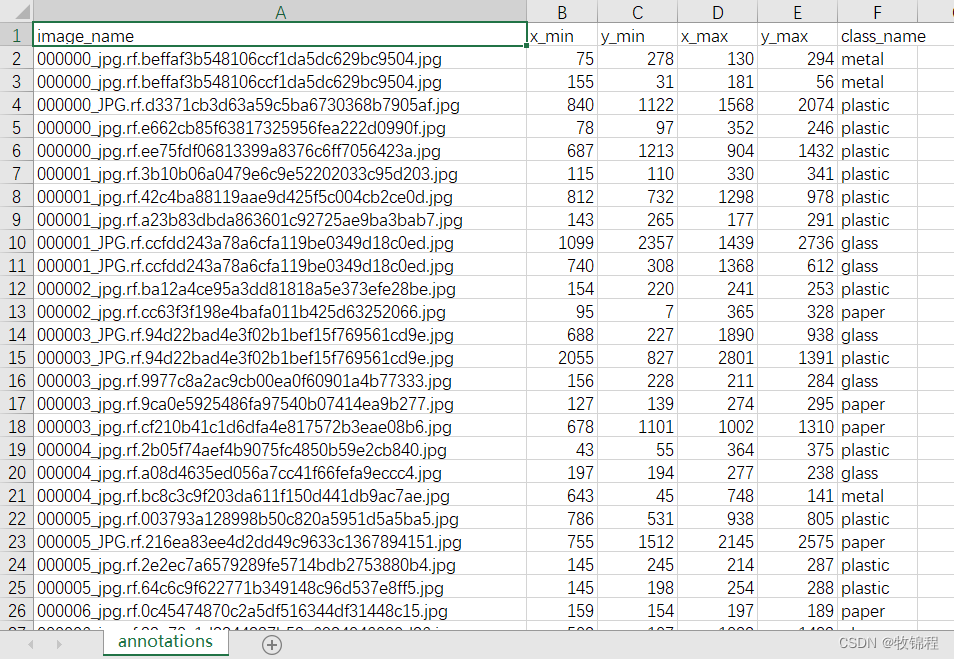
该数据集包含 369 张用于深度学习的垃圾图像。每张图片都由我们的团队手动标记以进行准确检测,总共有 470 个边界框。共有 4 类 {(0: glass), (1:paper), (2:metal), (3:plastic)}
相关图片

三、水下垃圾检测数据集
介绍
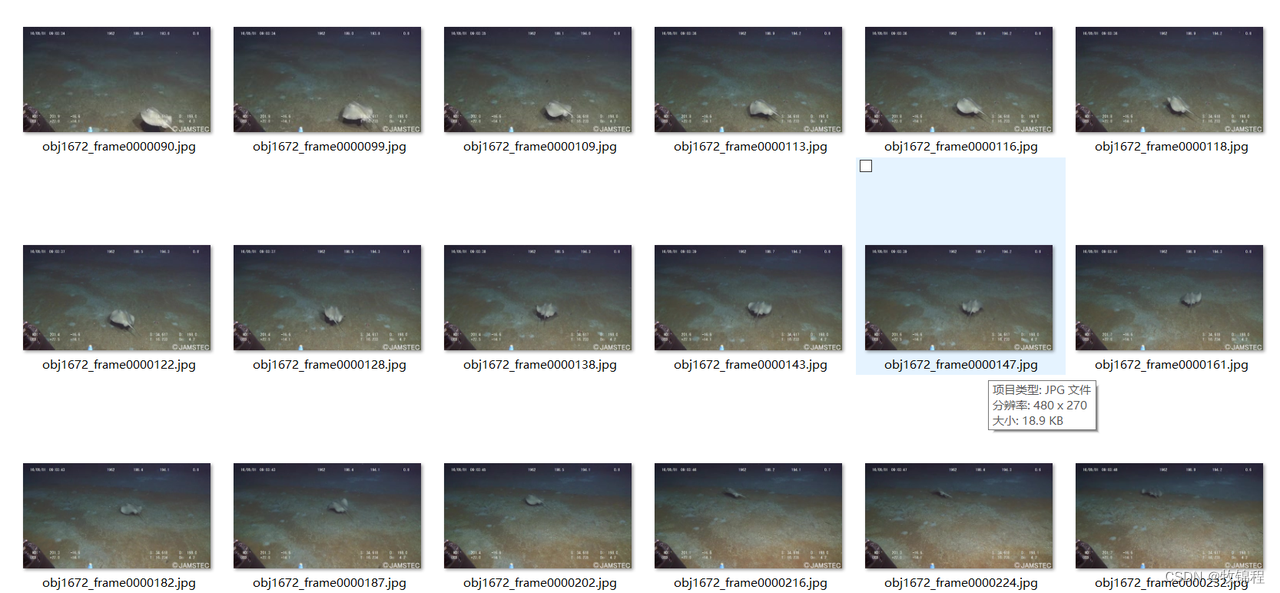
该数据来自海洋垃圾的J-EDI数据集。构成该数据集的视频在质量、深度、场景中的对象和使用的摄像机方面差异很大。它们包含许多不同类型的海洋垃圾的图像,这些图像是从真实环境中捕获的,提供了处于不同腐烂、遮挡和过度生长状态的各种物体。
此外,水的清晰度和光线的质量因视频而异。这些视频经过处理以提取构成该数据集的 5,700 张图像,所有图像都用边界框标记在垃圾、植物和动物等生物物体以及 ROV 的实例上。
最终目标是开发适用于车载机器人部署的高效准确的垃圾检测方法。我们希望该数据集的发布将促进对这一具有挑战性问题的进一步研究,使海洋机器人社区更接近于解决自动垃圾检测和清除的紧迫问题。
相关图片

四、水体污染检测数据集
介绍
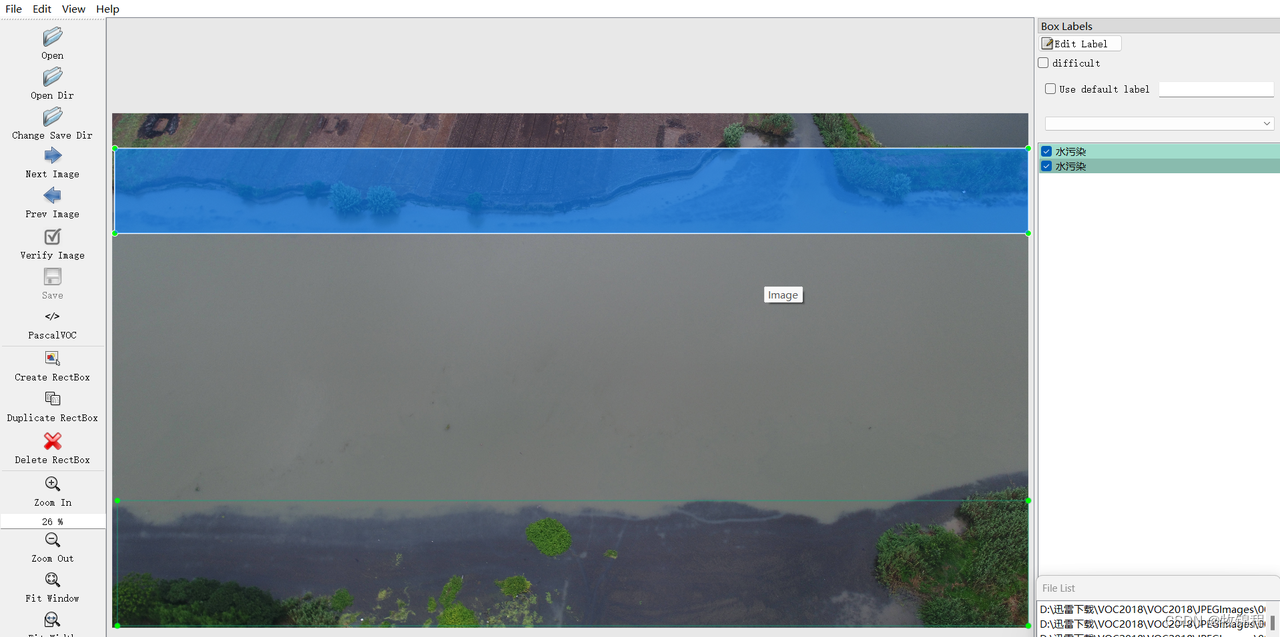
河道污染物采集了不同时间、不同地区的3000张河道水面航拍影像。
主要包含水污染、漂浮物、废弃船只、捕鱼养殖和废弃物五类的标注。
相关图片



五、数据下载
深入海洋:探索船只/垃圾/污染数据集
六、链接作者
欢迎关注我的公众号:@AI算法与电子竞赛
硬性的标准其实限制不了无限可能的我们,所以啊!少年们加油吧!
这篇关于深入海洋:探索船只/垃圾/污染数据集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






