本文主要是介绍深度主动学习(Deep Active Learning)——基于pytorch和ALipy工具包实现双向GRU模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
在ALipy的官网说ALipy只支持sklearn和tensorflow模型,模型对象应符合 scikit-learn api。
但是alipy提供了ToolBox的工具箱,里面包装了多种查询策略,计算指标等工具,几乎具有Alipy的全部功能,虽然不能使用ALipy提供的AlExperiment直接加载pytorch模型进行训练,但是可以使用ALipy中提供的ToolBox调用查询策略,计算指标等包装类。
我们的主动学习模型,使用ToolBox结合pytorch模型,可以省去写查询策略、计算指标等的代码。
流程
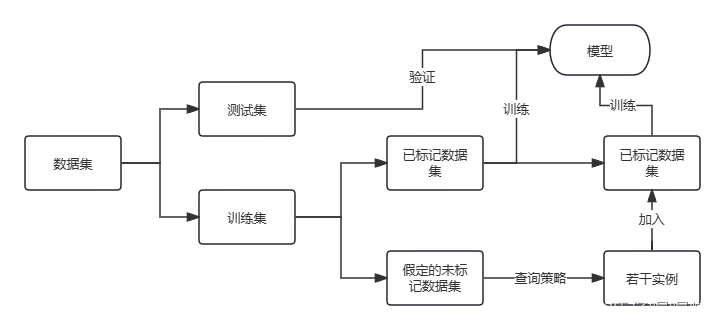
数据集分为训练集和测试集,数据集里的实例都是有标签值的,都是被标记的数据。
在训练集中将一部分数据(如:0.1,initial_label_rate = 0.1)作为已标记的数据,假定剩下的数据都是没有标记的(其实是被标记的),更具查询策略从假定的未标记的数据集中选出若干个实例(query_batch_size = 10 # 查询策略每次查询的实例数),加入到已标记的数据集,对模型进行训练。重复若干次(num_of_queries = 50 # 如果停止策略是num_of_queries,则设置查询次数)。
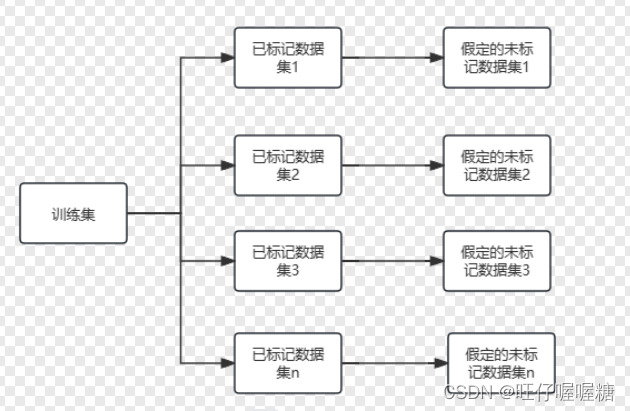
将训练集划分若干次(split_count = 20 # 将训练集划分出多少个初始化被标记集合)
注意:已标记数据集i+假定的未标记数据集i=训练集
数据集
数据集下载地址
代码
import copy
from sklearn.datasets import make_classification
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import numpy as np
import pandas as pd
import time
import matplotlib.pyplot as plt
import math
from alipy import ToolBox
# python3.9以上版本需要加上
import collectionscollections.Iterable = collections.abc.Iterable# config
BATCH_SIZE = 256 # batch size
HIDDEN_SIZE = 100 # 隐层维度
N_LAYER = 2 # RNN层数
N_EPOCHS = 100 # 训练轮数
N_CHARS = 128 # 字符
USE_GPU = True # 是否使用gpu
performance_metric = 'accuracy_score' # alipy box的性能指标
# device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
device = torch.device('cuda:0') # 使用gpu
learning_rate = 0.001 # 学习率
stopping_criterion = 'num_of_queries' # 停止策略
num_of_queries = 10 # 如果停止策略是num_of_queries,则设置查询次数
test_ratio = 0.1 # 测试集的比例
initial_label_rate = 0.4 # 初始化被标记实例的比例
split_count = 15 # 将训练集划分出多少个初始化被标记集合
query_batch_size = 10 # 查询策略每次查询的实例数
query_type = 'AllLabels' # 查询类型
saving_path = '.' # 保存路径
train_file = 'data/names_train.csv'
test_file = 'data/names_test.csv'
dev_acc_list = []# prepare data
class NameDataset(Dataset):def __init__(self, is_train_set=True):filename = 'data/names_train.csv' if is_train_set else 'data/names_test.csv'data = pd.read_csv(filename, delimiter=',', names=['names', 'country'])self.names = data['names']self.len = len(self.names)self.countries = data['country']self.countries_list = list(sorted(set(self.countries)))self.countries_dict = self.getCountryDict()self.countries_num = len(self.countries_list)def __getitem__(self, item):return self.names[item], self.countries_dict[self.countries[item]]def __len__(self):return self.lendef getCountryDict(self):country_dict = {}for idx, country in enumerate(self.countries_list, 0):country_dict[country] = idxreturn country_dictdef id2country(self, idx):return self.countries[idx]def getCountryNum(self):return self.countries_num# 主动学习训练集
class ALDataset(Dataset):def __init__(self, names, countries):self.names = namesself.countries = countriesself.countries_list = list(sorted(set(self.countries)))self.countries_dict = self.getCountryDict()self.countries_num = len(self.countries_list)def __getitem__(self, item):return self.names[item], self.countries_dict[self.countries[item]]def __len__(self):assert len(self.names) == len(self.countries)return len(self.names)def getCountryDict(self):country_dict = {}for idx, country in enumerate(self.countries_list, 0):country_dict[country] = idxreturn country_dictdef update(self, names, countries):self.names = np.append(self.names, names)self.countries = np.append(self.countries, countries)self.countries_list = list(sorted(set(self.countries)))self.countries_dict = self.getCountryDict()self.countries_num = len(self.countries_list)# 训练集
train_data = NameDataset(is_train_set=True)
# trainloader = DataLoader(train_data, shuffle=True)
# 测试集
test_data = NameDataset(is_train_set=False)
init_testloader = DataLoader(test_data, shuffle=False)
train_names = list(train_data.names)
train_countries = list(train_data.countries)
N_COUNTRY = train_data.getCountryNum() # 国家的数量# 模型
class RNNClassifier(torch.nn.Module):def __init__(self, input_size, hidden_size, output_size, n_layer=1, bidirectional=True):super(RNNClassifier, self).__init__()self.hidden_size = hidden_sizeself.n_layer = n_layerself.n_directions = 2 if bidirectional else 1self.emb = torch.nn.Embedding(input_size, hidden_size)self.gru = torch.nn.GRU(hidden_size, hidden_size, num_layers=n_layer,bidirectional=bidirectional)self.fc = torch.nn.Linear(hidden_size * self.n_directions, output_size)def forward(self, inputs, seq_lengths):inputs = create_tensor(inputs.t())batch_size = inputs.size(1)hidden = self._init_hidden(batch_size)embedding = self.emb(inputs)gru_input = torch.nn.utils.rnn.pack_padded_sequence(embedding, seq_lengths, enforce_sorted=False) # 用于提速output, hidden = self.gru(gru_input, hidden)if self.n_directions == 2:# 如果是双向神经网络,则有两个hidden,需要将它们拼接起来hidden_cat = torch.cat([hidden[-1], hidden[-2]], dim=1)else:hidden_cat = hidden[-1]fc_output = self.fc(hidden_cat)return fc_outputdef _init_hidden(self, batch_size):hidden = torch.zeros(self.n_layer * self.n_directions, batch_size, self.hidden_size)return create_tensor(hidden)def create_tensor(tensor):if USE_GPU:device = torch.device('cuda:0')tensor = tensor.to(device)return tensordef make_tensors(names, countries):sequences_and_lengths = [name2list(name) for name in names] # 得到name所有字符的ASCII码值和name的长度name_sequences = [sl[0] for sl in sequences_and_lengths] # 获取name中所有字符的ASCII码值seq_lengths = torch.LongTensor([sl[1] for sl in sequences_and_lengths]) # 获取所有name的长度# 获得所有name的tensor,形状 batch_size*max(seq_len) 即name的个数*最长的name的长度seq_tensor = torch.zeros(len(name_sequences), seq_lengths.max()).long() # 形状[name的个数*最长的name的长度]for idx, (seq, seq_len) in enumerate(zip(name_sequences, seq_lengths), 0):seq_tensor[idx, :seq_len] = torch.LongTensor(seq) # 将所有name逐行填充到seq_tensor中# sort by length to use pack_padded_sequenceseq_lengths, perm_idx = seq_lengths.sort(dim=0, descending=True) # 将seq_lengths按降序排列,perm_idx是排序后的序号seq_tensor = seq_tensor[perm_idx] # seq_tensor中的顺序也随之改变countries = countries[perm_idx] # countries中的顺序也随之改变# 返回所有names转为ASCII码的tensor,所有names的长度的tensor,所有country的tensorreturn seq_tensor, \seq_lengths, \countriesdef name2list(name):arr = [ord(c) for c in name] # 将string转为list且所有字符转为ASCII码值return arr, len(arr) # 返回的是tuple([arr],len(arr))def main_loop(alibox, strategy, round):# Get the data split of one fold experiment# 对实验数据进行拆分train_idx, test_idx, label_ind, unlab_ind = alibox.get_split(round)# Get intermediate results saver for one fold experiment# 获取StateIO对象saver = alibox.get_stateio(round)# 获取训练集al_traindataal_traindata = ALDataset(np.array(train_names)[label_ind], np.array(train_countries)[label_ind])# 测试test_inputs = X[test_idx].to(device)test_lengths = seq_lengths[test_idx]test_targets = y[test_idx].to(device)pred = model(test_inputs, test_lengths).max(dim=1, keepdim=True)[1]# 计算准确率accuracy = alibox.calc_performance_metric(y_true=test_targets.to('cpu'),y_pred=pred.to('cpu'),performance_metric=performance_metric)# 保存参数saver.set_initial_point(accuracy)# If the stopping criterion is simple, such as query 50 times. Use `for i in range(50):` is ok.total_loss = 0.0while not stopping_criterion.is_stop():# Select a subset of Uind according to the query strategy# Passing model=None to use the default model for evaluating the committees' disagreementselect_ind = strategy.select(label_index=label_ind, unlabel_index=unlab_ind,batch_size=query_batch_size)label_ind.update(select_ind)unlab_ind.difference_update(select_ind)# 获得初始更新al_traindataal_traindata.update(np.array(train_names)[select_ind], np.array(train_countries)[select_ind])al_trainloader = DataLoader(al_traindata, batch_size=BATCH_SIZE, shuffle=True)# 训练模型modelTrain(al_trainloader)# 测试model.eval()with torch.no_grad():test_inputs = X[test_idx].to(device)test_lengths = seq_lengths[test_idx]test_targets = y[test_idx].to(device)pred = model(test_inputs, test_lengths).max(dim=1, keepdim=True)[1]# 计算准确率accuracy = alibox.calc_performance_metric(y_true=test_targets.to('cpu'),y_pred=pred.to('cpu'),performance_metric=performance_metric)# Save intermediate results to filest = alibox.State(select_index=select_ind, performance=accuracy)saver.add_state(st)# Passing the current progress to stopping criterion objectstopping_criterion.update_information(saver)# Reset the progress in stopping criterion objectprint('loss: %.4f, accuracy: %.4f' % (total_loss / float(stopping_criterion.value), accuracy))stopping_criterion.reset()return saverdef active_learning(alibox):unc_result = []qbc_result = []eer_result = []quire_result = []density_result = []bmdr_result = []spal_result = []lal_result = []rnd_result = []_I_have_installed_the_cvxpy = Falsefor round in range(split_count):train_idx, test_idx, label_ind, unlab_ind = alibox.get_split(round)# Use pre-defined strategy# 获得初始trainloader和testloaderal_traindata = ALDataset(np.array(train_names)[label_ind], np.array(train_countries)[label_ind])al_trainloader = DataLoader(al_traindata, batch_size=BATCH_SIZE, shuffle=True)al_testdata = ALDataset(np.array(train_names)[test_idx], np.array(train_countries)[test_idx])al_testloader = DataLoader(al_testdata, batch_size=BATCH_SIZE, shuffle=False)# 训练模型loss = modelTrain(al_trainloader)print('loss:', loss / (al_traindata.__len__() / BATCH_SIZE).__ceil__())modelTest(al_testloader)unc = alibox.get_query_strategy(strategy_name="QueryInstanceUncertainty")qbc = alibox.get_query_strategy(strategy_name="QueryInstanceQBC")# eer = alibox.get_query_strategy(strategy_name="QueryExpectedErrorReduction")rnd = alibox.get_query_strategy(strategy_name="QueryInstanceRandom")# quire = alibox.get_query_strategy(strategy_name="QueryInstanceQUIRE", train_idx=train_idx)density = alibox.get_query_strategy(strategy_name="QueryInstanceGraphDensity", train_idx=train_idx)# lal = alibox.get_query_strategy(strategy_name="QueryInstanceLAL", cls_est=10, train_slt=False)# lal.download_data()# lal.train_selector_from_file(reg_est=30, reg_depth=5)unc_result.append(copy.deepcopy(main_loop(alibox, unc, round)))qbc_result.append(copy.deepcopy(main_loop(alibox, qbc, round)))# eer_result.append(copy.deepcopy(main_loop(alibox, eer, round)))rnd_result.append(copy.deepcopy(main_loop(alibox, rnd, round)))# quire_result.append(copy.deepcopy(main_loop(alibox, quire, round)))density_result.append(copy.deepcopy(main_loop(alibox, density, round)))# lal_result.append(copy.deepcopy(main_loop(alibox, lal, round)))if _I_have_installed_the_cvxpy:bmdr = alibox.get_query_strategy(strategy_name="QueryInstanceBMDR", kernel='rbf')spal = alibox.get_query_strategy(strategy_name="QueryInstanceSPAL", kernel='rbf')bmdr_result.append(copy.deepcopy(main_loop(alibox, bmdr, round)))spal_result.append(copy.deepcopy(main_loop(alibox, spal, round)))dev_acc_list.append(modelTest(init_testloader))analyser = alibox.get_experiment_analyser(x_axis='num_of_queries')analyser.add_method(method_name='Unc', method_results=unc_result)analyser.add_method(method_name='QBC', method_results=qbc_result)# analyser.add_method(method_name='EER', method_results=eer_result)analyser.add_method(method_name='Random', method_results=rnd_result)# analyser.add_method(method_name='QUIRE', method_results=quire_result)analyser.add_method(method_name='Density', method_results=density_result)# analyser.add_method(method_name='LAL', method_results=lal_result)if _I_have_installed_the_cvxpy:analyser.add_method(method_name='BMDR', method_results=bmdr_result)analyser.add_method(method_name='SPAL', method_results=spal_result)print(analyser)analyser.plot_learning_curves(title='Example of alipy', std_area=False)def modelTrain(trainloader):model.train()total_loss = 0.0for i, (names, countries) in enumerate(trainloader, 1):inputs, seq_lengths, targets = make_tensors(names, countries)inputs = create_tensor(inputs)targets = create_tensor(targets)output = model(inputs, seq_lengths.to('cpu'))loss = criterion(output, targets)optimizer.zero_grad()loss.backward()optimizer.step()total_loss += loss.item()return total_loss # 返回一轮训练的所有loss之和def modelTest(testloader):correct = 0total = len(testloader.dataset.names)#total = len(test_data)print('evaluating trained model...')model.eval()with torch.no_grad():for i, (names, countries) in enumerate(testloader, 1):inputs, seq_lengths, targets = make_tensors(names, countries)inputs = inputs.to(device)targets = targets.to(device)output = model(inputs, seq_lengths.to('cpu'))pred = output.max(dim=1, keepdim=True)[1]correct += pred.eq(targets.view_as(pred)).sum().item()percent = '%.2f' % (100 * correct / total)print(f'Test set:Accuracy{correct}/{total} {percent}%')return correct / totaldef time_since(since):s = time.time() - sincem = math.floor(s / 60)s -= m * 60return '%dm %ds' % (m, s)if __name__ == '__main__':X_names = tuple(train_data.names)X_countries = torch.tensor([train_data.countries_dict[country] for country in train_data.countries])X, seq_lengths, y = make_tensors(X_names, X_countries)alibox = ToolBox(X=X, y=y, query_type=query_type, saving_path=saving_path)# Split dataalibox.split_AL(test_ratio=test_ratio,initial_label_rate=initial_label_rate,split_count=split_count)# Use the default Logistic Regression classifiermodel = RNNClassifier(N_CHARS, HIDDEN_SIZE, N_COUNTRY, N_LAYER, bidirectional=True).to(device)# The cost budget is 50 times querying# 设置停止器,此处是查询50次stopping_criterion = alibox.get_stopping_criterion(stopping_criterion, num_of_queries)criterion = torch.nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.parameters(), learning_rate)active_learning(alibox)plt.plot(range(1, len(dev_acc_list) + 1), dev_acc_list)plt.xlabel('Epochs')plt.ylabel('Accuracy')plt.show()for i in range(len(dev_acc_list)):print(dev_acc_list[i])
运行结果
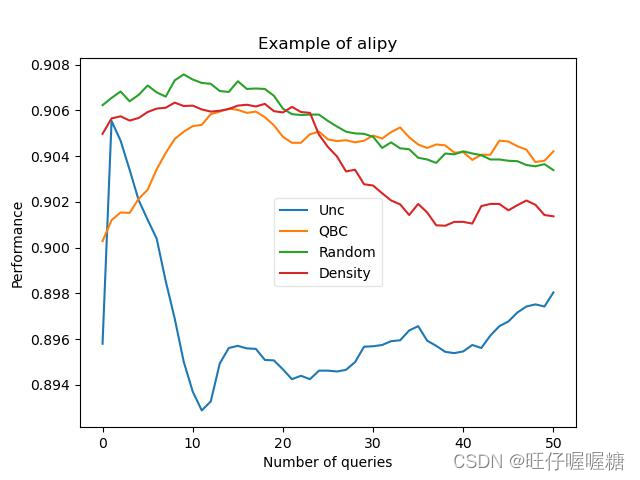
本图的准确率是在测试集上的效果(从训练集中划分出20%作为测试集)
在验证集上的准确率最高达到83%-84%,在之前的博客中,直接使用双向GRU模型,同样的数据集,准确率能达到84%左右,加上主动学习准确率反而下降了1%左右。
原因可能是因为主动学习更适合使用在少样本的数据集上,本文使用的数据集样本数量在13000+,因此直接使用深度学习的效果更佳。
这篇关于深度主动学习(Deep Active Learning)——基于pytorch和ALipy工具包实现双向GRU模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






