本文主要是介绍北京大学肖臻老师《区块链技术与应用》P16(状态树)和P17(交易树和收据树),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1️⃣ 参考
- 北京大学肖臻老师《区块链技术与应用》
- P16 - ETH状态树篇
- P17 - ETH交易树和收据树篇
- 部分文字和图片
- 北京大学肖臻老师《区块链技术与应用》公开课笔记18——ETH数据结构篇2(状态树2)
- 北京大学肖臻老师《区块链技术与应用》公开课笔记19——ETH数据结构篇3(交易树和收据树)
1️⃣6️⃣ 状态树
① 引言
- 回顾
- 以太坊账户地址为160bits(20字节),表示为40个16进制数
- 状态包含了
- 余额(
balance) - 交易次数(
nonce) - 合约账户中还包含了代码(
code) 和 存储(stroge)
- 余额(
- 在比特币和以太坊系统中,核心单位是区块,是通过区块构成区块链,交易是保存在区块内部
- 在脑中要有一个意识,每个人都可以在本地构建区块链,只是像在比特币系统中上链的区块是矿工说的算,其他人复制
现在要实现从账户地址到账户状态的映射,咋一看,容易想到Key-value键值对,所以直观想法便用哈希表实现。若不考虑哈希碰撞,查询直接为常数级别的查询效率。
但采用哈希表,难以提供Merkle proof(需要回顾请看这里)
Merkle Tree- 作用
- 提供证明账户上余额
- 维护全节点之间状态的一致性(对于当前区块中包含了哪些交易,全节点之间要有共识)
- 缺点
- 没有提供一个高效的查找和更新的方法
- 作用
思考
- 比特币为什么可以构建
Merkle Tree,而以太坊不行 ?
- 因为构建的内容不是一个量级的
- 在比特币系统中,仅对一个区块中的交易(最多包含4000左右) 构造,前面构建好的是不发生变化的
- 在以太坊系统中,基于账户的模式下,每发布一个区块,要将所有的账户都遍历一遍来构建,开销太大。
- 构建出的
Merkle Tree不唯一
- 在比特币系统中,没有排序不影响,因为是一人(拥有记账权的矿工 POW)说的算,其他都都是复制,所以大家得到的Merkle Tree是唯一的
- 在以太坊系统中,因为没有排序,没办法保证新账户出现在叶子节点的顺序(因为每个人接受新节点的顺序是不一样的),算出的根哈希值不同,所以构建的
Merkle Tree不唯一
思考
- 那么经过排序,使用
Sorted Merkle Tree可以吗?
- 还是开销太大,新增账户,由于其地址随机,插入
Merkle Tree时候很大可能在树中间,发现其必须进行重构。(牵一发而动全身)
所以,简单的Merkle Tree和哈希表数据结构是不满足的
那么我们看一下实际中以太坊采取的数据结构:MPT(第四小节)
② trie(字典树、前缀树)
-
取自单词
retrievaln. 检索 -
下图是使用
trie数据结构对单词进行存储
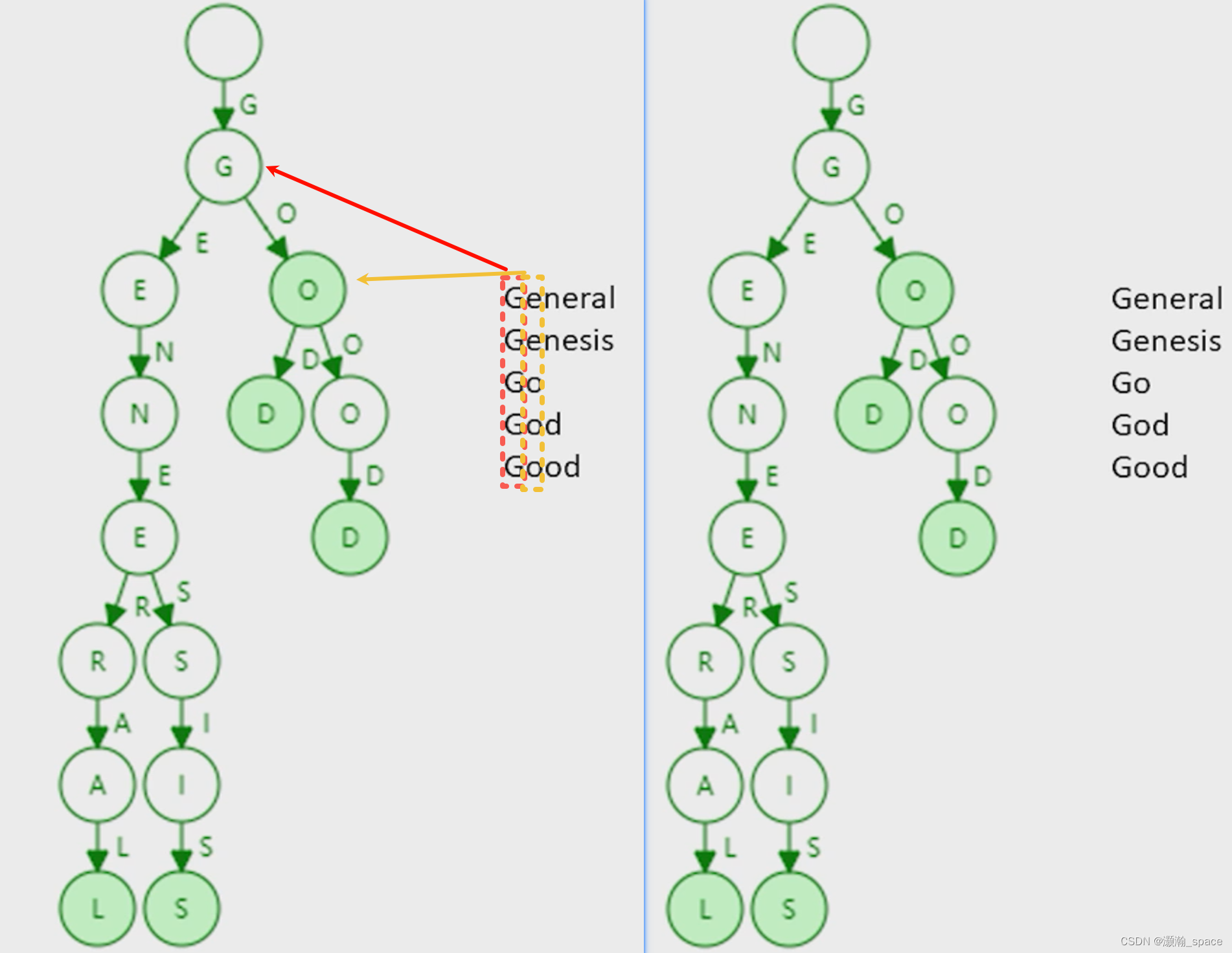
-
trie特点:- trie中每个节点的分支数目取决于Key值中每个元素的取值范围【图例中最多26个英文字母分叉 + 一个结束标志位;以太坊中最多17,16进制(0 ~ f) + 1结束符】。
- trie查找效率取决于key的长度。实际应用中每个地址长度都是相同的
- 理论上哈希会出现碰撞,而
trie上面不会发生碰撞。 - 给定输入后构造的trie都是一样的(无论如何顺序插入)。
- 更新操作的局部性较好(只用更新其分支,其他不变)
trie缺点:trie的存储浪费,很多节点只存储一个key(叶子节点)。因此,要是能合并一些就好了,为此,引入了Patricia tree/trie
③ Patricia trie(经过路径压缩的前缀树,压缩前缀树)
- 下图为压缩后,明显树的高度变得浅了,访问内存的次数将会大大减少,提高了效率
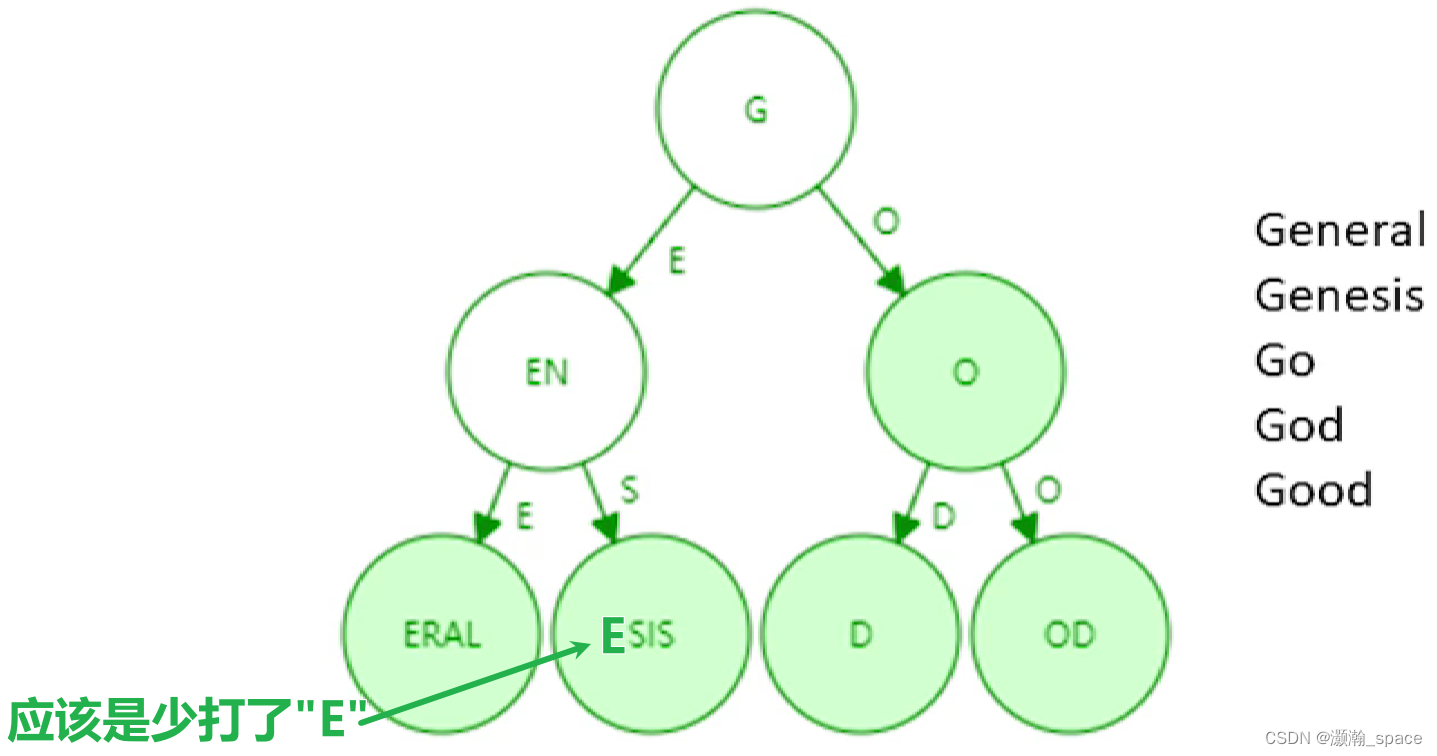
需要注意的是,如果新插入单词,原本压缩的路径可能需要扩展开来。
问题
- 那么,需要考虑什么情况下路径压缩效果较好?
- 树中插入的键值分布较为稀疏的情况下,可见路径压缩效果较好(如下图)。
Disintermediation去中间商
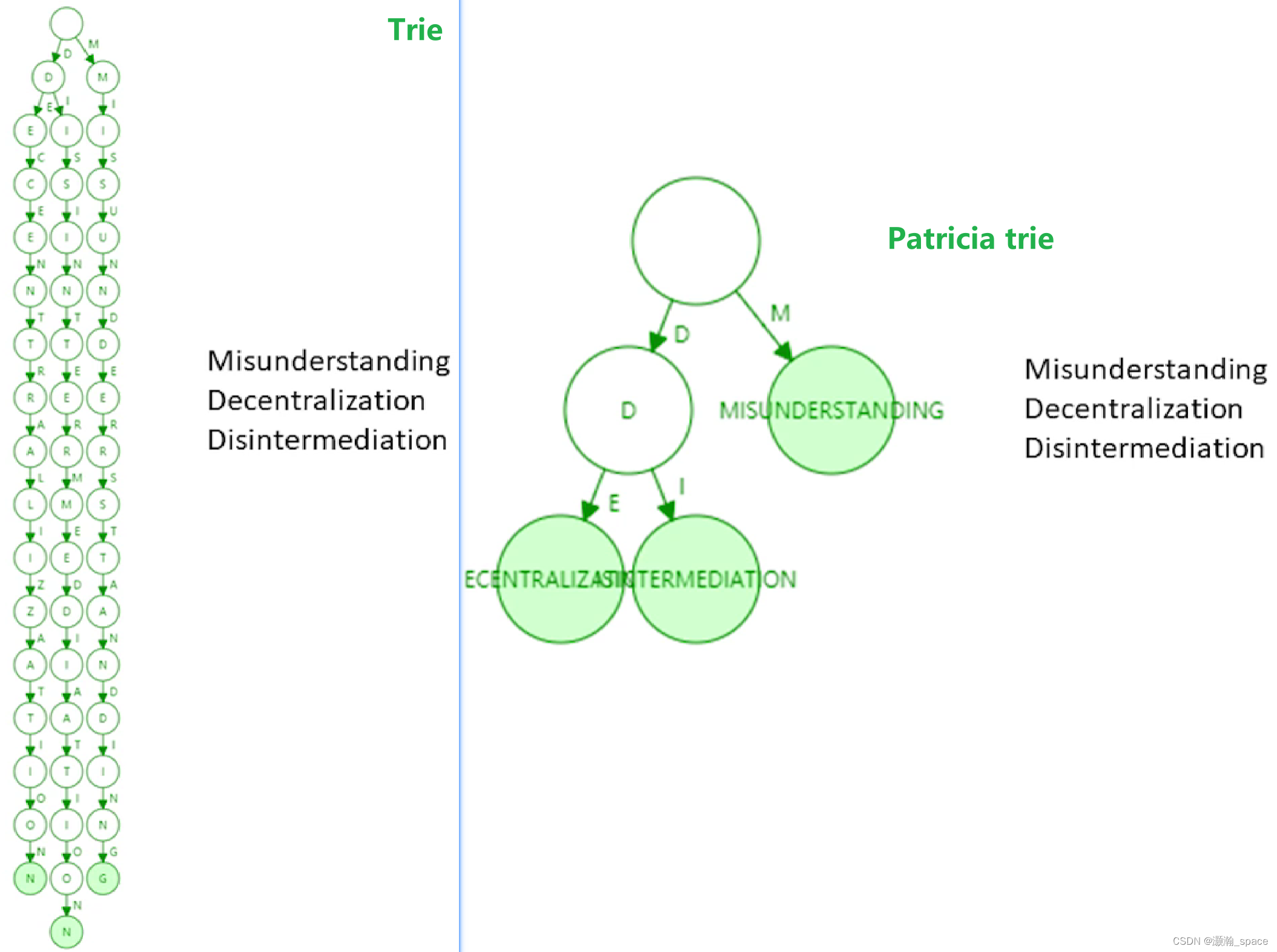
在以太坊系统中,160位的地址存在 2 160 2^{160} 2160 种,和账户数目相比,可以认为地址这一键值非常稀疏。因此,我们可以在以太坊账户管理种使用Patricia trie这一数据结构
- 为什么要设计的非常稀疏?
- 防止地址发生碰撞,也就是防止账户冲突
但实际上,在以太坊种使用的并非简单的PT(Patricia trie),而是MPT(Merkle Patricia trie)
④ MPT(Merkle Patricia trie)
Merkle tree与Binary tree区别- 区块链和普通链表的区别在于把普通指针换成了哈希指针
- 同样,
Merkle tree相比Binary tree,也是普通指针换成了哈希指针
-
block header中的根哈希值- BTC的
block header只有一个根哈希值:- 区块中的交易组成的
Merkle tree的根哈希值
- 区块中的交易组成的
- ETH的
block header中有三个根哈希值:- 交易树的根哈希值:由区块中交易组成
- 状态树的根哈希值:将所有账户组织为一个经过路径压缩和排序的
Merkle Tree - 收据树的根哈希值:后面会展开
- BTC的
-
根哈希值的用处:
- 防篡改
- 提供
Merkle proof给轻节点可以验证账户余额 - 证明某个发生了交易的账户是否存在
⑤ MMPT(Modified Merkle Patricia trie)
⑤① MMPT的图示
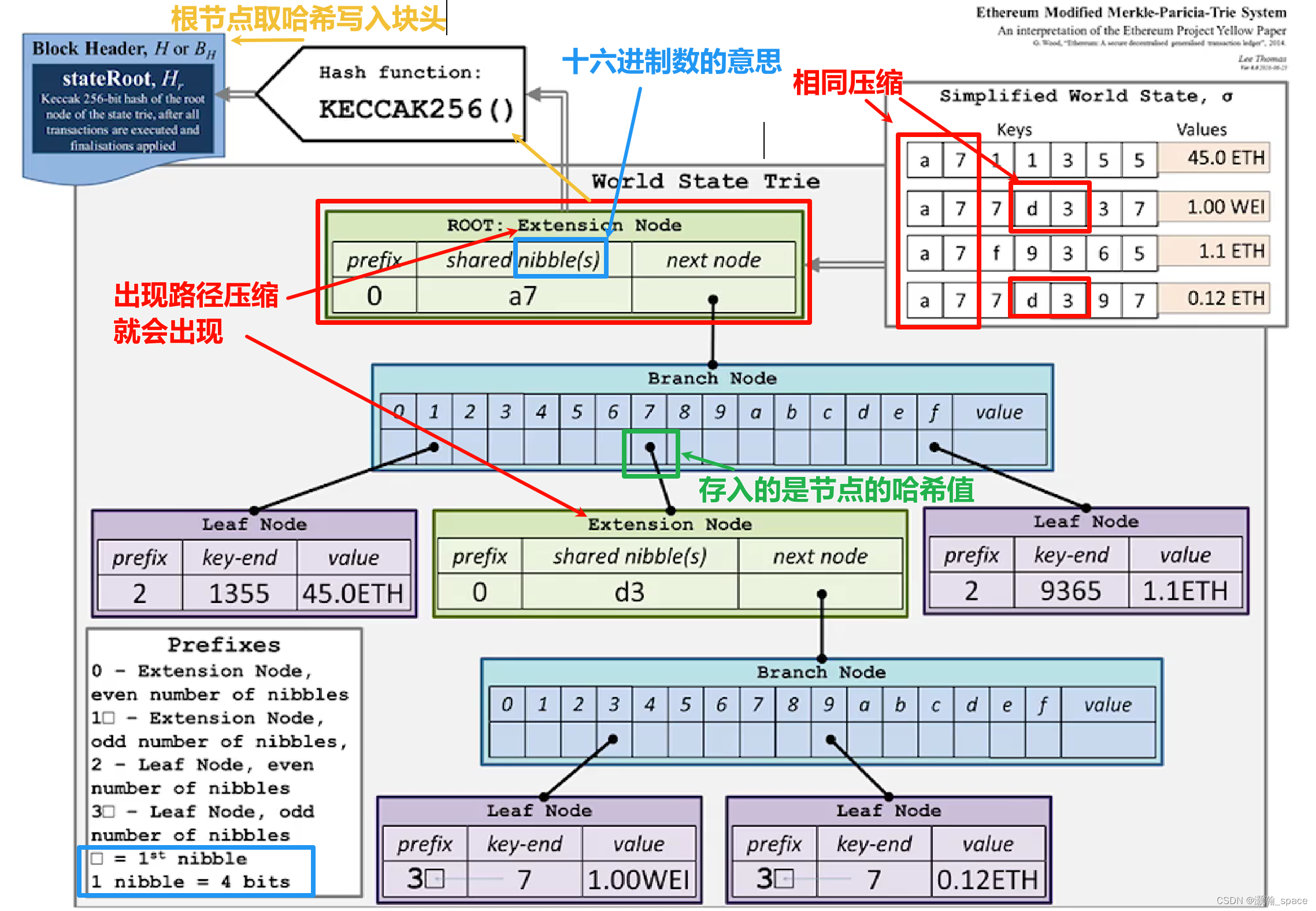
- 与普通的
Merkle Patricia trie不同在哪?Prefixes有分奇数哥和偶数个nibble
⑤② MMPT的运用
发布新区块的时候,状态树中有一些节点的值会发生变化,这些改变是在保留原来状态基础上新建分支来修改
在这里插入图片描述
- 虽然有两颗状态树,但大部分节点是共享的
- 以太坊的结构是大的MMPT包含小的MMPT,每个合约账户的存储中也是一颗MMPT
- 所以,系统中全节点并非维护一棵MPT,而是每次发布新区块都要新建MPT,只不过大部分节点共享,只有少数发生变化的节点要新建分支
- 为什么要保存原本状态?为何不直接修改?
- 便于回滚。因为以太坊支持智能合约,智能合约中的代码时很复杂的,没办法从中倒推出执行合约前的状态,所以要想支持回滚,就必须保存历史状态
⑥ 以太坊数据结构源码
⑥① block header
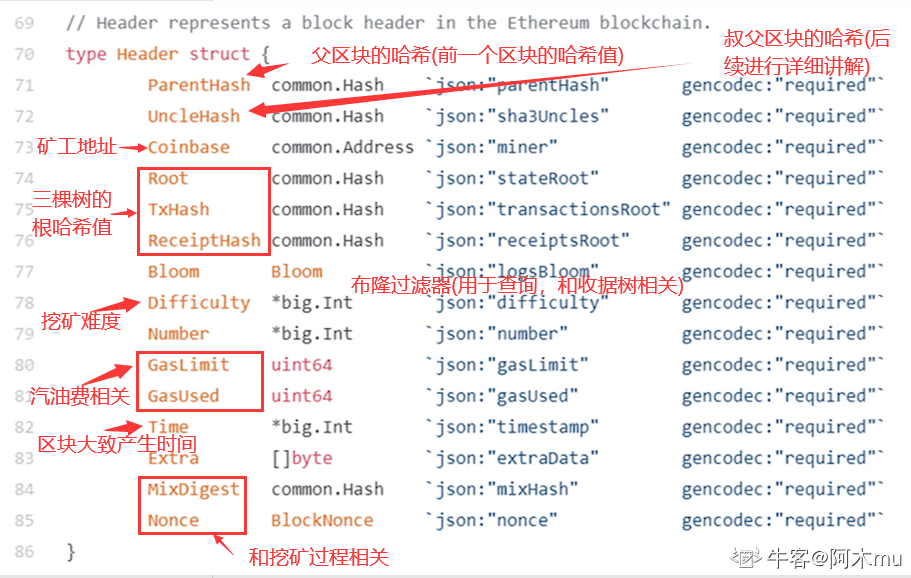
⑥② 区块结构
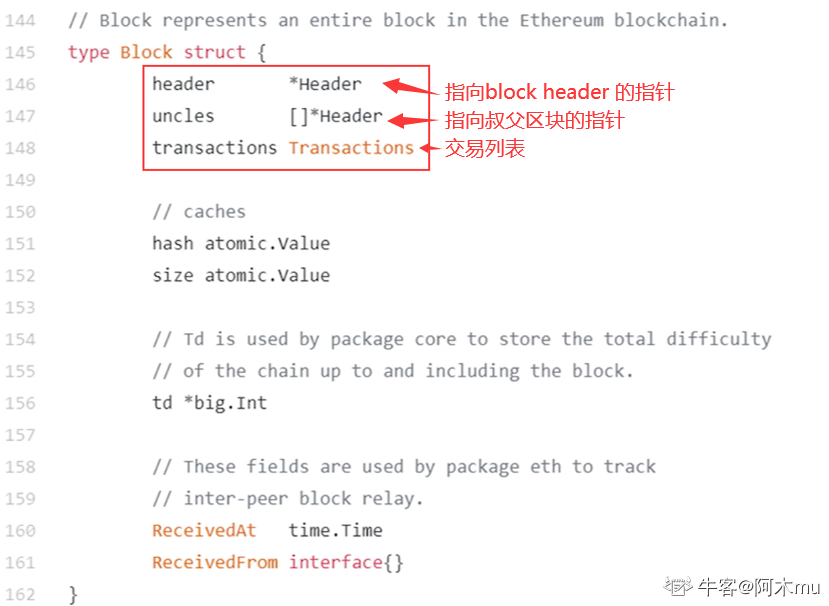
⑥③ 区块在网上真正发布时的信息

⑦ 状态树中的value
状态树中保存Key-value对,key是地址,value是状态通过RLP(Recursive Length Prefix,一种进行序列化的方法)编码序列号之后再进行存储。
以太坊的所有类型最后都要经过RLP变成字符数组(
nested array of bytes)
1️⃣7️⃣ 交易树和收据树
- 每次发布一个区块时,区块中的交易会形成一颗交易树
- 以太坊还添加了收据树,在每个交易执行完之后形成一个收据,记录交易相关信息。
- 也就是说,使交易树和收据树上的节点是一一对应的。
- 为什么要有收据树?
- 因为智能合约执行较为复杂,通过收据树,有利于快速查询执行结果。
-
以太坊中三棵树都是
Merkle Patricia trie,MPT的优点是支持查找操作,通过键值- 状态树键值与特点
- 将所有账户的状态都包含进去(无论这些账户是否与当前区块中交易有关系)
- 多个区块状态树共享节点
- 查找键值为账户地址
- 交易树和收据树键值与特点
- 只将当前区块中的交易组织起来
- 依照区块独立
- 查找键值为交易在发布的区块中的序号
- 状态树键值与特点
-
比特币只有一颗交易树,采用普通的MT(
Merkle Tree)
- 交易树和收据树的用途:
- 向轻节点提供
Merkle Proof- 交易树证明:某个交易被打包到节点中
- 收据树证明:某个交易的执行结果
- 更加复杂的查找操作,例如:查找过去十天的跟某个智能合约的交易
- 向轻节点提供
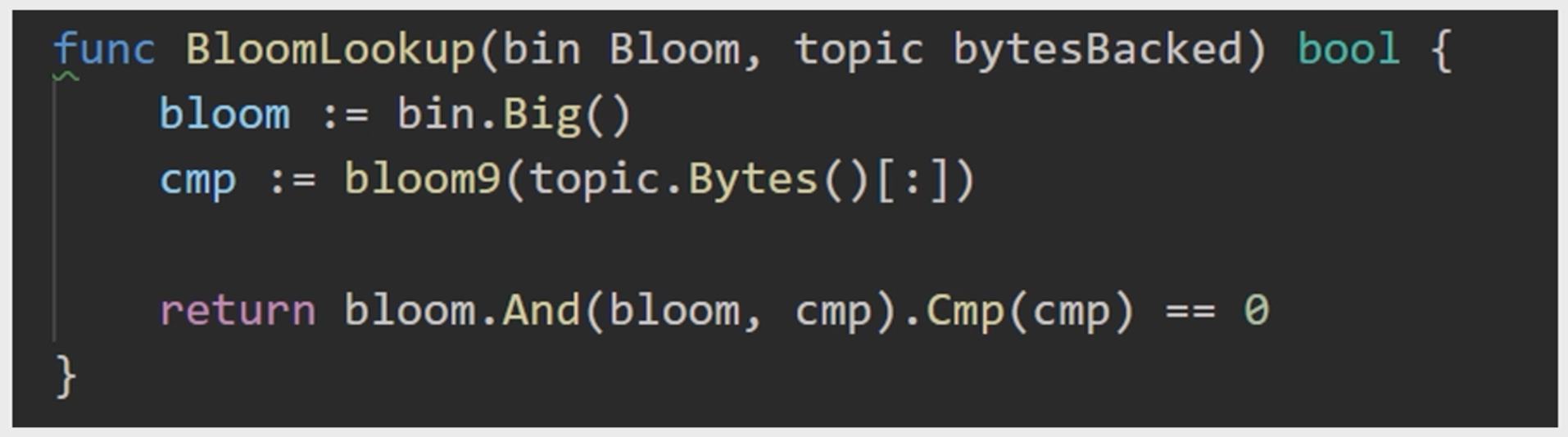
以太坊中是如何实现这复杂的查找操作呢? 答:Bloom filter(布隆过滤器)
① Bloom Filter(布隆过滤器)
布隆过滤器可以判断某个数据一定不存在,但是无法判断一定存在(可能发生互相碰撞,
false positive)
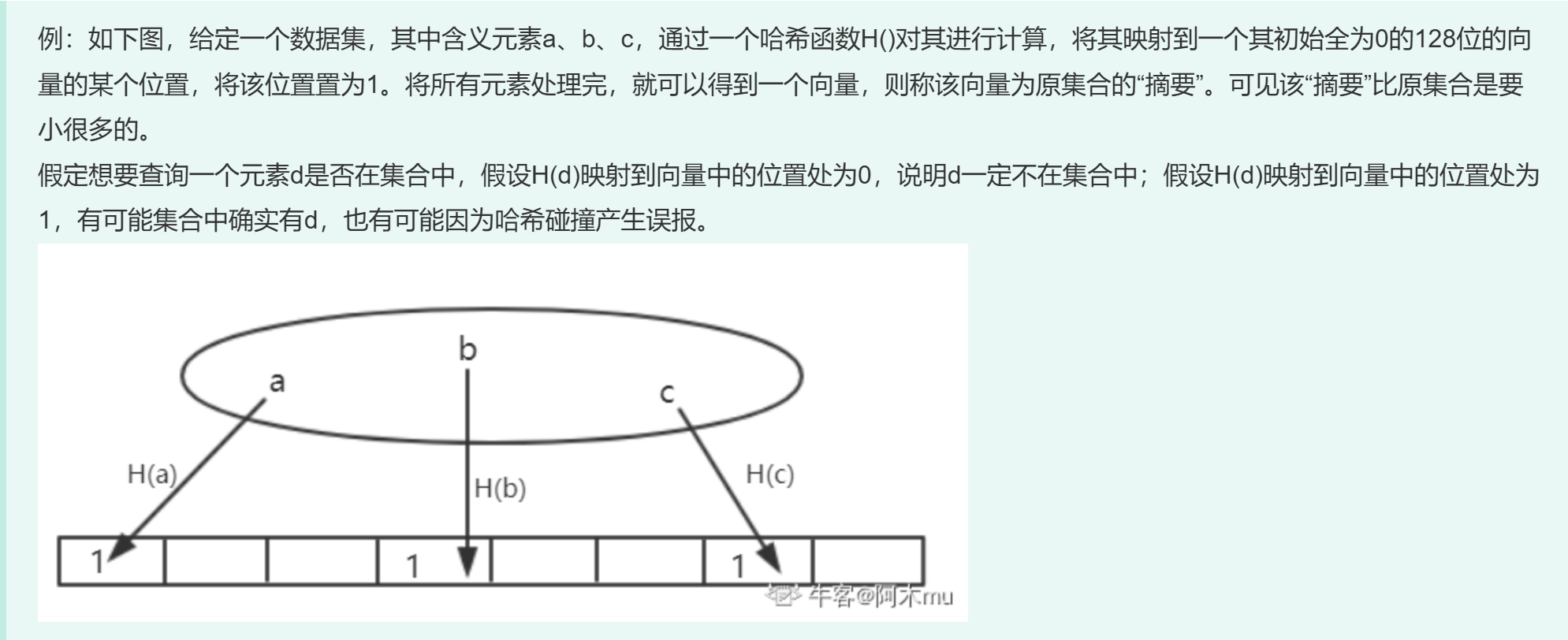
- 功能:支持较为高效查找某个元素是否在某个集合中
- 实现:计算出一个紧凑的“摘要”。将每个个元素都取哈希,找到向量中的对应位(初始化全为0),然后置为1,全部元素处理完后就得到原来集合的摘要
- 例子
- 如何删除集合中元素?
- 没法操作。也就是说,简单的Bloom filter不支持删除操作。如果想要支持删除操作,需要将记录数不能为0和1,需要修改为一个计数器来记录这个位置有多少元素映射,而且还需要考虑计数器是否会溢出。
② 以太坊中的Bloom filter
-
每个交易完成后会产生一个收据,收据中包含一个Bloom filter,用于记录交易类型、地址等信息
-
发布的区块中块头里有一个总Bloom filter,其为该区块中所有交易的Bloom filter的一个并集
-
查找时候先查找哪个区块块头中包含需要的
Bloom filter,(如果不包含,则一定不存在)如果块头中包含,再查找区块中包含的交易所对应的收据树中的Bloom filter,也就是每个收据的Bloom filter,看看哪个有,再查看交易进行确认;也可能都没有,因为可能是false positive
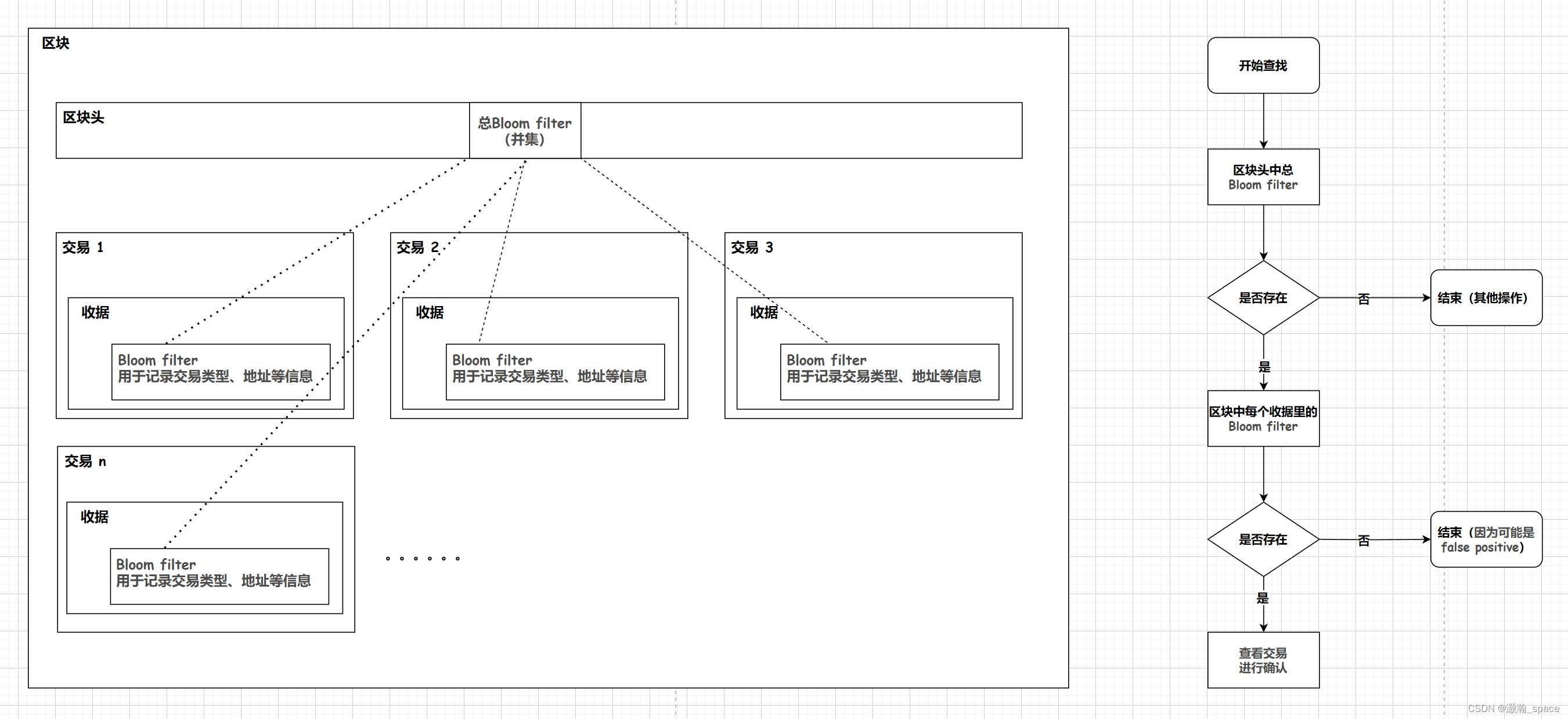
- 这样设计
Bloom filter结构的优点:- 快速大量过滤掉大量无关区块,从而提高了查找效率。(可以过滤掉很多轻节点,若想进一步确认,再向全节点请求信息)
③ 状态机
以太坊的运行过程,可以视为交易驱动的状态机(transaction-driven state machine),通过执行当前区块中包含的交易,驱动系统从当前状态转移到下一状态。当然,BTC我们也可以视为交易驱动的状态机,其状态为UTXO(用掉一些输出,又会增加一些新的输出,所以发布的区块会驱动状态机从当前的状态转移到下一个状态)。
- 状态机的共同特点:状态转移是确定性的
- 对于给定的当前状态和给定一组交易,可以确定性的转移到下一状态(保证系统一致性)。
问题1:
- 有没有可能收款账户不包含再状态树中?
- 可能
- 因为在以太坊和比特币系统中,新建的账户是不会被知道的,只有产生交易时才会被系统知道,对应在以太坊的操作是在状态树中新插入一个节点
问题2:
- 能否将每个区块中状态树改成只包含和区块中交易相关的账户状态?(这样就和交易树、收据树保持一致,可以大幅削减状态树大小)
- 不能
- 这样的设计账户状态查找不方便,因为不存在某个区块包含所有状态
- 例如,查询新建账户的状态,则需要一直找到创世纪块才能知道这个账户不存在是个新建的账户😅,而区块链是不断延长的。
④ 交易树和收据树的创建过程(代码)
NewBlock()
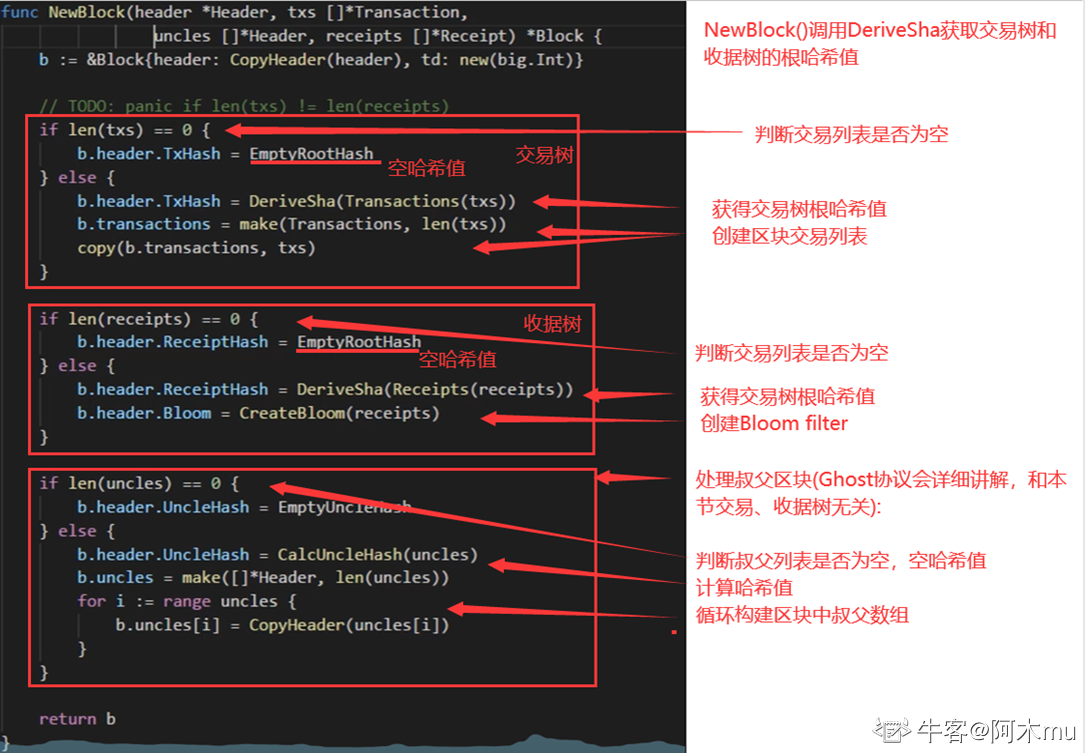
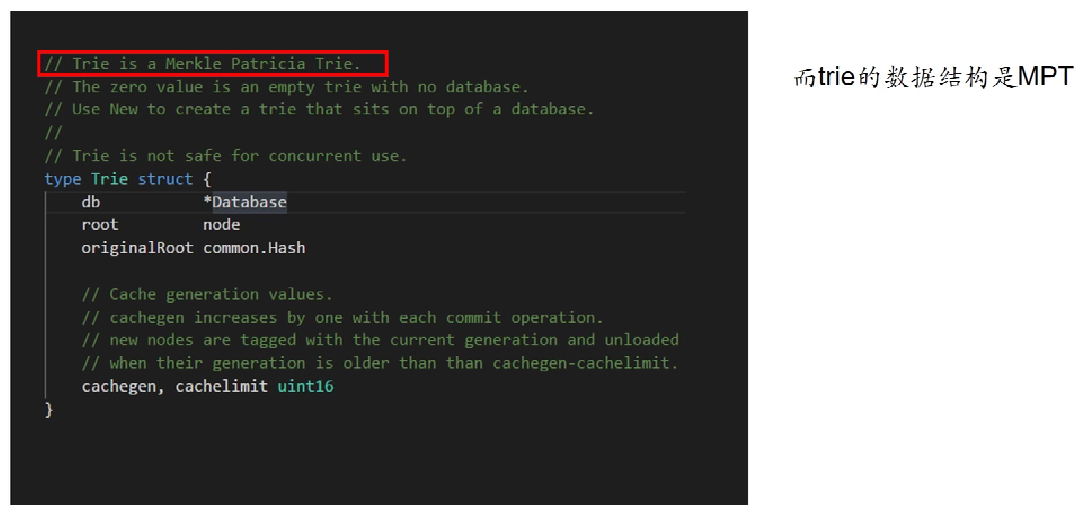
DeriveSha()

Trie struct
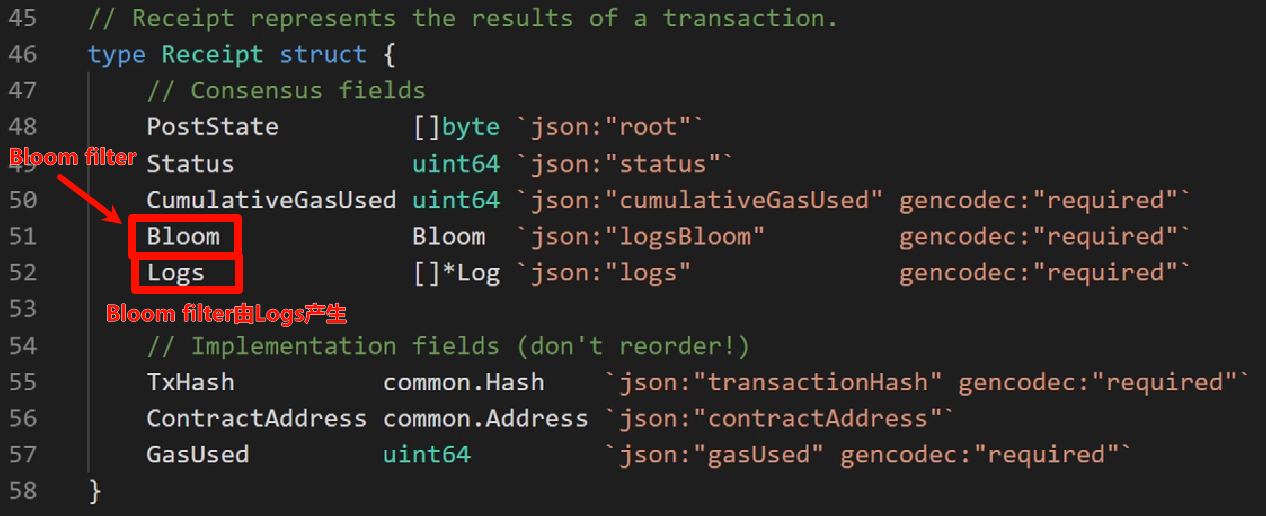
Receipt struct
+ 每个交易执行完后形成的收据
- 创建Bloom filter
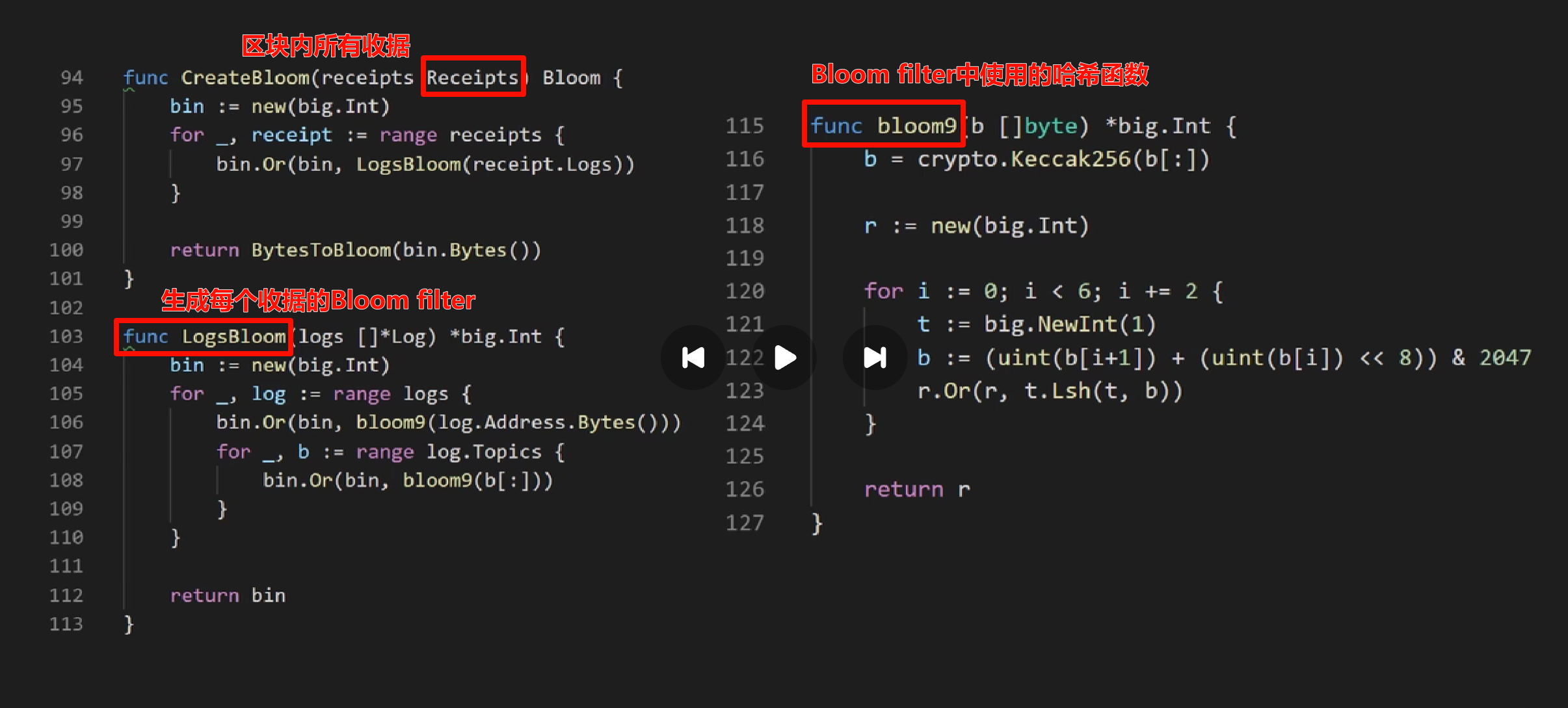
- 使用Bloom filter查询查询topic(交易类型、地址等信息)
这篇关于北京大学肖臻老师《区块链技术与应用》P16(状态树)和P17(交易树和收据树)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






