本文主要是介绍【千帆平台】使用AppBuilder零代码创建应用,Excel表格数据转为Markdown格式文本,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
欢迎来到《小5讲堂》
这是《千帆平台》系列文章,每篇文章将以博主理解的角度展开讲解。
温馨提示:博主能力有限,理解水平有限,若有不对之处望指正!

目录
- 前言
- 创建应用
- 应用名称
- 应用描述
- 应用头像
- 角色指令
- 组件能力
- 开场白
- 推荐问
- Excel表格数据
- 读取Excel文件
- 数据转为MD
- 输出效果
- MD常用格式
- 平台简介
- 总结
- 推荐文章
前言
最近在使用excel设置表格数据时,突然想放到技术博客上面。
大家都知道,Markdown表格的格式和实际效果是不一样,格式不一样,
因此就用AIGC方式自动Excel表格数据转为MD,一起来看下创建过程和实际效果。
创建应用
应用名称
Excel表格转Markdown小助手
应用描述
轻松将Excel表格数据转换为Markdown格式代码
应用头像

角色指令
由于指令也是MD格式,所以博主这里就用代码方式展示,这样就能保持MD原样。
# 角色任务
将用户提供的Excel表格数据转换为Markdown格式,并以代码方式输出。你需要具备处理Excel文件和Markdown格式数据的能力,以及编写相关代码的技能。
# 工具能力
1. Excel文件处理
能够读取和解析Excel文件,提取表格数据。
2. Markdown格式转换
将提取的Excel表格数据转换为Markdown格式。
3. 编码输出
以代码方式输出转换后的Markdown数据。
# 要求与限制
1. 准确性
确保转换的Markdown数据准确无误,保留Excel表格中的原始数据和格式。
2. 代码可读性
输出的代码应具备良好的可读性,便于用户理解和使用。
3. 无需设计界面
角色指令中禁止涉及任何界面设计,专注于背后的代码逻辑和数据处理能力。
组件能力
博主这里使用了代码解释器组件,目的是通过代码解释器的代码来对Excel文件进行解释,最后转为MD格式文本

开场白
你好!我是表格转Markdown小助手,请上传你的Excel文件,点击开始转MD
推荐问
开始转MD
Excel表格数据
读取Excel文件
import pandas as pd
import io
def read_excel(filename):excel_info = ""# 加载Excel文件df = pd.read_excel(filename)# 打印每一列的信息excel_info += f"使用pandas的DataFrame中接口打印{filename}每一列的名称及数据类型如下: \n"num_line = len(df)excel_info += f"{filename}总行数: {num_line}\n"info_str = io.StringIO()df.info(verbose=True, buf=info_str)excel_info += info_str.getvalue()# 打印数据样例excel_info += "为您展示每一列的数据样例: "for column in df.columns:excel_info += "{}: {}\n".format(column, df[column].iloc[0])# unique小于200打印可选值excel_info += "以下列的unique可选值的数量小于200: "for column in df.columns:unique_values = df[column].dropna().unique()if len(unique_values) = 2000:return excel_infoexcel_info += sreturn excel_info# 读取excel文件信息
excel_info = read_excel(filename="表格转MD.xlsx")
print(excel_info)
数据转为MD
import pandas as pd# 读取Excel文件
file_path = '表格转MD.xlsx'
df = pd.read_excel(file_path)# 将DataFrame保存为Markdown格式
markdown_file_path = '表格转MD.md'
df.to_markdown(markdown_file_path, index=False)# 打印转换后的Markdown数据
with open(markdown_file_path, 'r') as file:markdown_data = file.read()
print(markdown_data)
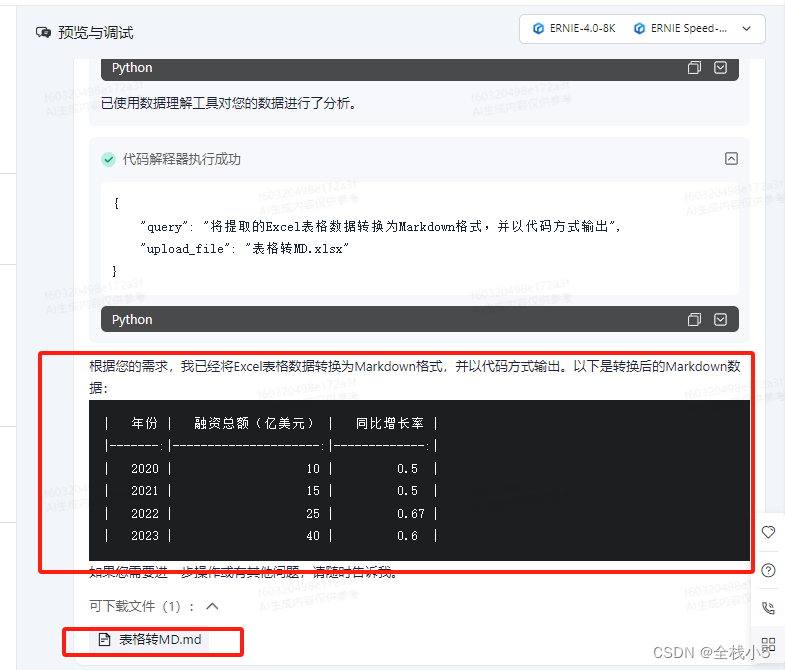
输出效果
总共执行了两次代码,一次是读取excel数据,一次是数据转为MD。
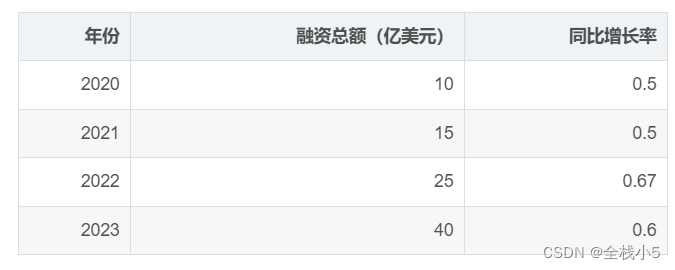
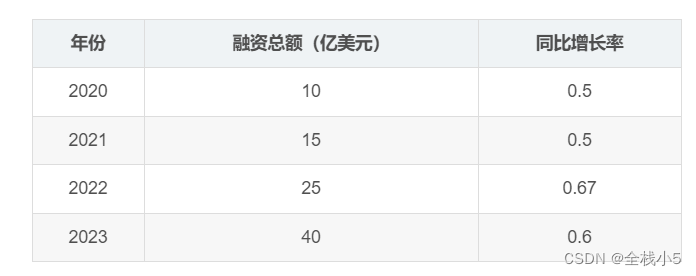
下面格式的冒号在右边,是指右对齐的意思,在左边就是左对齐的意思,去掉默认就是居中对齐。
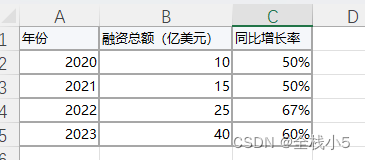
| 年份 | 融资总额(亿美元) | 同比增长率 |
|-------:|---------------------:|-------------:|
| 2020 | 10 | 0.5 |
| 2021 | 15 | 0.5 |
| 2022 | 25 | 0.67 |
| 2023 | 40 | 0.6 |
- 右对齐
- 居中对齐
MD常用格式
Markdown列举常用格式如下:
1.无序列表:使用-、+或*开头,例如:
- 苹果
- 香蕉
- 橙子
- 苹果
- 香蕉
- 橙子
2.有序列表:使用数字加.开头,例如:
1. 第一步
2. 第二步
3. 第三步
- 第一步
- 第二步
- 第三步
3.任务列表:在无序列表前添加[]或[x],例如:
- [ ] 完成任务1
- [x] 完成任务2
- 完成任务1
- 完成任务2
4.代码块:使用三个反引号```开头和结尾,例如:
```python
def hello_world():print("Hello, world!")
def hello_world():print("Hello, world!")
5.链接:CSDN
使用[文本](链接地址)格式,例如:
[CSDN](https://www.csdn.net/)
这些只是Markdown的一些常用格式,实际上Markdown还支持更多高级功能和语法。
平台简介
千帆平台AppBuilder是基于大模型搭建AI原生应用的工作台,提供RAG、Agent、GBI等应用框架,文档问答、表格问答、对话、创作等应用组件,以及文生图、语音等传统AI组件,分别以低代码态、代码态的产品形态面向不同开发能力的用户和开发场景。
千帆平台还有Modelbuilder,一站式大模型开发及服务运行平台。千帆不仅提供了包括文心一言底层模型和第三方开源大模型,还提供了各种AI开发工具和整套开发环境,轻松使用和开发大模型应用。
支持数据管理、自动化模型SFT以及推理服务云端部署的一站式大模型定制服务
百度千帆平台是百度AI开发的大模型一站式平台,集成了多种大模型,包括语言模型、图像模型、语音模型和跨模态模型等。以下是关于百度千帆平台的详细介绍:
1.功能特点:
- 多模态能力:百度千帆平台集成了多种模态的能力,如语言、图像、语音和跨模态等,能够满足不同领域的应用需求。
- 丰富的预训练模型:平台提供了多种预训练模型,包括通用模型、领域模型和场景模型等,企业可以根据自身需求选择合适的模型进行微调和优化,以提高模型的准确性和效率。
- 全方位NLP解决方案:百度千帆平台支持语言理解、语言生成、文本分类、情感分析、文本相似度分析、翻译功能以及语音生成等多种NLP功能,为企业提供全方位的解决方案。
2.主要应用:
- 提高企业效率:通过使用百度千帆平台,企业可以快速构建高效的AI应用,提高业务流程的自动化水平和效率。例如,在金融领域,利用该平台可以快速构建智能客服、风险控制和投资分析等应用。
- 跨语言沟通:在跨语言沟通场景下,百度千帆平台的翻译功能可以帮助人们快速顺畅地交流,打破语言障碍。
- 文本创作与写作:平台还支持文本类创作和写作,为内容创作者提供强大的工具支持。
3.使用方法:
- 数据导入:在百度千帆平台上,用户首先需要导入数据。通过选择“数据服务 > 数据集管理”,用户可以创建数据集并上传无标注文件或链接内容。
- 数据标注:在导入数据后,用户可以对数据进行标注。平台提供了自动生成回答或手动生成回答的选项,用户可以根据需求选择。标注好的文本数据将在“有标注信息”页签下展示。
- 模型训练与发布:在数据标注完成后,用户可以配置训练参数并选择合适的模型进行训练。训练完成后,用户可以将模型发布为服务,供其他人或系统调用。
- 在线测试:发布服务后,用户可以在线测试模型的性能,并根据测试结果进行调整和优化。
总之,百度千帆平台是一个功能强大、易于使用的大模型一站式平台,能够帮助企业快速构建AI应用并提高业务效率。无论是NLP功能、跨语言沟通还是文本创作与写作等应用场景,百度千帆平台都能提供强大的支持。
总结
总体体验下来输出的效果还是非常不错的,基本能够实现想要的功能效果。
推荐文章
【千帆平台】使用AppBuilder零代码创建应用,Excel表格数据转为Markdown格式文本
【千帆平台】AppBuilder工作流编排新功能体验之创建自定义组件
【千帆平台】AppBuildert工作流编排新功能体验之创建自定义组件
【千帆平台】使用AppBuilder三步手搓应用创建精准多轮对话agent之K12互动式练习题
【千帆平台】百度智能云千帆AppBuilder应用探索益智游戏之猜物小游戏
【人工智能】百度智能云千帆AppBuilder,快速构建您的专属AI原生应用
【人工智能】千帆平台创建和使用我的数据集,为什么需要数据集,有什么作用
【千帆平台】使用千帆大模型平台创建自定义模型调用API,贺岁灵感模型,文本对话
这篇关于【千帆平台】使用AppBuilder零代码创建应用,Excel表格数据转为Markdown格式文本的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






