本文主要是介绍Store buffer 解决CPU的停滞(stall)状态,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Store buffer的引入主要是为了解决CPU在执行写操作时可能遇到的性能问题。具体来说,当CPU需要将数据写入到内存或AXIM总线时,如果直接进行写操作,CPU可能需要等待写操作完成才能继续执行其他指令,这会导致CPU的停滞(stall)状态,并浪费大量的时间。
为了提高性能,引入了Store buffer。Store buffer允许CPU将数据先写入到store buffer中,而无需等待写操作真正完成。这样,CPU可以继续执行其他指令,而不需要等待写操作的完成。等到CPU收到了ack消息(表示写操作已经被成功处理)后,再从store buffer中将数据写入到local cache中。
Store buffer的引入显著提高了CPU的性能,因为它减少了CPU的等待时间,使CPU能够更高效地利用计算资源。然而,store buffer也引入了一些新的问题,如读写乱序和数据一致性问题。为了解决这些问题,处理器和操作系统通常采用一些机制来确保内存访问的一致性和顺序性,如MESI协议和内存屏障等。
总之,Store buffer的引入是为了提高CPU的性能,允许CPU在等待写操作完成期间继续执行其他指令。然而,它也带来了一些挑战,需要其他机制来确保内存访问的一致性和顺序性。
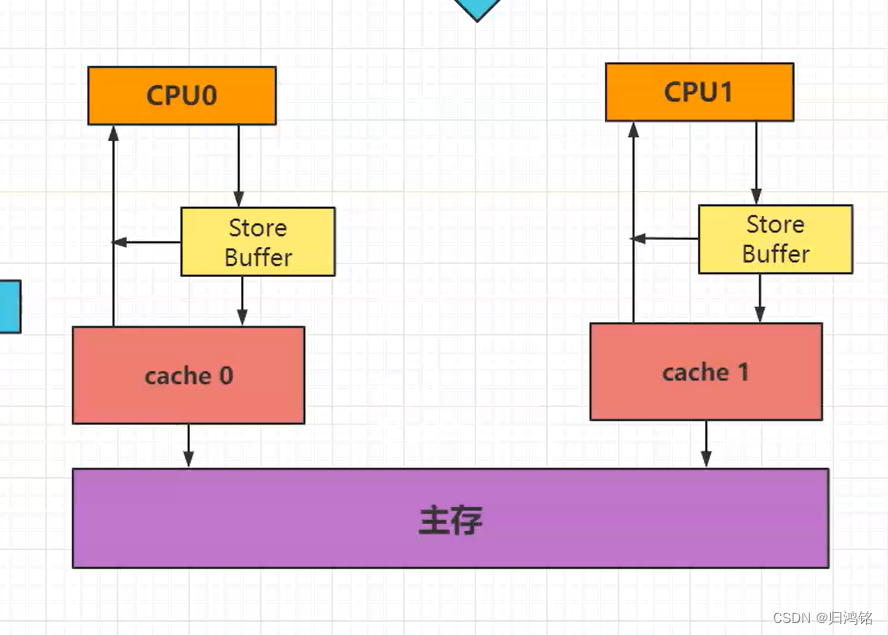
Store buffer 为什么会导致读写乱序
Store buffer导致读写乱序的原因主要是因为它允许处理器先将写操作的数据暂存于store buffer中,而不是直接写入主存,然后处理器可以继续执行其他操作,而无需等待写操作真正完成。这种机制可以提高处理器的性能,因为它减少了处理器等待写操作完成的时间。
然而,这种异步写入的机制也带来了读写乱序的问题。具体来说,当一个处理器(如CPU1)修改了某个内存位置的值,并将这个修改暂存于store buffer中时,其他处理器(如CPU2)可能还没有看到这个修改,因为它们访问的是主存中的旧值。此时,如果CPU2读取这个内存位置的值并进行计算,它得到的结果可能是基于旧的数据,而不是CPU1刚刚写入的新数据。
此外,由于store buffer的存在,写操作的顺序也可能被打乱。例如,CPU1可能先执行了一个写操作A,然后执行了一个写操作B,但是由于写操作B的数据先被放入store buffer并随后被刷新到主存,而写操作A的数据还在store buffer中等待,所以其他处理器看到的写操作顺序可能是B-A,而不是A-B。
为了解决这个问题,处理器和操作系统通常会采用一些机制来确保内存访问的一致性,如MESI协议(缓存一致性协议)和内存屏障(memory barrier)。MESI协议通过维护缓存行状态来确保多个处理器之间的缓存一致性,而内存屏障则是一种同步原语,它可以确保在屏障之前的所有写操作都被提交到内存,并且任何后续的读或写操作都将在屏障之后执行。这些机制可以帮助减少读写乱序的可能性,但并不能完全消除它。因此,在编写并发程序时,程序员仍然需要仔细考虑数据访问的顺序和同步问题。
指令重排的发生是因为Store buffer 的存在吗
指令重排的发生并不完全是因为Store buffer的存在,但Store buffer确实与指令重排有一定的关联。
指令重排是计算机编译器和处理器为了提高程序的性能和并行度而采用的一种优化技术。处理器和编译器可以根据数据依赖性和写后读原则来对指令进行优化,重新排列指令的执行顺序。这种优化可以提高指令的执行效率,充分利用处理器的流水线和缓存机制。
而Store buffer是处理器中的一个组件,用于暂时存储写操作的数据,直到这些数据可以被写入内存或AXIM总线。Store buffer的存在可以允许处理器继续执行其他指令,而不需要等待写操作真正完成,从而提高了处理器的性能。
然而,Store buffer也可能导致指令重排的问题。在多线程环境下,当一个线程将一个变量的值写入Store buffer后,其他线程可能立即读取这个变量的值,但由于Store buffer的异步性,这个读取操作可能会得到旧的值,而不是新写入的值。这就造成了数据的不一致性和未定义行为,类似于指令重排导致的问题。
因此,虽然指令重排的发生不完全是因为Store buffer的存在,但Store buffer的异步性确实可能导致类似于指令重排的问题。为了解决这个问题,处理器和操作系统通常会采用一些机制来确保内存访问的一致性和顺序性,如MESI协议和内存屏障等。
这篇关于Store buffer 解决CPU的停滞(stall)状态的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








