本文主要是介绍Skywalking数据持久化与自定义链路追踪,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
学习本篇文章之前首先要了解一下Sky walking的基础知识
分布式链路追踪工具Skywalking详解
一,Sky walking数据持久化
Sky walking提供了es,MySQL等数据持久化方案,默认使用h2基于内存的数据库,重启之后数据即会丢失。
在实际工作场景中,更多选择es作为sky walking的存储方案。配置如下
提前准备好es节点,在sky walking服务端的config/application.yml文件中找到storage配置项,配置elasticsearch
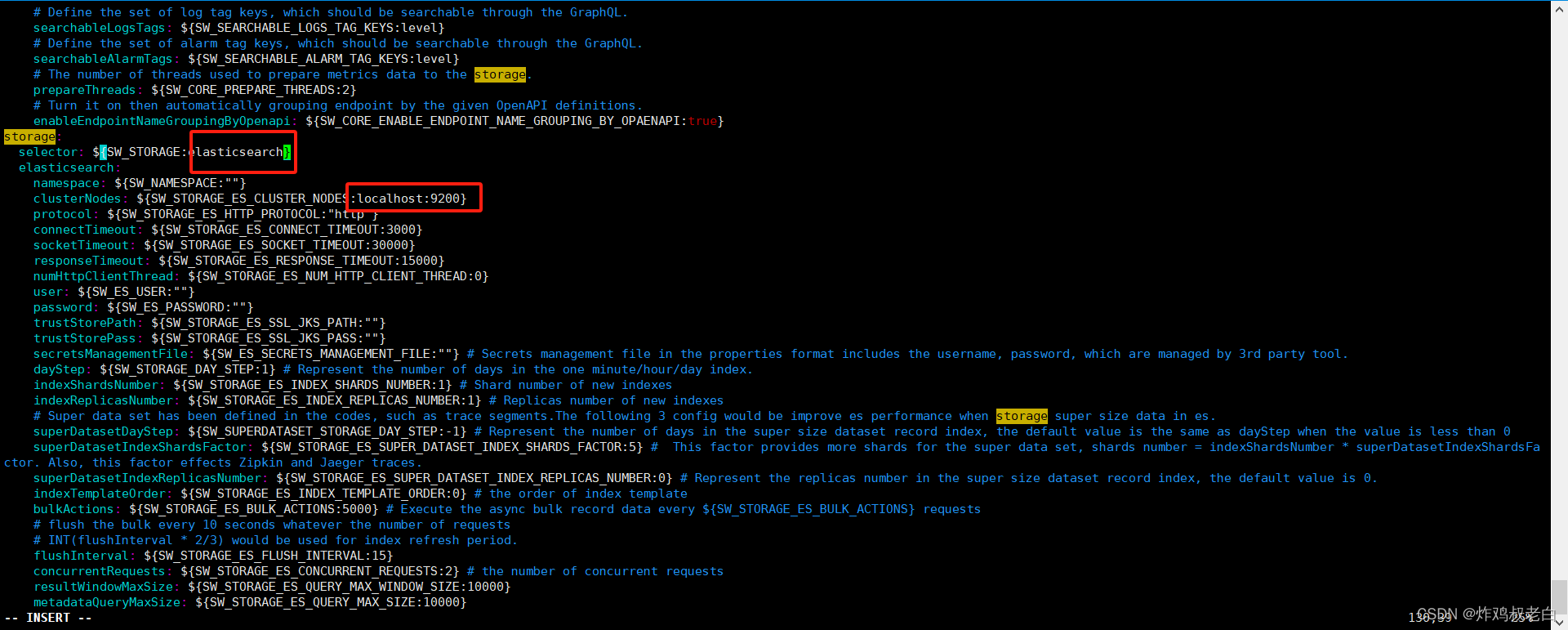
重启Sky walking即可。
二,自定义链路追踪【注解方式】
Sky walking默认的追踪粒度只到服务级别,粒度不够小。如果一个请求只在当前服务中完成,且这个请求的过程调用该服务中很多个接口。
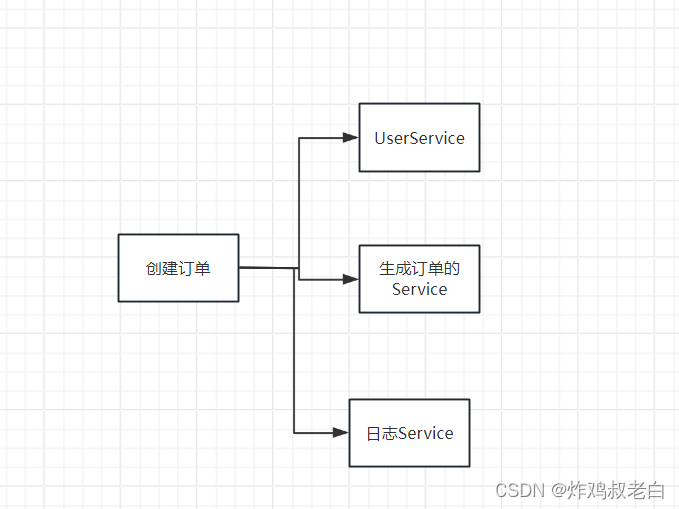
他们是在同一个服务中,为了在追踪到这些同一个服务中的Service,就需要我们自定义追踪
引入依赖
<dependency><groupId>org.apache.skywalking</groupId><artifactId>apm-toolkit-trace</artifactId><version>8.14.0</version></dependency>
编写trace接口
@Autowiredprivate TraceService traceService;@GetMapping("/trace")public String trace() {// 往追踪上下文中绑定key/value值Optional<String> s = TraceContext.putCorrelation("name", "xiaoliu");log.info("【自定义追踪测试】存储标签信息:{}",s.orElse(null));traceService.placeOrder("123");return "success";}
traceServiceImpl类的实现
@Trace(operationName = "PLACE_ORDER")@Tag(key = "productId",value = "arg[0]")@Overridepublic void placeOrder(String id) {log.info("准备创建订单:{}",id);String orderNo = this.generateOrderNo();log.info("生成订单编号:{}",orderNo);try {TimeUnit.MILLISECONDS.sleep(200L);} catch (InterruptedException e) {e.printStackTrace();}String user = this.findByUserId(1);log.info("查询用户信息:{}",user);}@Overridepublic void traceex() {this.check();RestTemplate restTemplate = new RestTemplate();String url = "http://localhost:8086/getUserById";String str = restTemplate.getForObject(url, String.class);System.out.println(str);}private void check() {if (1==3) {log.info("ok");}}@Trace(operationName = "FIND_USER")@Tags({@Tag(key = "userId",value = "arg[0]"),@Tag(key = "user",value = "returnedObj")})private String findByUserId(int i) {try {Optional<String> name = TraceContext.getCorrelation("name");log.info("name:{}",name.orElse("aaaa"));TimeUnit.SECONDS.sleep(1L);} catch (InterruptedException e) {e.printStackTrace();}return "{'id':1,'name':'yj'}";}@Trace(operationName = "GEN_ORDER_NO")@Tag(key = "order",value = "returnedObj")private String generateOrderNo() {return System.currentTimeMillis() + "";}
发送请求 http://localhost:8085/trace
查看Sky walkingUI界面
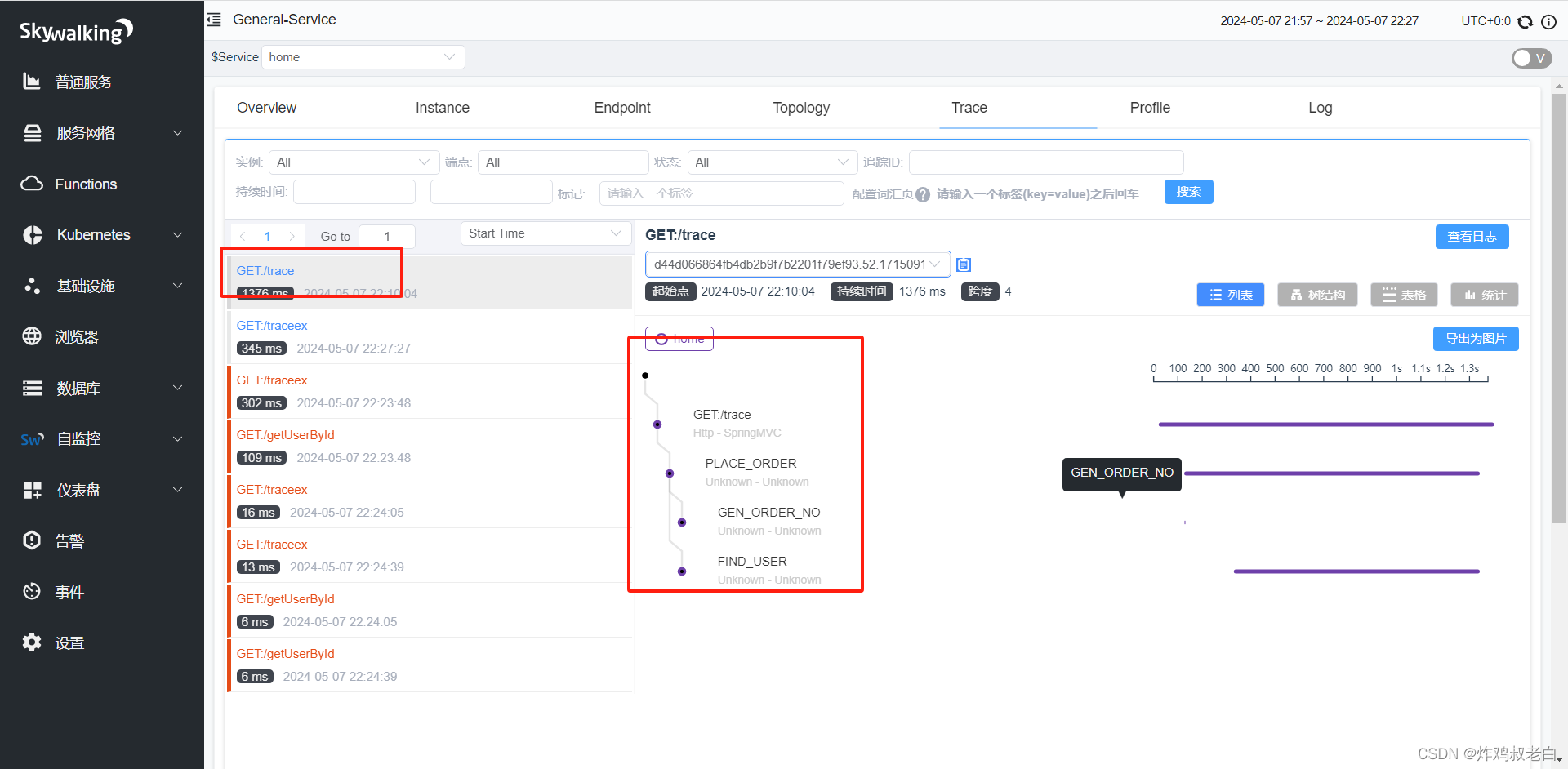
可以监控到同一个服务的其他Service
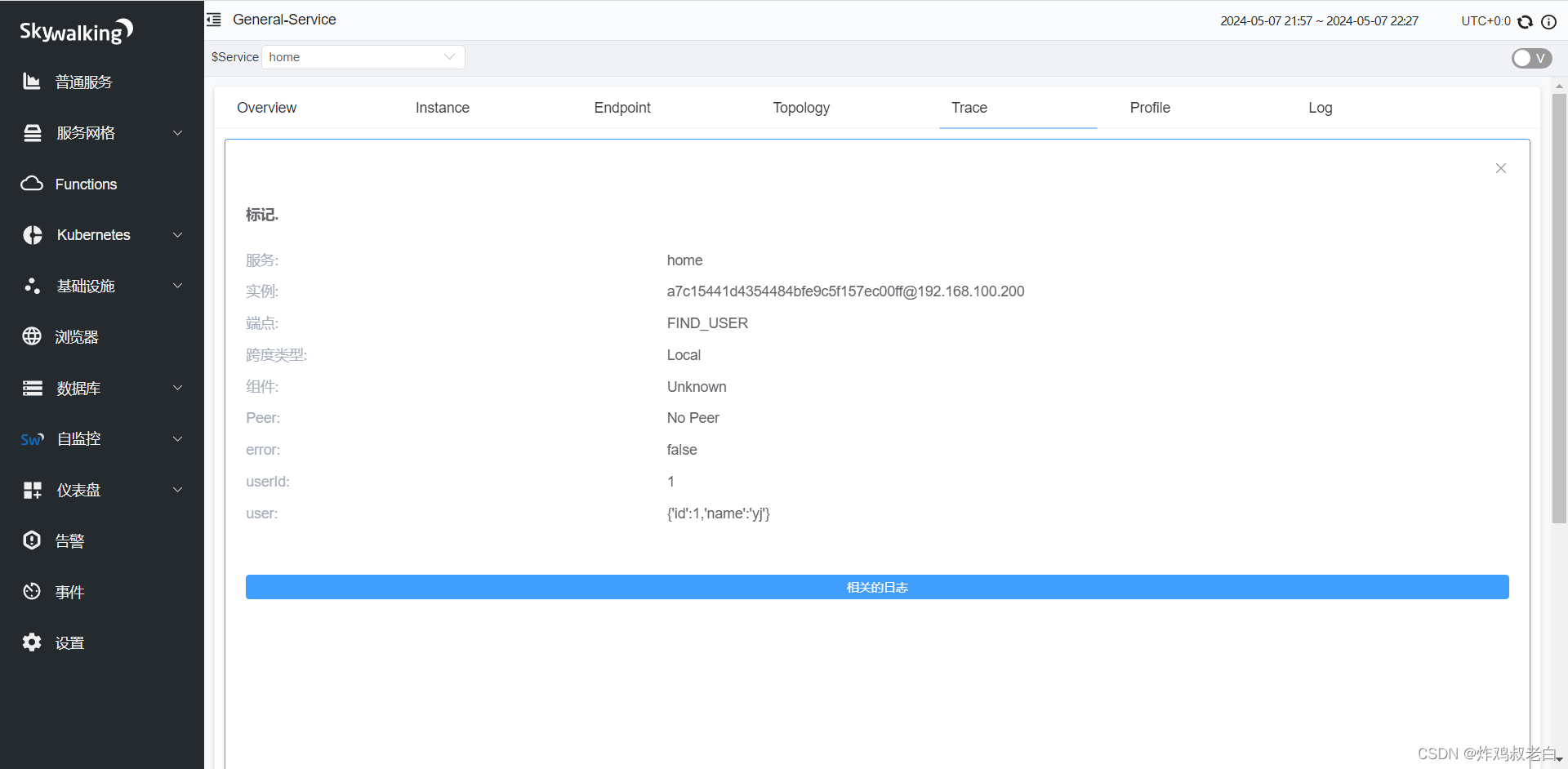
还可以查看相关的日志信息
这篇关于Skywalking数据持久化与自定义链路追踪的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





