本文主要是介绍ubuntu20部署3d高斯,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
3d高斯的链接:https://github.com/graphdeco-inria/gaussian-splatting
系统环境
ubuntu20的系统环境,打算只运行训练的代码,而不去进行麻烦的可视化,可视化直接在windows上用他们预编译好的exe去可视化。(因为看的很多人说在ubuntu上去安装这个可视化的程序,有点麻烦,cmake版本要改到最新,还有一些其他的操作,所以既然有简单的方法就不想在ubuntu上折腾,毕竟我的ubuntu主要开发ros程序,环境搞崩了就还要自己再重装)
安装cuda
之前在跑nerf的时候,我安装的是cuda11.6,但是github上说他们用的是cuda11.8,所以我这里再装一个cuda11.8.
cuda11.8的下载地址,直接下的是runfile的。(注意不要去用wget下载,很有可能在进度99%的时候失败,直接将http链接复制到浏览器上,用浏览器下载,不会出问题)
- 给下载好的文件加权限
sudo chmod +x cuda_11.8.0_520.61.05_linux.run
- 运行这个cuda文件
sudo sh cuda_11.8.0_520.61.05_linux.run
运行这个指令后需要注意,要等一阵,终端才会进入安装画面:
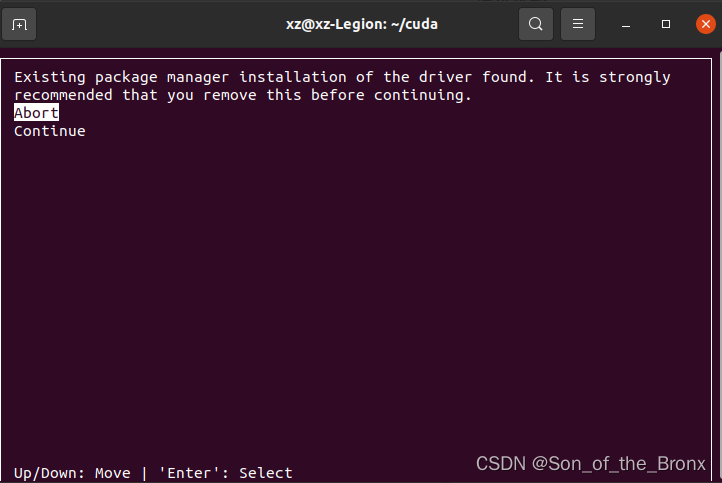
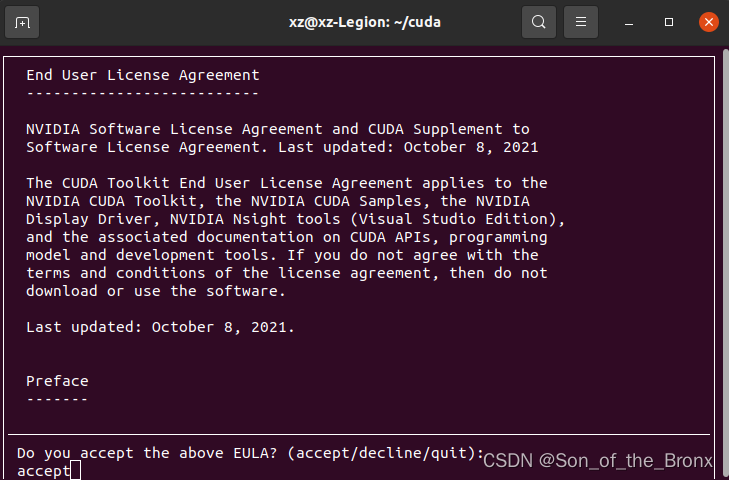
选择continue后,输入accept
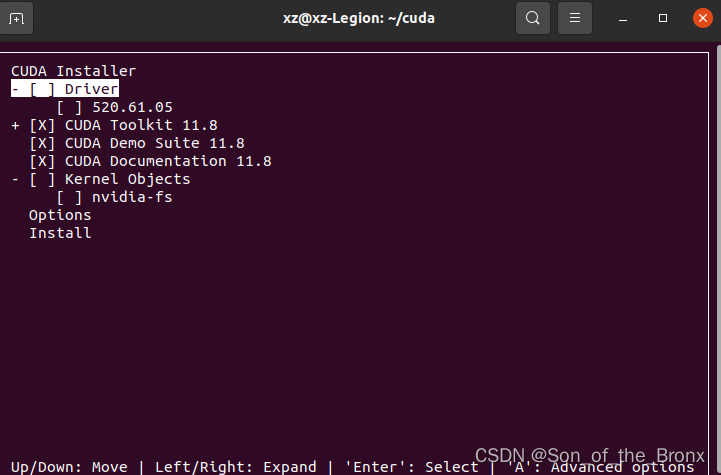
把这个驱动包的驱动按空格取消安装,即用本来安装好的显卡驱动
然后选install,出现下面的画面,因为之前有一个11.6cuda,这里他检测到了有cuda,想要更新,这里选no,否则应该会覆盖安装。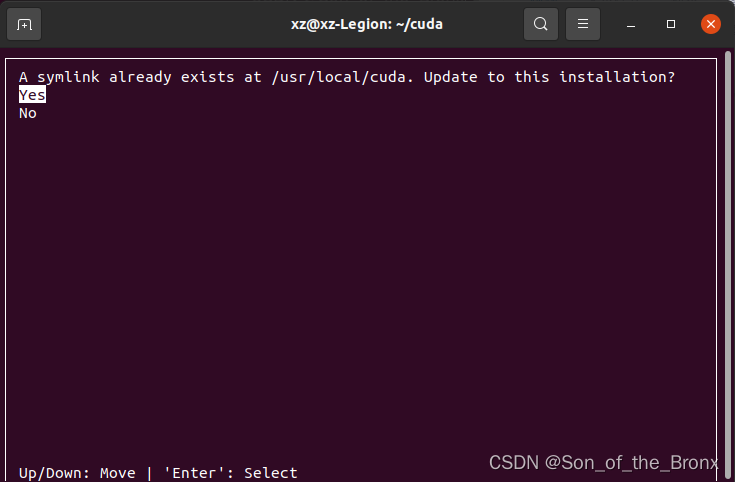
然后就是等待安装的过程,安装完成后终端会有显示:
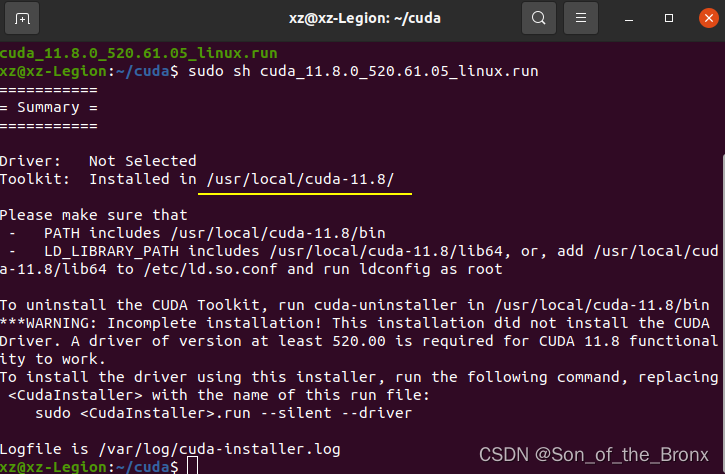
注意这里的安装目录是==“/usr/local/cuda-11.8/”==
- 修改环境变量
目前在/usr/local的文件是这样的:
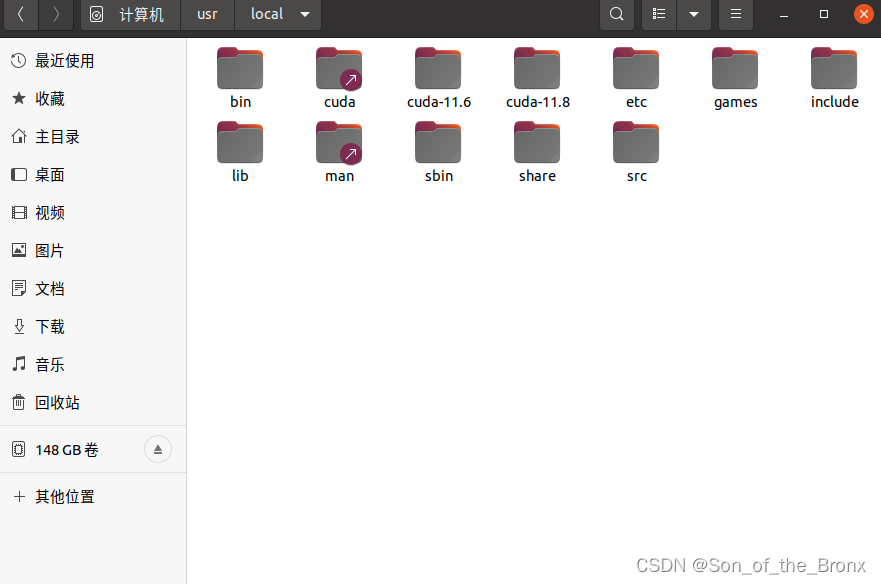
注意这时候这个cuda是一个软链接,直接无视也可以,通过下面指令打开配置文件
sudo gedit ~/.bashrc
然后在cuda相关的部分改成下面的形式:
# cuda11.6
#export PATH=$PATH:/usr/local/cuda-11.6/bin
#export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-11.6/lib64
#export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/cuda-11.6/lib64# cuda11.8
export PATH=$PATH:/usr/local/cuda-11.8/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-11.8/lib64
export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/cuda-11.8/lib64
更新配置
source ~/.bashrc
当你去使用11.8的时候,就将11.6的注释掉,用11.6的就把11.8的注释掉。
- 切换版本并且验证
nvcc --version

结果是11.8,代表切换成功了。
配置cudnn
直接用的是之前下载的cudnn8.4.1 for cuda11.x,应该对cuda11.8也是适用的。
下载的链接:https://developer.nvidia.com/rdp/cudnn-archive
推荐中文链接:https://developer.nvidia.cn/rdp/cudnn-archive
这里我选择的是cudnn8.4.1 for cuda 11.x的tar版本
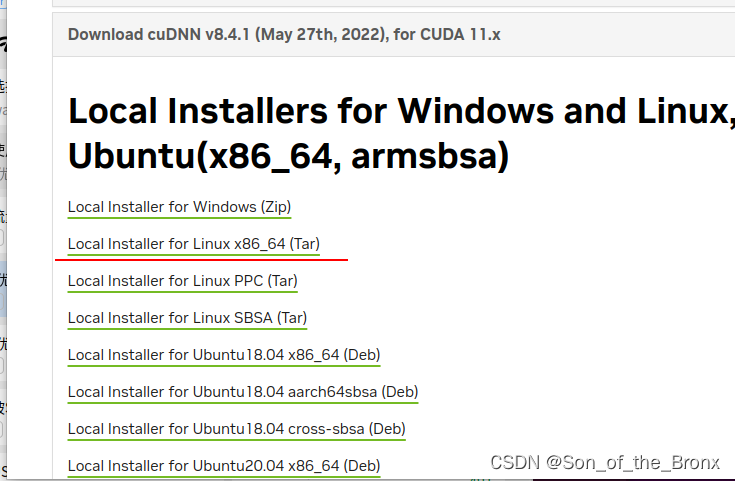
- 下载完后进行解压:并且将对应的库和头文件移到cuda11.8目录中,反正需要注意的就是cuda11.8的路径。
tar -xvf cudnn-linux-x86_64-8.x.x.x_cudaX.Y-archive.tar.xzsudo cp cudnn-*-archive/include/cudnn*.h /usr/local/cuda-11.8/include sudo cp -P cudnn-*-archive/lib/libcudnn* /usr/local/cuda-11.8/lib64 sudo chmod a+r /usr/local/cuda-11.8/include/cudnn*.h /usr/local/cuda-11.8/lib64/libcudnn*
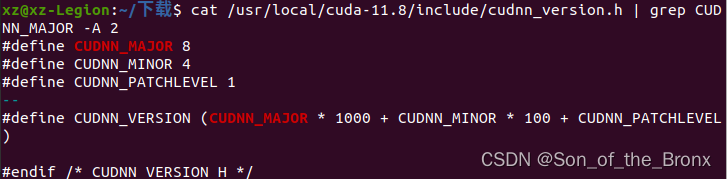
- 检查cudnn
cat /usr/local/cuda-11.8/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
创建一个3d高斯的conda环境
- 首先就是创建目录下载Gaussian Splatting的源码,记得加==–recursive==
mkdir ~/code/3DGS/gaussian-splatting/gaussian-splatting
cd ~/code/3DGS/gaussian-splatting/gaussian-splatting
git clone https://github.com/graphdeco-inria/gaussian-splatting --recursive
- 创建conda环境
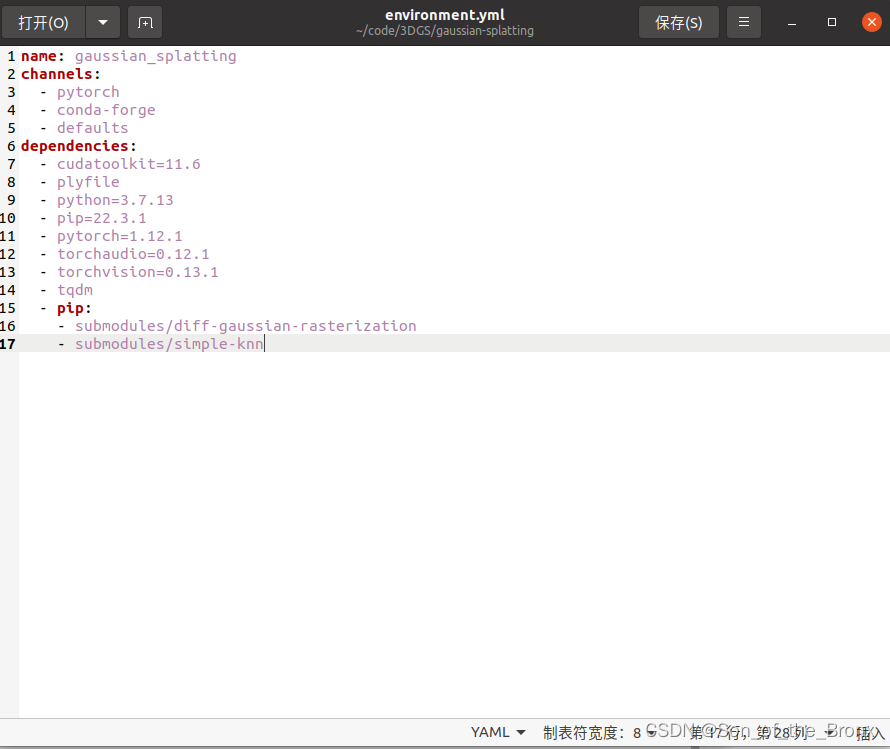
直接根据他们github上的conda配置文件去创建(注意conda我在之前安装之后,就换成了清华源,pip也是换成清华源)
conda env create --file environment.yml
conda activate gaussian_splatting
然后就是漫长的等待,安装完成没有报错(ps:我也不敢相信,为啥我安装的是cuda11.8版本,而他environment.yml里安装的是11.6的cudatoolkit,这是为什么??而且pytorch 1.12.1版本也没有支持11.8,黑人问号?而且深度学习这方面接触的少,按我的理解,一般是根据cuda版本去选择支持这个cuda版本的pytorch,所以也不太理解这是为什么)
3D高斯训练过程
训练的数据集先用他们提供的数据集:从github中的链接进行下载
有四个场景,两个室内两个室外,我先选择火车头来进行训练。目录就需要设置自己下载好的目录
python train.py -s /home/xz/dataset/3DGS/tandt/train
训练的过程也没有报错,整个训练过程13分钟,显卡是3090。还是不懂为什么cuda和pytorch版本不对应,训练的过程也没有报错。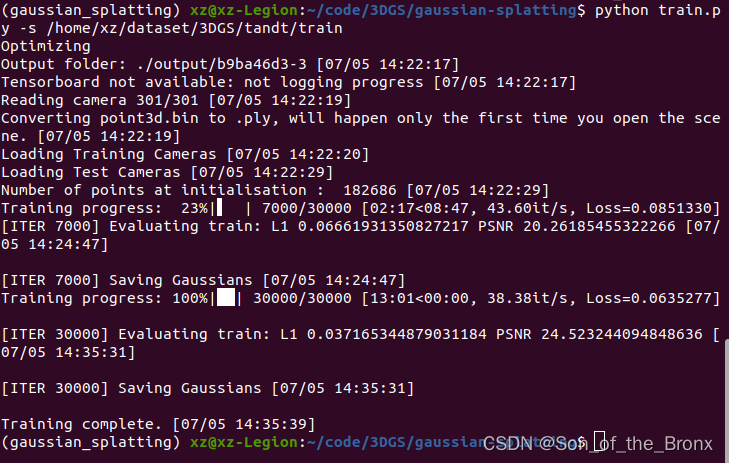
3D高斯训练结果的可视化
在windows上的可视化我是看到b站的一个视频:https://www.bilibili.com/video/BV1Z5411C7rB/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=2cbf4364275a2c6c4db080c149572d49。他介绍了在windows上用官方直接编译好的exe文件去对训练结果做可视化,我后续的文字也是对这个视频的文字说明,想看视频的可以去看这个老哥的视频。
- 下载官方编译好的exe文件。
具体的下载位置在官方的github中:
- 准备好训练的结果
正常就在代码中的output目录下:
- 将准备好的文件拷到windows电脑中,主要的文件有三个:编译好的文件、训练时的数据、训练后的数据

- 将这些文件都解压,需要注意的就是去修改训练后的数据中的==cfg_args==配置文件,用记事本打开。主要是修改两个路径:
①下面这个需要改成训练后数据的目录:

②下面这个需要改成训练时数据的目录:
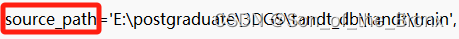
5. 使用编译好的文件去做可视化
解压并打开 viewers 的 bin 目录,看到里面有高斯viewer的exe文件
用windows的终端打开,输入下面指令,注意后面的目录需要换成在第四步中改好配置文件的训练后数据的目录
.\SIBR_gaussianViewer_app.exe -m E:\postgraduate\3DGS\train\b9ba46d3-3
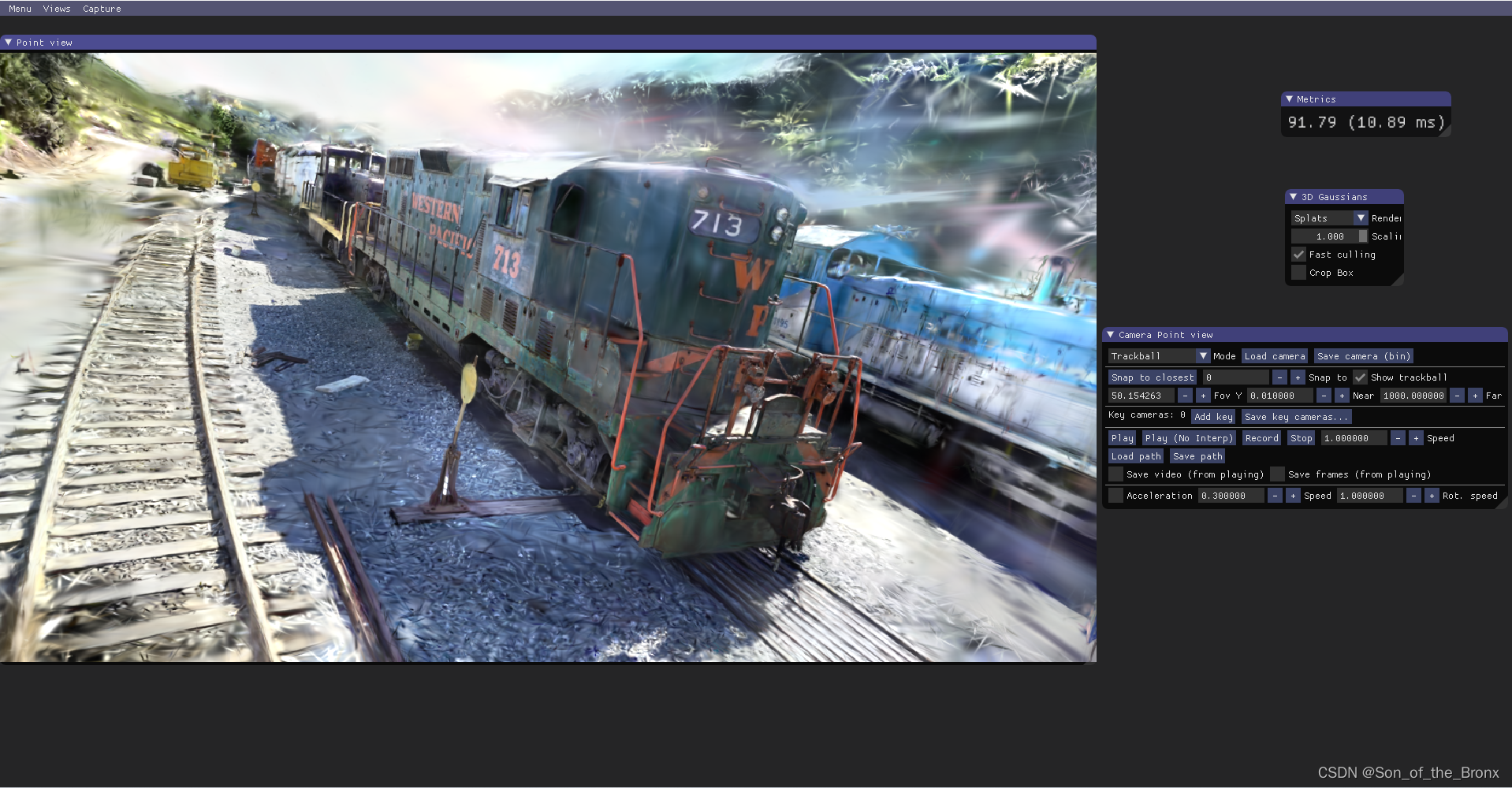
- 最后就是可以可视化这个3D高斯训练后的模型
总结
这样就可以完成整个3d高斯的流程,整体的视图质量确实很高,而且这个场景才训练了13分钟,而最初的nerf在训练那个乐高模型的时候,3090跑了6个小时,这个时间长的原因可能迭代次数也比3D高斯多,而且整体网络也比较简单,但是3D高斯耗时低且渲染的质量高,真的是非常好的工作。后续就是进一步学习这类工作。
这篇关于ubuntu20部署3d高斯的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









