本文主要是介绍数据结构之栈的超详细讲解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
引言
一.栈的概念
二.栈的结构
三.栈的实现
栈结构的实现
栈操作函数的声明
栈中方法的实现
栈的初始化
栈的销毁
入栈
出栈
取栈顶元素
判断栈中是否为空
获取栈中数据个数
四.测试
代码展示:
结构展示:
五.小结
六.完整代码
Stack.h
Stack.c
text.c
引言
这个专题是专门对栈进行详细的讲解,栈这个数据结构其实和之前的顺序表和单链表一样,同样是线性结构,但它的限制更大,如果想看之前单链表和顺序表数据结构的实现,或者是之后的数据结构我现在还没出的,都可以订阅我这个数据结构初阶的专栏--http://t.csdnimg.cn/sz4xS.好了,话不多说,点赞关注我们开始!

一.栈的概念
栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端 称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则。
压栈:栈的插入操作叫做进栈/压栈/入栈,入数据在栈顶。
出栈:栈的删除操作叫做出栈。出数据也在栈顶。
栈这个数据结构可以总结为四个字:后进先出
二.栈的结构
因为栈也是一种线性结构,所以并不复杂,如下图所示:
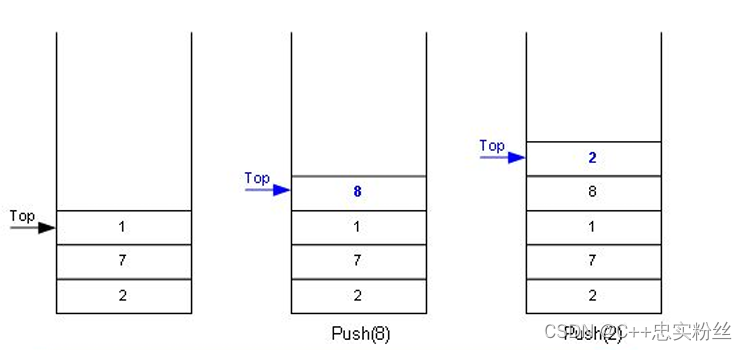
栈这种结构在我们生活中其实并不少见,比如我们打羽毛球用的羽毛球桶,装子弹的弹匣,都满足后进先出的一个特性.
三.栈的实现
栈结构的实现
我们可以用三种方法实现栈这个结构:
方法一:
我们用双向链表构建栈,如下图所示:
这样做的好处是:双向链表能很轻松的寻找前面的节点
方法二:
我们用单链表构建栈,如下图所示:
我们用单链表构建栈时,我们入栈时需要头插,因为单链表找前面的节点是不好找的
方法三:
我们用动态数组构建栈:
这个方法就类似于基于动态数组构建顺序表



那么这三种方法选择哪一种呢?
首先因为单链表的原因,我们先把双向链表PASS掉
接下来就在单链表和动态数组中选择
其实两者相差不大,但由于动态数组具有元素高效率存储,所以这里选择动态数组实现栈
代码展示:
//栈的结构
typedef int STDataType;typedef struct Stack
{STDataType* a;int top;int capacity;
}ST;注意:这里的STDataType和之前的链表和顺序表一样,方便后面进行类型的替换
a时我们的动态数组
top是我们的栈顶指针
capacity是我们的空间容量
栈操作函数的声明
对于线性表来说,操作函数大同小异,所以栈的操作函数其实跟单链表和顺序表差不多
下面便是操作函数的声明:
//函数的声明
//初始化和销毁
void STInit(ST* pst);
void STDestory(ST* pst);
//入栈和出栈
void STPush(ST* pst, STDataType x);
void STPop(ST* pst);
//取栈顶元素
STDataType STTop(ST* pst);
//判空
bool STEmpty(ST* pst);
//获取数据个数
int STSize(ST* pst);栈中方法的实现
栈的初始化
注意:
栈这里的初始化分为两种方式:
1.top指向-1,top指向栈顶元素,如下图所示:
注意:这里的top不能指向为0,因为这样的话,当top指为0时,不知道是否含有数据
2.top指向0,top指向栈顶元素的下一位,如下图所示:
这里我用了第二种,因为这里的top即为元素个数,对于后面的操作会方便一点.


//初始化和销毁
void STInit(ST* pst)
{assert(pst);pst->a = NULL;//top指向栈顶数据的下一个位置pst->top = 0;//top指向栈顶数据//pst->top = -1;pst->capacity = 0;
}栈的销毁
void STDestory(ST* pst)
{assert(pst);free(pst->a);pst->a = NULL;pst->top = pst->capacity = 0;
}注意最后要将top和capacity置为0
入栈
和顺序表的插入数据类似,首先进行断言处理,再看空间是否够用,不够用就进行两倍扩容.
注意:这里使用了三目操作符,因为我们初始化capacity为0,两倍扩容之后还是为0,所以当它为0时,直接初始化为4,或者其他值.
void STPush(ST* pst, STDataType x)
{assert(pst);//扩容if (pst->top == pst->capacity){int newcapcacity = pst->capacity == 0 ? 4 : pst->capacity * 2;STDataType* tmp = (STDataType*)realloc(pst->a, newcapcacity * sizeof(STDataType));if (tmp == NULL){perror("realloc fail!");return;}pst->a = tmp;pst->capacity = newcapcacity;}pst->a[pst->top] = x;pst->top++;
}出栈
这个很简单,只需top--即可
void STPop(ST* pst)
{assert(pst);assert(pst->top > 0);pst->top--;
}取栈顶元素
注意:这里需要额外对top进行判空处理
//取栈顶元素
STDataType STTop(ST* pst)
{assert(pst);assert(pst->top > 0);return pst->a[pst->top - 1];
}判断栈中是否为空
top即为我们栈中元素的个数
//判空
bool STEmpty(ST* pst)
{assert(pst);return pst->top == 0;
}获取栈中数据个数
//获取数据个数
int STSize(ST* pst)
{assert(pst);return pst->top;
}四.测试
我们入栈一些元素,再将它们打印出来.
代码展示:
#include "Stack.h"int main()
{ST s;STInit(&s);STPush(&s, 1);STPush(&s, 2);STPush(&s, 3);STPush(&s, 4);//遍历栈中的元素while (!STEmpty(&s)){printf("%d ", STTop(&s));STPop(&s);}}结构展示:

后进先出没有问题
五.小结
栈这个数据结构对比顺序表和单链表的实现真的简单了不少,但它的OJ题可不简单,后面我会更新关于栈的经典OJ练习,如果觉得这篇博客对你有帮助的话,一定要点赞关注哦!如果你有任何问题后可以打在评论区,大家一起学习,共同进步!

六.完整代码
Stack.h
#pragma once
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
//栈的结构
typedef int STDataType;typedef struct Stack
{STDataType* a;int top;int capacity;
}ST;//函数的声明
//初始化和销毁
void STInit(ST* pst);
void STDestory(ST* pst);
//入栈和出栈
void STPush(ST* pst, STDataType x);
void STPop(ST* pst);
//取栈顶元素
STDataType STTop(ST* pst);
//判空
bool STEmpty(ST* pst);
//获取数据个数
int STSize(ST* pst);
Stack.c
#define _CRT_SECURE_NO_WARNINGS 1#include "Stack.h"//初始化和销毁
void STInit(ST* pst)
{assert(pst);pst->a = NULL;//top指向栈顶数据的下一个位置pst->top = 0;//top指向栈顶数据//pst->top = -1;pst->capacity = 0;
}
void STDestory(ST* pst)
{assert(pst);free(pst->a);pst->a = NULL;pst->top = pst->capacity = 0;
}
//入栈和出栈
void STPush(ST* pst, STDataType x)
{assert(pst);//扩容if (pst->top == pst->capacity){int newcapcacity = pst->capacity == 0 ? 4 : pst->capacity * 2;STDataType* tmp = (STDataType*)realloc(pst->a, newcapcacity * sizeof(STDataType));if (tmp == NULL){perror("realloc fail!");return;}pst->a = tmp;pst->capacity = newcapcacity;}pst->a[pst->top] = x;pst->top++;
}
void STPop(ST* pst)
{assert(pst);assert(pst->top > 0);pst->top--;
}
//取栈顶元素
STDataType STTop(ST* pst)
{assert(pst);assert(pst->top > 0);return pst->a[pst->top - 1];
}
//判空
bool STEmpty(ST* pst)
{assert(pst);return pst->top == 0;
}
//获取数据个数
int STSize(ST* pst)
{assert(pst);return pst->top;
}text.c
#include "Stack.h"int main()
{ST s;STInit(&s);STPush(&s, 1);STPush(&s, 2);STPush(&s, 3);STPush(&s, 4);//遍历栈中的元素while (!STEmpty(&s)){printf("%d ", STTop(&s));STPop(&s);}}这篇关于数据结构之栈的超详细讲解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






