本文主要是介绍多选择性更容易理解!基于可选择性遗传算法的微电网经济-低碳协调优化程序代码!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
随着能源危机和环境污染日益严重,传的能源已不再满足人们日益增长的能源需求,丰富清洁的可再生能源是未来的发展方向,分布式可再生能源发电技术获得了飞速进步。然而,在引入分布式可再生电源后,微电网的复杂性以及供需侧的不平衡大幅度增加,给各类微电网的经济优化和环境优化调度带来了困难,随着智能化相关技术的发展,基于遗传算法的微电网优化调度方法研究被重点关注。
遗传算法简介
遗传算法的起源可追溯到20世纪60年代初期。1967年,美国密歇根大学J. Holland教授的学生 Bagley在他的博士论文中首次提出了遗传算法这一术语,并讨论了遗传算法在博弈中的应用,但早期研究缺乏带有指导性的理论和计算工具的开拓。1975年, J. Holland等提出了对遗传算法理论研究极为重要的模式理论,出版了专著《自然系统和人工系统的适配》,在书中系统阐述了遗传算法的基本理论和方法,推动了遗传算法的发展。20世纪80年代后,遗传算法进入兴盛发展时期,被广泛应用于自动控制、生产计划、图像处理、机器人等研究领域。
由于遗传算法不能直接处理问题空间的参数,因此必须通过编码将要求解的问题表示成遗传空间的染色体或者个体。这一转换操作就叫做编码,也可以称作(问题的)表示(representation)。
评估编码策略常采用以下3个规范:
a)完备性(completeness):问题空间中的所有点(候选解)都能作为GA空间中的点(染色体)表现。
b)健全性(soundness):GA空间中的染色体能对应所有问题空间中的候选解。
c)非冗余性(nonredundancy):染色体和候选解一一对应。
适应度函数
进化论中的适应度,是表示某一个体对环境的适应能力,也表示该个体繁殖后代的能力。遗传算法的适应度函数也叫评价函数,是用来判断群体中的个体的优劣程度的指标,它是根据所求问题的目标函数来进行评估的。
遗传算法在搜索进化过程中一般不需要其他外部信息,仅用评估函数来评估个体或解的优劣,并作为以后遗传操作的依据。由于遗传算法中,适应度函数要比较排序并在此基础上计算选择概率,所以适应度函数的值要取正值。由此可见,在不少场合,将目标函数映射成求最大值形式且函数值非负的适应度函数是必要的。
适应度函数的设计主要满足以下条件:
a)单值、连续、非负、最大化;b)合理、一致性;
c)计算量小;d)通用性强;
在具体应用中,适应度函数的设计要结合求解问题本身的要求而定。适应度函数设计直接影响到遗传算法的性能。
初始群体选取
遗传算法中初始群体中的个体是随机产生的。一般来讲,初始群体的设定可采取如下的策略:
a)根据问题固有知识,设法把握最优解所占空间在整个问题空间中的分布范围,然后,在此分布范围内设定初始群体。
b)先随机生成一定数目的个体,然后从中挑出最好的个体加到初始群体中。这种过程不断迭代,直到初始群体中个体数达到了预先确定的规模。
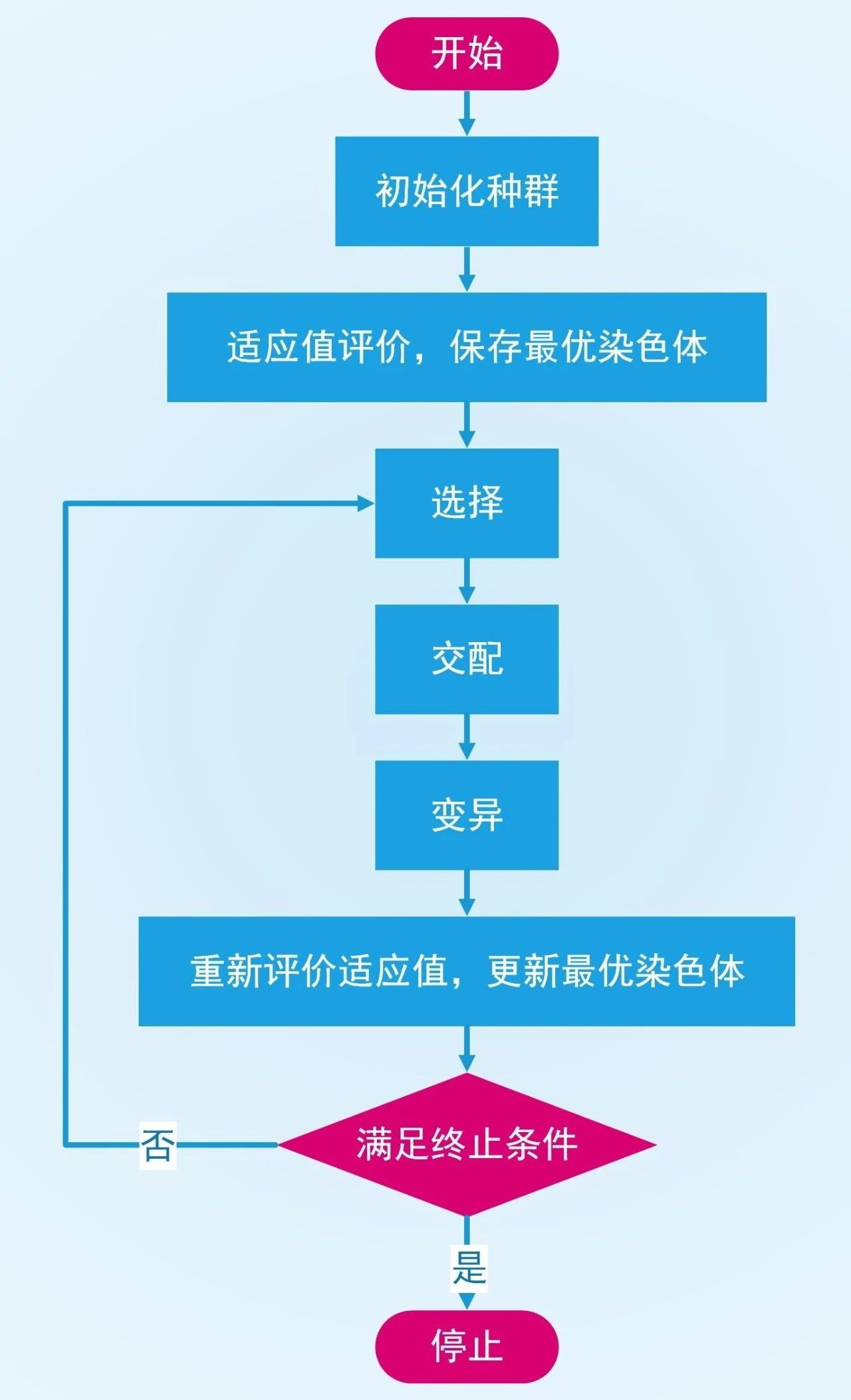
基本运算过程
遗传算法的基本运算过程如下:
(1)初始化:设置进化代数计数器t=0,设置最大进化代数T,随机生成M个个体作为初始群体P(0)。
(2)个体评价:计算群体P(t)中各个个体的适应度。
(3)选择运算:将选择算子作用于群体。选择的目的是把优化的个体直接遗传到下一代或通过配对交叉产生新的个体再遗传到下一代。选择操作是建立在群体中个体的适应度评估基础上的。
(4)交叉运算:将交叉算子作用于群体。遗传算法中起核心作用的就是交叉算子。
(5)变异运算:将变异算子作用于群体。即是对群体中的个体串的某些基因座上的基因值作变动。群体P(t)经过选择、交叉、变异运算之后得到下一代群体P(t+1)。
(6)终止条件判断:若t=T,则以进化过程中所得到的具有最大适应度个体作为最优解输出,终止计算。
遗传操作包括以下三个基本遗传算子(genetic operator):选择(selection);交叉(crossover);变异(mutation)。
选择
从群体中选择优胜的个体,淘汰劣质个体的操作叫选择。选择算子有时又称为再生算子(reproduction operator)。选择的目的是把优化的个体(或解)直接遗传到下一代或通过配对交叉产生新的个体再遗传到下一代。选择操作是建立在群体中个体的适应度评估基础上的,常用的选择算子有以下几种:适应度比例方法、随机遍历抽样法、局部选择法。
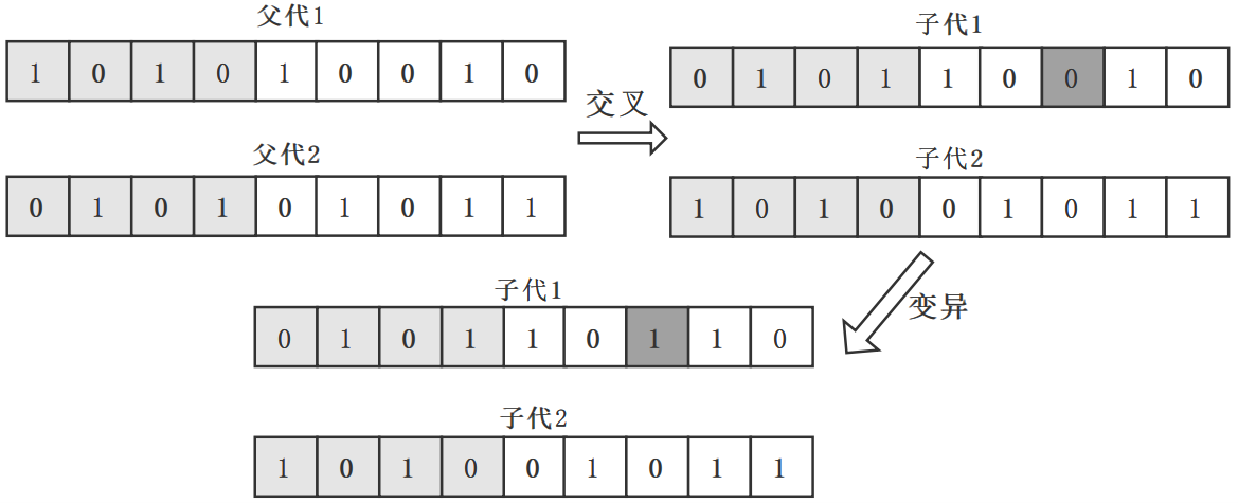
交叉
在自然界生物进化过程中起核心作用的是生物遗传基因的重组(加上变异)。同样,遗传算法中起核心作用的是遗传操作的交叉算子。所谓交叉是指把两个父代个体的部分结构加以替换重组而生成新个体的操作。通过交叉,遗传算法的搜索能力得以飞跃提高。
变异
变异算子的基本内容是对群体中的个体串的某些基因座上的基因值作变动。依据个体编码表示方法的不同,可以有以下的算法:
a)实值变异;b)二进制变异。
一般来说,变异算子操作的基本步骤如下:
a)对群中所有个体以事先设定的变异概率判断是否进行变异;
b)对进行变异的个体随机选择变异位进行变异;
遗传算法引入变异的目的有两个:一是使遗传算法具有局部的随机搜索能力。当遗传算法通过交叉算子已接近最优解邻域时,利用变异算子的这种局部随机搜索能力可以加速向最优解收敛。显然,此种情况下的变异概率应取较小值,否则接近最优解的积木块会因变异而遭到破坏。二是使遗传算法可维持群体多样性,以防止出现未成熟收敛现象。此时收敛概率应取较大值。
终止条件
当最优个体的适应度达到给定的阈值,或者最优个体的适应度和群体适应度不再上升时,或者迭代次数达到预设的代数时,算法终止。预设的代数一般设置为100-500代。
算法特点
遗传算法具有以下几方面的特点:
(1)算法从问题解的串集开始搜索,而不是从单个解开始。这是遗传算法与传统优化算法的极大区别。传统优化算法是从单个初始值迭代求最优解的;容易误入局部最优解。遗传算法从串集开始搜索,覆盖面大,利于全局择优。
(2)遗传算法同时处理群体中的多个个体,即对搜索空间中的多个解进行评估,减少了陷入局部最优解的风险,同时算法本身易于实现并行化。
(3)遗传算法基本上不用搜索空间的知识或其它辅助信息,而仅用适应度函数值来评估个体,在此基础上进行遗传操作。适应度函数不仅不受连续可微的约束,而且其定义域可以任意设定。这一特点使得遗传算法的应用范围大大扩展。
(4)遗传算法不是采用确定性规则,而是采用概率的变迁规则来指导他的搜索方向。
(5)具有自组织、自适应和自学习性。遗传算法利用进化过程获得的信息自行组织搜索时,适应度大的个体具有较高的生存概率,并获得更适应环境的基因结构。
(6)此外,算法本身也可以采用动态自适应技术,在进化过程中自动调整算法控制参数和编码精度,比如使用模糊自适应法。
程序介绍
程序建立了基于可选择性遗传算法的微电网经济低碳协调优化模型,将遗传算法的突变和交叉分为一组选项,精英理论和随机选择方法作为一组选项,这样就得到4组选项,每组选项均可以得到相应的碳排放量和经济成本,更精确地探讨微电网优化调度。程序中算例丰富,注释清晰,干货满满,创新性和可扩展性很高,足以撑起一篇高水平论文!下面对程序做简要介绍!
程序适用平台:Matlab+Yalmip+Cplex
程序结果
1、突变+随机选择
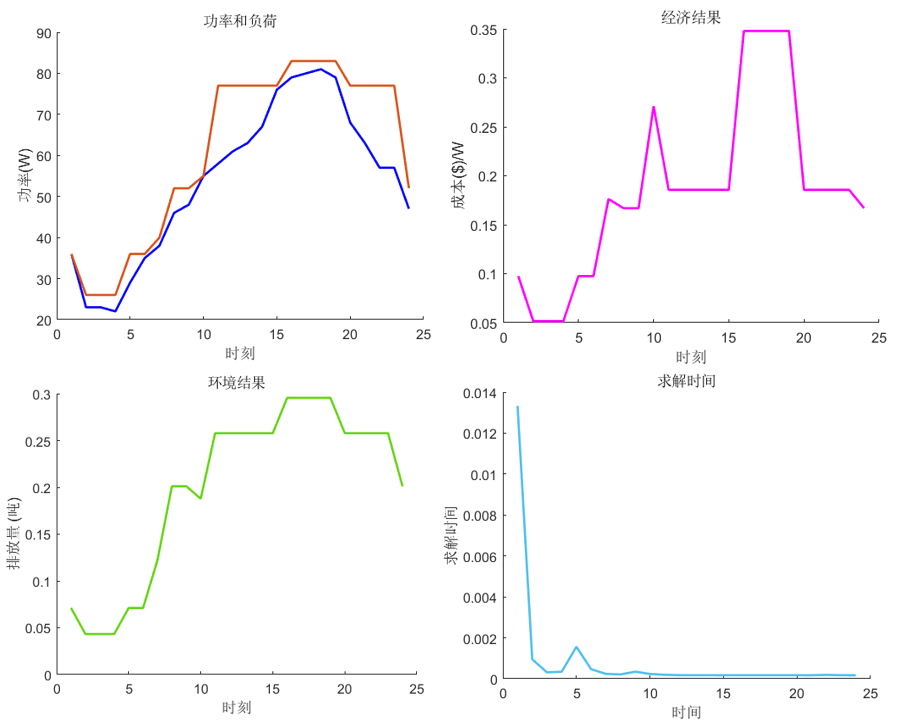
2、突变+适者生存

3、交叉+随机选择
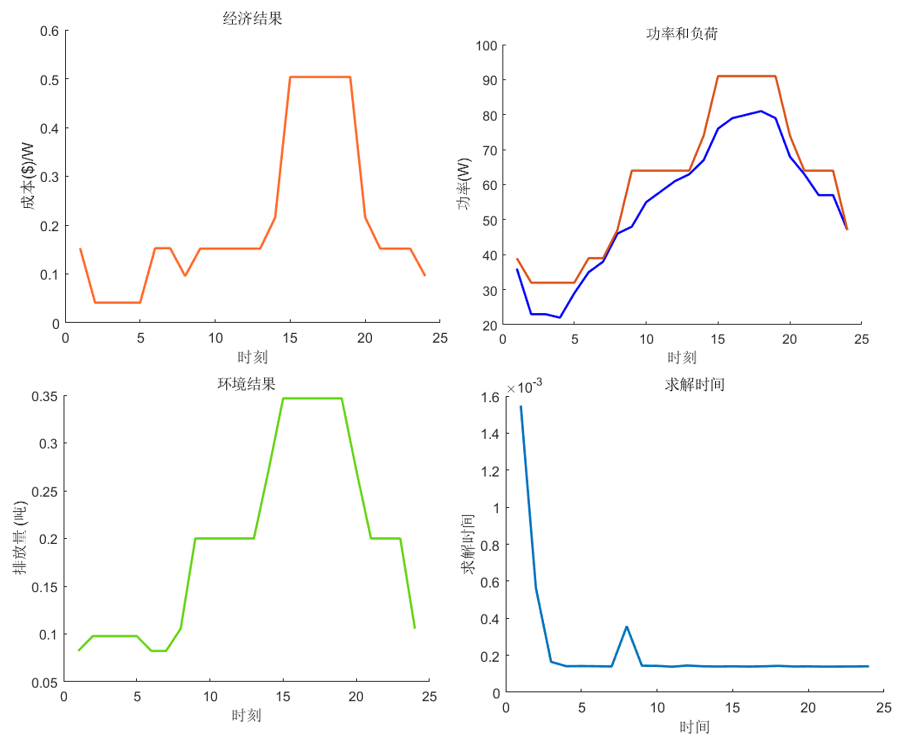
4、交叉+适者生存
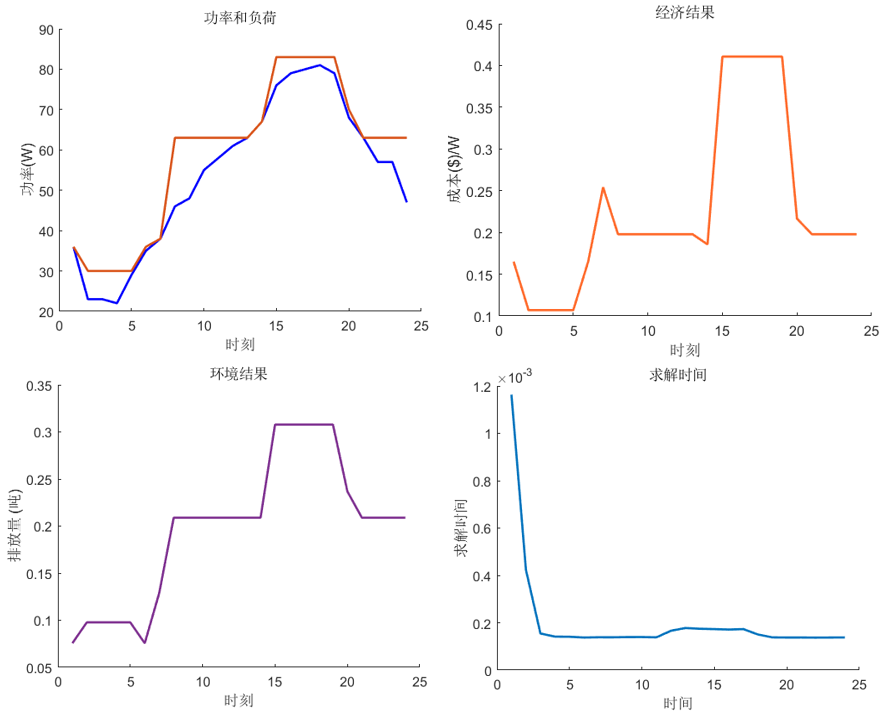
部分程序
pop=100; % 种群
m_rate = .1; % 突变率
c_pt = 2; % 交叉点
good_enough = .08; % 停止标志
weights = [1, .6, .4];
% 染色体形式
power = 1;cost = 2; emission = 3;
source_1 = [20, .02, .01];
source_2 = [120, .20, .05];
source_3 = [15, .01, .02];
source_4 = [50, .02, .04];
sources = [source_1; source_2; source_3; source_4];
% 定义范围
[num_sources, num_genes] = size(sources);
boundaries = zeros(num_genes, 2);
boundaries(1,:) = [15, 100]; % 功率约束
boundaries(2,:) = [0.15, 6.55]; % 成本约束
boundaries(3,:) = [0.15, 3.75]; % 排放量约束部分内容源自网络,侵权联系删除!
欢迎感兴趣的小伙伴关注并私信获取完整版代码,小编会不定期更新高质量的学习资料、文章和程序代码,为您的科研加油助力!
这篇关于多选择性更容易理解!基于可选择性遗传算法的微电网经济-低碳协调优化程序代码!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





