本文主要是介绍Prometheus 2: 一个专门评估其他语言模型的开源语言模型(续集),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
普罗米修斯的续集来了。
专有的语言模型如 GPT-4 经常被用来评估来自各种语言模型的回应品质。然而,透明度、可控制性和可负担性等考虑强烈促使开发专门用于评估的开源语言模型。另一方面,现有的开源评估语言模型表现出关键的缺点:1) 它们给出的分数与人类给出的分数存在显著差异,以及 2) 它们缺乏灵活性来执行直接评估和成对排序,这是最普遍的两种评估形式。此外,它们没有根据自定评估标准进行评估的能力,而是专注于一般属性,如有帮助性和无害性。为了解决这些问题,本文介绍了 PROMETHEUS 2,一个比其前身更强大的评估语言模型,它能密切模仿人类和 GPT-4 的判断。此外,它能够处理直接评估和成对排序两种格式,并配合使用者定义的评估标准。在四个直接评估基准和四个成对排序基准上,PROMETHEUS 2 在所有测试的开源评估语言模型中,与人类和专有语言模型评判者取得最高的相关性和一致性。本文的模型、程序代码和数据都是公开可用的。
repo: https://github.com/prometheus-eval/prometheus-eval
abs: https://arxiv.org/abs/2405.01535
背景
评估语言模型(LM)产生的输出品质正逐渐变得困难,因为输出涵盖了极其多样化的文本和复杂任务。为了解决这个问题,基于语言模型的评估已成为评估 LM 生成文本的一种可扩展和便宜的范式(Li et al., 2024; Gao et al., 2024)。在这个范式中,LM 要么被提示输出一个品质的标量指标(称为直接评估),要么确定哪一个输出是优选的(称为成对排序)。先前采用专有 LM 作为评估器的工作不仅表现出与人类评估的高度相关性,而且还提高了速度和成本效益。
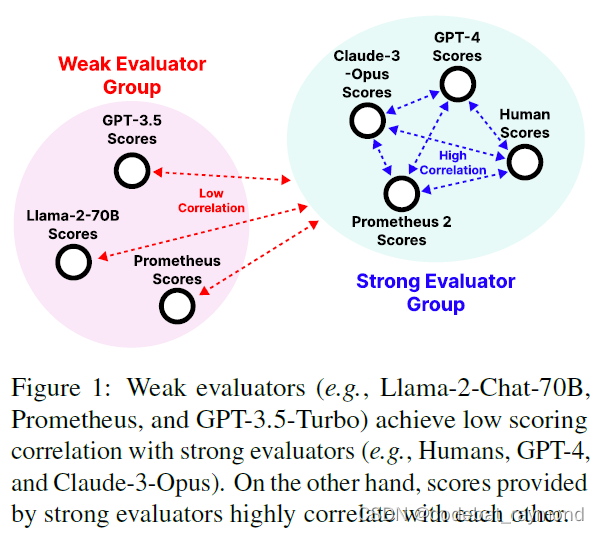
然而,依赖专有 LM 进行评估会带来重大挑战。关于其训练数据的透明度缺乏损害了公平性和合规性,使它们在评估管道中的使用存在问题。此外,关于可控制性和可负担性的顾虑也依然存在。为了解决这些问题,最近的工作专注于开发开放存取、透明和可控制的评估 LM。然而,这些模型通常产生的评分决策与人类判断或专有 LM 做出的判断相关性不够高,无法有效模拟它们。此外,开放评估 LM 缺乏灵活性,因为它们通常只训练用于执行直接评估或成对排序,并且基于一般公众偏好(如有帮助性和无害性)进行评估,限制了它们处理多样化真实场景的能力。
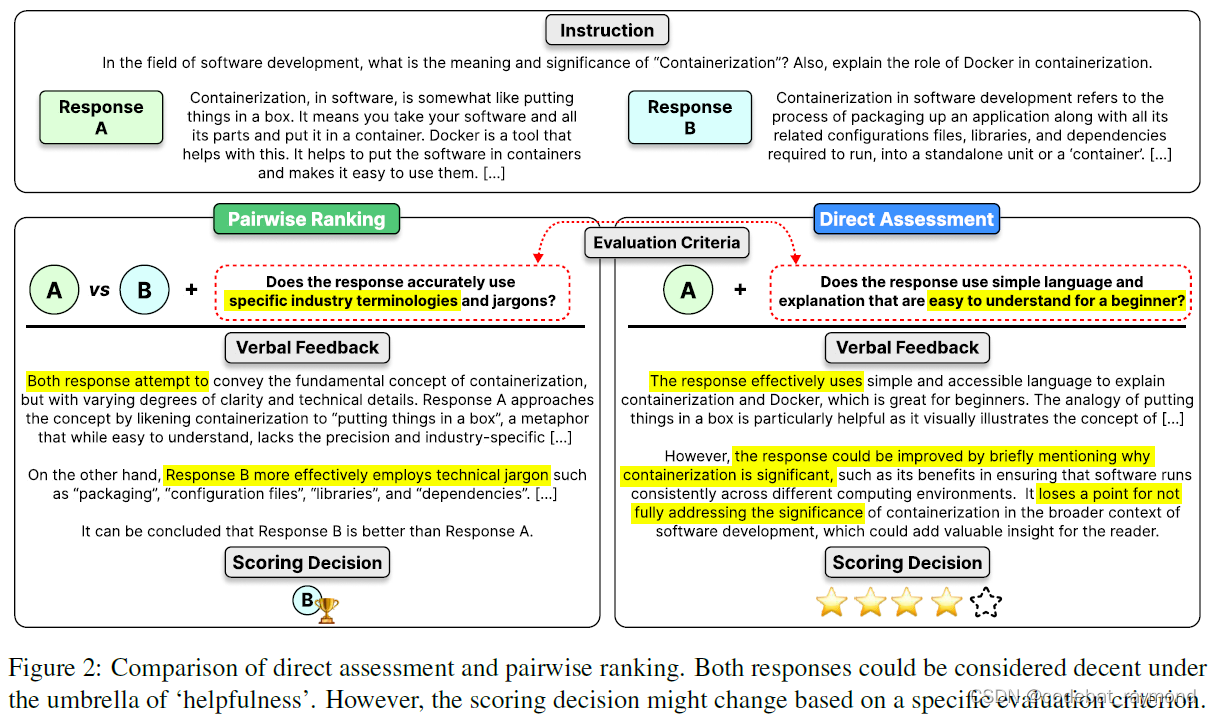
为了缩小与专有语言模型的差距,本文的作者们研究了统一两种基于模型的评估范式 - 直接评估和成对排序,以训练一个稳健的统一评估语言模型。他们提出了一个方法,通过合并两个分别在直接评估和成对排序格式上训练的评估语言模型的权重来实现。他们的关键实证观察是,权重合并可以产生一个评估语言模型,不仅可以在两种格式下工作,而且优于联合训练或只在单一格式上训练的评估语言模型。

为了展示他们的方法,作者们开发了 PREFERENCE COLLECTION,这是一个新的细粒度成对排序反馈数据集,它建立在直接评估反馈数据集 FEEDBACK COLLECTION 之上。他们选择 Mistral-7B 和 Mixtral-8x7B 作为基础模型,并合并分别在 FEEDBACK COLLECTION 和 PREFERENCE COLLECTION 上训练的评估语言模型的权重,以获得他们的最终模型 PROMETHEUS 2 (7B & 8x7B)。

在四个直接评估基准和四个成对排序基准上,与现有的开源评估语言模型相比,PROMETHEUS 2 模型展示了与人类评估者和专有语言模型评判者最高的相关性和一致性。在直接评估基准上,PROMETHEUS 2 模型的 Pearson 相关系数在所有数据集上都超过其他基准0.2 个单位。同样地,在成对排序基准上,PROMETHEUS 2 模型在所有测试的开源评估语言模型中,展现了与人类评估者最高的一致性,并将与 GPT-4 的性能差距缩小了一半。
本文的贡献可以总结如下:
引入了 PROMETHEUS 2 (7B & 8x7B),这是最先进的开源评估语言模型,在直接评估和成对排序上都取得与人类评估者和专有语言模型评判者高度相关的分数。
引入了一个成对排序反馈数据集,称为 PREFERENCE COLLECTION,其中包括超过1000个评估标准,超越了有帮助性和无害性。
显示了合并在直接评估和成对排序反馈数据集上训练的评估语言模型的权重,可以得到一个在两种方案中都表现出色的统一评估语言模型。
相关工作
基于语言模型的评估
为了评估语言模型的生成能力,先前的工作如 GEM 基准采用 Rouge、BLEU 和 BERTScore 作为它们的度量,这些度量衡量参考答案和回应之间的词汇或语义相似性。然而,这些传统的度量容易产生假阴性,因为它们没有足够的表达能力来识别品质好但与参考答案不同的回应。
最近,采用语言模型作为评判已经受到关注,成为模仿人类评估的深度和粒度的有前景的范式。为了减少对专有语言模型的过度依赖,后续工作建议训练专门用于评估的语言模型。然而,开放评估语言模型在不同评估方案中缺乏灵活性,与专有语言模型相比表现出较弱的评估性能。本文旨在通过引入 PROMETHEUS 2 来弥合这一差距。
权重合并
先前的工作已经证明,权重合并可以提高跨各个领域的性能,包括语言建模、指令调整和与用户偏好对齐。在本文中,作者们特别关注提高开放评估语言模型的评估能力。通过合并在不同评估格式上训练的模型,即直接评估和成对排序,作者们旨在获得一个评估语言模型,不仅可以在两种格式下工作,而且表现出与专有语言模型一样好的评估性能。
方法
作者们提出了一个新的方法来训练统一评估语言模型,基于合并分别针对直接评估和成对排序训练的模型的权重。他们首先介绍直接评估和成对排序的背景知识,然后是训练数据的构建过程(第3.3节)。最后,他们介绍了训练最先进的评估语言模型 PROMETHEUS 2 的方法(第3.4节)。

作者们介绍了 PREFERENCE COLLECTION,这是第一个包含超过1000个实例级评估标准的成对排序反馈数据集,超越了基本品质,如有帮助性和无害性。PREFERENCE COLLECTION 是通过对 FEEDBACK COLLECTION 应用两个修改而构建的。首先,由于 FEEDBACK COLLECTION 为每个指令包含五个回应,每个回应对应1到5之间的评分决策,作者们将五个回应中的两个配对,得到每个指令的十个组合。使用每个回应的现有评分决策,他们确定哪个回应更好,并为该对分配一个新的评分决策(即"回应A更好"或"回应B更好")。其次,为了为每对回应生成新的口头反馈,作者们提示 GPT-4 识别两个回应的共同点和差异点。作者们还进行了质量验证过程,以确保 PREFERENCE COLLECTION 的质量。
作者们采用 Mistral-7B 和 Mixtral-8x7B 作为基础模型,并合并分别在 FEEDBACK COLLECTION 和 PREFERENCE COLLECTION 上训练的评估语言模型的权重,以获得最终的 PROMETHEUS 2 模型。具体来说,他们采用线性合并的方式:
$$
\theta_{final}=\alpha \times \theta_d+(1-\alpha) \times \theta_p
$$
其中 $\alpha$ 设为0.5。作者们还测试了其他合并技术,如 Task Arithmetic 合并、TIES 合并和 DARE 合并,并发现 DARE 合并在使用 Mixtral-8x7B 作为基础模型时效果最好。
实验设置
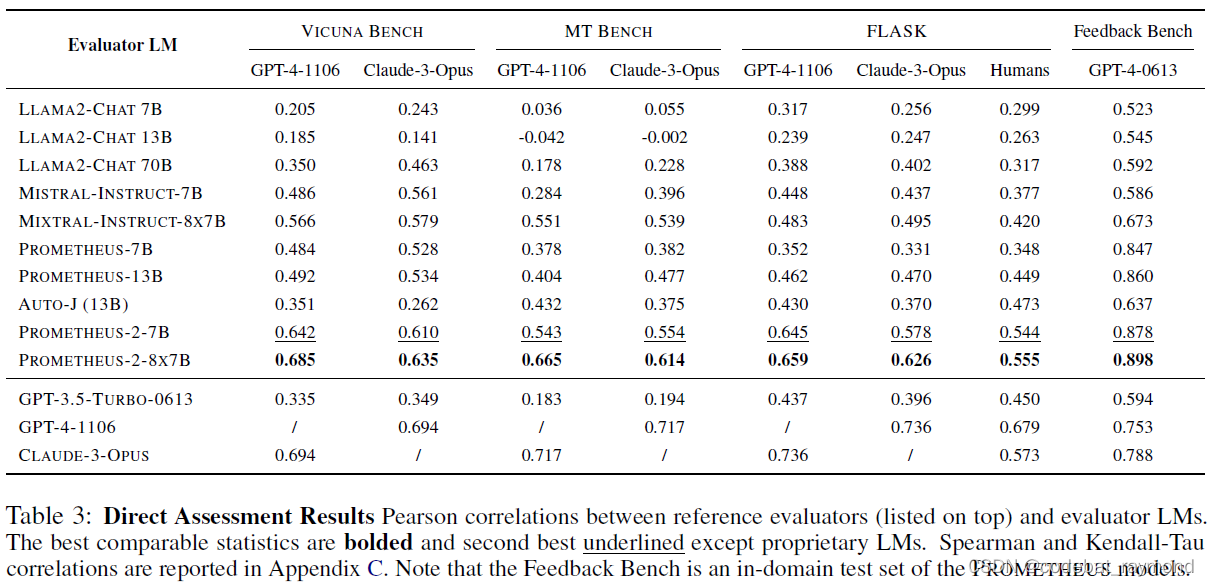
作者们在八个基准上评估了评估语言模型的性能,包括四个直接评估基准(Vicuna Bench、MT Bench、FLASK 和 Feedback Bench)和四个成对排序基准(HHH Alignment、MT Bench Human Judgment、Auto-J Eval 和 Preference Bench)。在直接评估中,他们进行了基于参考的评估,将参考答案附加为输入。他们使用 Pearson、Spearman 和 Kendall-Tau 作为性能度量,以衡量与参考评估者的评分相关性。在成对排序中,他们进行了无参考评估。根据人类给出的判断,他们使用准确率作为度量,以衡量评估语言模型与人类之间的一致性。
作者们使用多种基准模型进行比较,包括提示基准、单一格式训练的评估语言模型、联合训练的评估语言模型以及权重合并的 PROMETHEUS 2 模型。这些基准模型涵盖了不同的模型尺度和训练方法,以全面评估 PROMETHEUS 2 模型的性能。
实验结果
实验结果显示,PROMETHEUS 2 模型在直接评估和成对排序基准上都取得了显著的性能提升。在直接评估基准上,PROMETHEUS 2 模型的评分决策与 GPT-4、Claude-3-Opus 和人类评估者的评分决策高度相关,无论参考评估者和基准如何,Pearson 相关系数都高于0.5。相比之下,基础语言模型、单一格式训练的语言模型和联合训练的语言模型与 GPT-4、Claude-3-Opus 和人类的相关性较低,大多低于0.5。值得注意的是,PROMETHEUS 2 模型在与专有语言模型的相关性上至少超过 Prometheus 和 Auto-J 0.2 个单位。此外,在 FLASK 基准上,虽然人类与 GPT-4 之间的相关性为0.679,但之前 Prometheus-13B 与人类的最高相关性为0.449,而 PROMETHEUS-2-8X7B 与人类的相关性达到了0.555,有效地将差距缩小了一半。
在成对排序基准上,PROMETHEUS 2 模型在所有四个基准上都取得了最高分数,表明它们能够有效地模拟人类判断。值得注意的是,虽然 HHH Alignment 是 Pair RM 的同域测试集,Auto-J Eval 是 Auto-J 的同域测试集,但 PROMETHEUS-2-8X7B 取得了更高的分数。这表明,用反馈数据训练大型语言模型(即 Mixtral-8x7B)可能是获得一个稳健的评估语言模型的有效策略,该模型可以超越其训练数据进行泛化。此外,与现有的评估语言模型相比,PROMETHEUS 2 模型在异域测试集上至少将与 GPT-4 的性能差距缩小了一半。
除了获得高相关性和准确性外,实现高一致性是评估语言模型的另一个重要方面。具体来说,作者们进行了一项实验,测试评估语言模型是否能在不同的评估格式下给出一致的分数。为此,他们使用成对排序基准,并测量在直接评估格式和成对排序格式下提示时的性能差异。结果表明,PROMETHEUS 2 模型在评估格式之间表现出较低的性能差异,表明它们具有稳健性。
讨论
为了理解权重合并方法在评估语言模型中的有效性,作者们提出了三个研究问题:
• RQ1:权重合并是否比联合训练更有效?(第6.1节)
• RQ2:权重合并的有效性是否是由于模型集成?(第6.2节)
• RQ3:直接评估和成对排序之间的学习在多大程度上相互促进?(第6.3节)
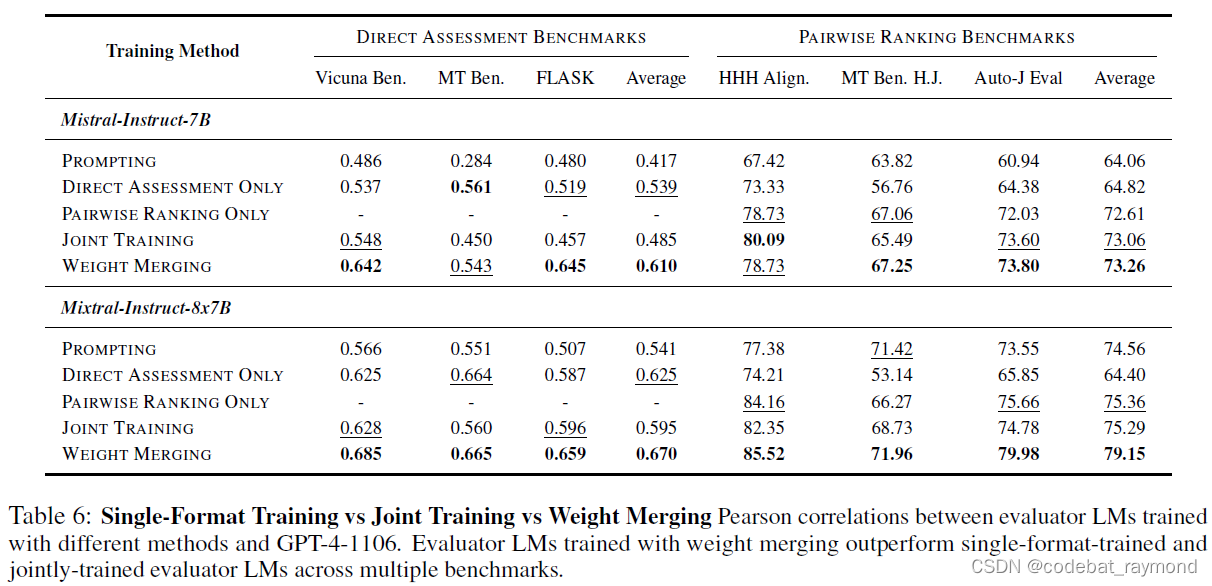
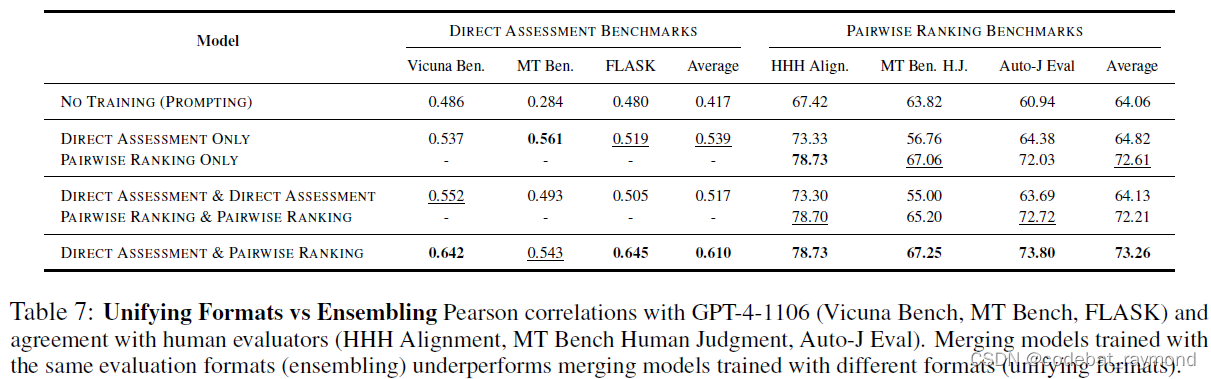
令人惊讶的是,作者们发现,通过联合训练训练的评估语言模型的性能往往低于单一格式训练的评估语言模型,这表明
存在负迁移。具体而言,仅在直接评估格式上训练的评估语言模型在不同模型尺度下获得更高的相关性。类似地,仅在成对排序格式上训练的评估语言模型在使用 Mixtral-8x7B 作为基础模型时,获得更高的平均准确率。
另一方面,通过权重合并训练的评估语言模型不仅与联合训练的评估语言模型相比表现出优越的性能,而且与单一格式训练的评估语言模型相比也是如此,这表明存在正迁移。此外,尽管两者都互惠互利,但合并成对排序评估语言模型的权重比反向操作更能显著提高直接评估性能。
为了探索权重合并的有效性是否是由于模型集成的效果,作者们进行了一个消融实验,训练多个评估语言模型,并将它们合并。结果表明,在大多数情况下,合并在相同评估格式上训练的评估语言模型并不能提高评估性能。相反,通过合并分别在直接评估和成对排序格式上训练的两个评估语言模型,得到的评估语言模型在不同设置下表现出优越的性能。这表明,权重合并带来的正迁移来自统一不同的评估格式,而不是通过集成多个模型。
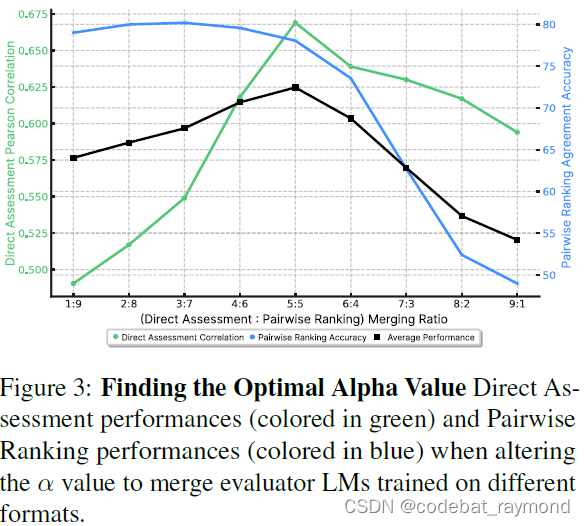
为了探索直接评估反馈数据如何影响成对排序准确性,反之亦然,作者们通过调整线性合并期间的 $\alpha$ 值进行了实验。结果表明,对于直接评估基准,当 $\alpha$ 设置为0.5时,评估语言模型获得最佳性能。这间接表明,成对排序和直接评估反馈数据都同等重要。另一方面,对于成对排序基准,当 $\alpha$ 设置为0.3时,性能最佳。这也间接意味着,虽然两者都相互有益,但成对排序训练比反向操作更能显著提高直接评估性能。
我的观点
本文介绍了 PROMETHEUS 2,这是一个专门用于评估其他回应的开源语言模型。与现有的开源评估语言模型不同,PROMETHEUS 2 模型能够有效地处理直接评估和成对排序(最普遍的两种评估方案),在这两种方案上都表现出优越的性能和一致的结果,显著缩小了与专有语言模型评估的差距。为了训练 PROMETHEUS 2 模型,作者们开发了 PREFERENCE COLLECTION,这是第一个包含超过1000个实例级评估标准的成对排序数据集,超越了基本品质,如有帮助性和无害性。值得注意的是,作者们发现合并在直接评估或成对排序格式上训练的评估语言模型的权重,可以得到一个表现出色的统一评估语言模型。作者们希望这项工作能鼓励更多关于使用开源语言模型作为评估器的研究,从而摆脱对专有模型进行公平和可及的评估的依赖。
总的来说,这项研究的贡献是相当重要和有价值的。PROMETHEUS 2 模型在多个基准上优于现有的开源评估语言模型,展现了提出的权重合并方法的有效性。作者们还深入探讨了权重合并方法背后的原因,提供了有见地的分析。这项研究的结果对于开发更强大、更灵活的开源评估语言模型具有重要意义。它为未来在这个领域的研究提供了一个有前景的方向。随着越来越多的语言模型被开发出来,拥有一个稳健、可靠的评估语言模型将变得越来越重要。这项研究朝着这个目标迈出了重要的一步。
这篇关于Prometheus 2: 一个专门评估其他语言模型的开源语言模型(续集)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









