本文主要是介绍数智先锋 | 多场景数据治理案例,释放数据要素生产力,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据作为第五大生产要素,成为释放新质生产力的关键基础。
当前各个行业数字化建设如火如荼,全力挖掘数据价值以驱动行业高质量应用发展。数据治理成为数据要素价值发挥的重要基础和前提。
数据治理不单是技术问题,不是依赖工具就能解决的,重难点在于结合实际业务需求进行数据顶层设计、数据治理体系建设、标准管控实施、服务共享机制等。
从企业、园区、政务领域的不同需求场景,我们为您介绍基于smardaten平台的典型数据治理实践案例。
01 企业数据治理
数据资源是企业数字化转型的核心要素和基础资源,当前数据资产管理中依然存在三大难题:找数据难、治数据难、用数据难。企业进行数据资产管理是数字化建设的长期任务。
案例1煤矿集团数据治理
某煤矿集团目前在煤炭板块建立集团数据标准化体系,包括一套数据标准和数据管理、应用、运行3大保障体系,但聚焦到煤矿板块尚无矿井侧数据采、治、管等能力。作为核心领域之一,解决数据标准问题,才能进一步扩展创新数字化应用,因此需要建设基于数据标准化体系的数据整合治理平台。
主要思路就是以集团数据标准化体系为基础,整合矿井侧的煤炭产业、安全管理、生产辅助、生产调度、生产技术、销售管理和其他业务相关的数据资源,构建矿井侧数据采集、治理、共享和应用等能力,适配矿井侧业务特点及数据特性,从而达到数据标准化体系落地的数据整合治理研究的目标。
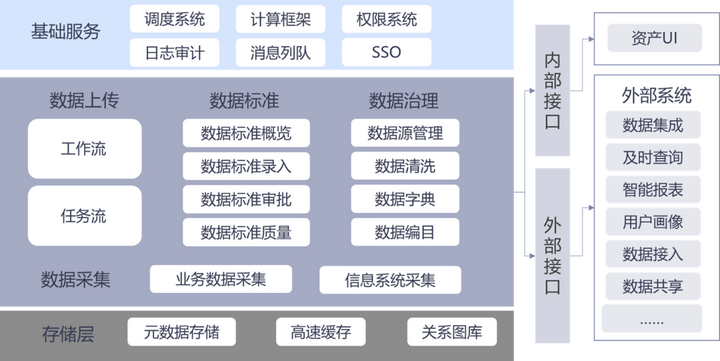
主体建设内容如下:
1.数据标准内置转换:按照标准管理体系梳理各类数据标准,并进行全面深入的可视化展示,提供数据标准概览、标准录入、标准审批、标准质量管理能力。
2.数据采集:提供对业务数据采集任务的分类展示功能,通过数据连接器完成业务数据、设备数据等实时/准实时采集,通过设定的数据传输方式、存储地址、数据字段处理等,根据采集频次自动采集。
3.数据治理:具备数据源管理、数据质量、数据清洗、数据字典、数据编目等功能,能够有效与原有业务系统或标准库进行对接。
4.数据调度:通过数据统一监控调度,管理数据流与任务流执行情况。调度中心负责调度上传数据任务,支持任务定制、上线、调度频率等相关配置,及调度记录、执行日志的查看能力。
5.数据应用:基于标准化数据治理结果,提供数据多维分析和应用模块构建,结合业务实现融合应用,支持各类图表可视化分析与展示大屏,全局性展现数据管理与应用成效。

02 大型园区数据资产管理
数字化园区管理场景多、且需求碎片化,对业务系统定制化更高。经过长期分散化系统建设和数据积累,大多面临数据资源分散、数据权属不清晰、数据难收/未收等问题,对园区内的企业、人员、设备等数据的归集整理和使用的需求更迫切。
案例2 西部某大型开发区数据中台
西部某大型开发区当前正在推动新一批数字转型实施,培育一批数字标杆场景应用,打造一个数字产业聚集区,旨在通过数据要素与生产要素的结合,推动产业数字化、数字产业化。
本次核心是建设覆盖园区全域数字化场景的公共服务平台。数据中台作为其中重要组成部分,将为园区业务构建、经营管理、企业服务、生产发展等提供底层数据服务能力。
数据中台提供数据接入、清洗、治理、分析、开放等一站式底层能力,还支持多租户、日志审计、加解密等数据安全管控,同样能够涵盖全过程数据治理能力,具备数据血缘分析和质量报告自动生成等亮点功能,并打造统一开放的API工厂实现数据共享,为上层应用的多元化使用奠定基础。

主体建设内容如下:
1.数据专题库:汇聚覆盖综合安全、生产安全、物联感知、人力等相关数据作为数据源。按照不同业务属性将数据分类形成产业主题库、政府主题库、企业主题库,并抽象其中的关键指标信息集聚作为指标专题库。
2.数据仓库:建设源数据层(ODS)、标准数据层(STD)、数据模型层(DWD)、数据集市层(DM)四层数据仓库,层层递进,完成数据的拉宽、升维处理,为主题库的建设提供逻辑框架。
3.共享交换:依据平台共享交换能力,对外开放数据服务接口,便于各级委办局查询相关信息,涵盖生产安全、数字综治及相关分析指标等。
4.指标建设:最后按照业务需要建设业务要素和业务场景专题库,对数据进行进一步深度计算、分析、融合,抽象出可以反映区域产业发展和政府公共服务类数据指标,为相关部门领导制定安全发展政策提供数据支撑。

03 政务数据治理
政务领域对数据治理和共享使用有着更为严格的要求,国家和各地区都有相应的政务大数据治理体系顶层设计及治理实施规范,实施政务数据的有效治理是推进“数字政府治理”的基础,是发挥政务数据要素价值的必要条件。
案例3城市生命线数据治理
正如其名,城市生命线包括燃气、桥梁、排水(排水防涝、污水)、供水、道路、 综合管廊、第三方施工等影响城市建设和发展的关键基础设施。
某市政园林局为提升城市基础设施安全运行智慧监管能力,规划构建城市生命线数据能力中心成为必要基础和前提,是数字化层面上的基础设施。
本次目标是以构建城市生命线数据库为核心,汇聚相关权属单位数据,依托数据库开展数据治理与分析,为基础设施运行监管提供更有效的支撑。
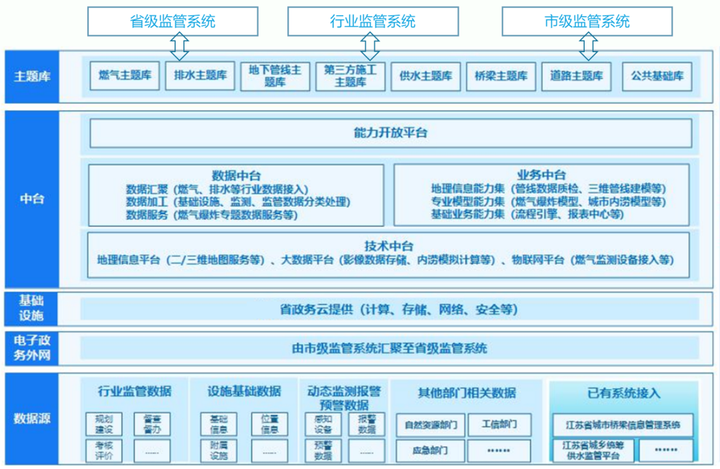
主体建设内容如下:
1.数据库设计:从数据字典设计、汇聚整合、清洗转换、数据治理的角度,设定数据库设计原则,整体上分为:归集库、主题库、专题库。
2.数据汇集:建立数据采集规范,建立数据模型编码标准完成对数据的分域分类管理,汇聚多源数据,满足按需接入、分类传输、更新同步、传输安全等要求。
3.数据加工转换:为保障进入归集库的数据能满足主题库和专题库的使用需求,对数据开展标准化分析加工工作,将数据转换成标准结构,提升数据质量标准。
4.数据治理:对汇集的数据进行质量评估、规范化处理以及数据全生命周期管理,例如实现对图片等形式数据进行结构化处理,对不同设施的坐标系进行转换,多档案ID关联、完整性校验、数据命名规范等。
5.数据发布:对治理后的各类生命线数据面向省级、市级相关监管系统进行发布共享。
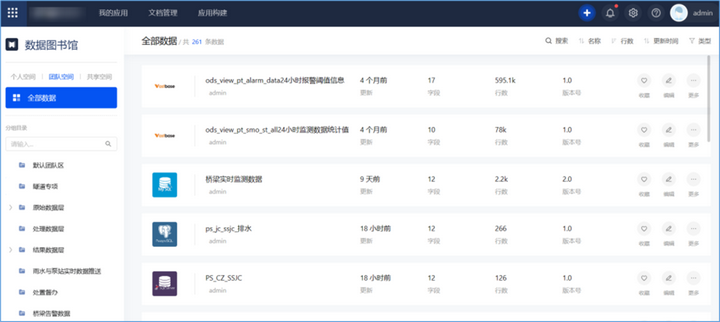
数据治理是一套涉及数据标准、质量、分类、共享、安全等多方面的数据管理方法,在不同场景下数据管理需求不尽相同,但数据治理核心逻辑是一致的。
数睿数据打造一体化的数据治理解决方案,覆盖数据全生命周期的一站式数据管理能力。以数据规划为基础,为数据治理提供明确的战略方向和实施路径,提供统一的数据标准、流程和策略,促进数据资产的整合、共享和利用。确保数据治理项目能够满足组织的业务需求和目标。
数睿数据助力推动“数据要素X”行动,提升行业数据资源开发利用能力,数据驱动行业数字化高质量发展。
这篇关于数智先锋 | 多场景数据治理案例,释放数据要素生产力的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





