本文主要是介绍代码随想录算法训练营第十三天:树的认知(补五一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
代码随想录算法训练营第十三天:树的认知(补五一)
二叉树的递归遍历
#算法公开课
《代码随想录》算法视频公开课 ****(opens new window)**** :每次写递归都要靠直觉? 这次带你学透二叉树的递归遍历! ****(opens new window)**** ,相信结合视频再看本篇题解,更有助于大家对本题的理解。
#思路
这次我们要好好谈一谈递归,为什么很多同学看递归算法都是“一看就会,一写就废”。
主要是对递归不成体系,没有方法论,每次写递归算法 ,都是靠玄学来写代码,代码能不能编过都靠运气。
本篇将介绍前后中序的递归写法,一些同学可能会感觉很简单,其实不然,我们要通过简单题目把方法论确定下来,有了方法论,后面才能应付复杂的递归。
这里帮助大家确定下来递归算法的三个要素。每次写递归,都按照这三要素来写,可以保证大家写出正确的递归算法!
-
确定递归函数的参数和返回值: 确定哪些参数是递归的过程中需要处理的,那么就在递归函数里加上这个参数, 并且还要明确每次递归的返回值是什么进而确定递归函数的返回类型。
-
确定终止条件: 写完了递归算法, 运行的时候,经常会遇到栈溢出的错误,就是没写终止条件或者终止条件写的不对,操作系统也是用一个栈的结构来保存每一层递归的信息,如果递归没有终止,操作系统的内存栈必然就会溢出。
-
确定单层递归的逻辑: 确定每一层递归需要处理的信息。在这里也就会重复调用自己来实现递归的过程。
以下以前序遍历为例:
- 确定递归函数的参数和返回值:因为要打印出前序遍历节点的数值,所以参数里需要传入vector来放节点的数值,除了这一点就不需要再处理什么数据了也不需要有返回值,所以递归函数返回类型就是void,代码如下:
void traversal(TreeNode* cur, vector<int>& vec)- 确定终止条件:在递归的过程中,如何算是递归结束了呢,当然是当前遍历的节点是空了,那么本层递归就要结束了,所以如果当前遍历的这个节点是空,就直接return,代码如下:
if (cur == NULL) return;- 确定单层递归的逻辑:前序遍历是中左右的循序,所以在单层递归的逻辑,是要先取中节点的数值,代码如下:
vec.push_back(cur->val); // 中
traversal(cur->left, vec); // 左
traversal(cur->right, vec); // 右
单层递归的逻辑就是按照中左右的顺序来处理的,这样二叉树的前序遍历,基本就写完了,再看一下完整代码:
class Solution {
public:void traversal(TreeNode* cur, vector<int>& vec) {if (cur == NULL) return;vec.push_back(cur->val); // 中traversal(cur->left, vec); // 左traversal(cur->right, vec); // 右}vector<int> preorderTraversal(TreeNode* root) {vector<int> result;traversal(root, result);return result;}
};
那么前序遍历写出来之后,中序和后序遍历就不难理解了,代码如下:
中序遍历:
void traversal(TreeNode* cur, vector<int>& vec) {if (cur == NULL) return;traversal(cur->left, vec); // 左vec.push_back(cur->val); // 中traversal(cur->right, vec); // 右
}
后序遍历:
void traversal(TreeNode* cur, vector<int>& vec) {if (cur == NULL) return;traversal(cur->left, vec); // 左traversal(cur->right, vec); // 右vec.push_back(cur->val); // 中
}
二叉树的迭代遍历
#算法公开课
《代码随想录》算法视频公开课 **(opens new window)** :
- 写出二叉树的非递归遍历很难么?(前序和后序)(opens new window)
- 写出二叉树的非递归遍历很难么?(中序)) ****(opens new window)****相信结合视频在看本篇题解,更有助于大家对本题的理解。
看完本篇大家可以使用迭代法,再重新解决如下三道leetcode上的题目:
- 144.二叉树的前序遍历(opens new window)
- 94.二叉树的中序遍历(opens new window)
- 145.二叉树的后序遍历(opens new window)
#思路
为什么可以用迭代法(非递归的方式)来实现二叉树的前后中序遍历呢?
我们在栈与队列:匹配问题都是栈的强项 **(opens new window)** 中提到了,递归的实现就是:每一次递归调用都会把函数的局部变量、参数值和返回地址等压入调用栈中,然后递归返回的时候,从栈顶弹出上一次递归的各项参数,所以这就是递归为什么可以返回上一层位置的原因。
此时大家应该知道我们用栈也可以是实现二叉树的前后中序遍历了。
#前序遍历(迭代法)
我们先看一下前序遍历。
前序遍历是中左右,每次先处理的是中间节点,那么先将根节点放入栈中,然后将右孩子加入栈,再加入左孩子。
为什么要先加入 右孩子,再加入左孩子呢? 因为这样出栈的时候才是中左右的顺序。
动画如下:

不难写出如下代码: (注意代码中空节点不入栈)
class Solution {
public:vector<int> preorderTraversal (TreeNode* root){stack<TreeNode*> st;vector<int> result ;if (root == NULL)return result;st.push(root);while(!st.empty()){TreeNode* node = st.top();st.pop();result.push_back (node->val);if (root->right)st.push(root->right);if (root->left)st.push(root->left);}return result;}
};
上述超内存。下面代码可以通过
class Solution {
public:vector<int> preorderTraversal(TreeNode* root) {vector<int> res;if (root == nullptr) {return res;}stack<TreeNode*> stk;TreeNode* node = root;while (!stk.empty() || node != nullptr) {while (node != nullptr) {res.emplace_back(node->val);stk.emplace(node);node = node->left;}node = stk.top();stk.pop();node = node->right;}return res;}
};此时会发现貌似使用迭代法写出前序遍历并不难,确实不难。
此时是不是想改一点前序遍历代码顺序就把中序遍历搞出来了?
其实还真不行!
但接下来,再用迭代法写中序遍历的时候,会发现套路又不一样了,目前的前序遍历的逻辑无法直接应用到中序遍历上。
#中序遍历(迭代法)
为了解释清楚,我说明一下 刚刚在迭代的过程中,其实我们有两个操作:
- 处理:将元素放进result数组中
- 访问:遍历节点
分析一下为什么刚刚写的前序遍历的代码,不能和中序遍历通用呢,因为前序遍历的顺序是中左右,先访问的元素是中间节点,要处理的元素也是中间节点,所以刚刚才能写出相对简洁的代码,因为要访问的元素和要处理的元素顺序是一致的,都是中间节点。
那么再看看中序遍历,中序遍历是左中右,先访问的是二叉树顶部的节点,然后一层一层向下访问,直到到达树左面的最底部,再开始处理节点(也就是在把节点的数值放进result数组中),这就造成了处理顺序和访问顺序是不一致的。
那么在使用迭代法写中序遍历,就需要借用指针的遍历来帮助访问节点,栈则用来处理节点上的元素。
动画如下:
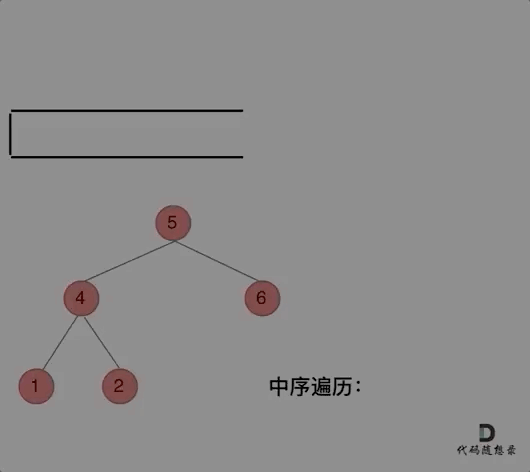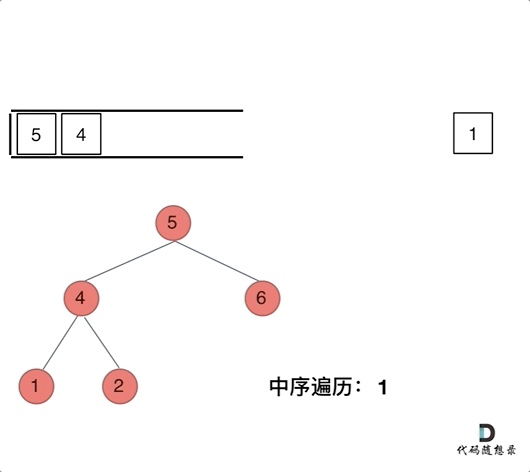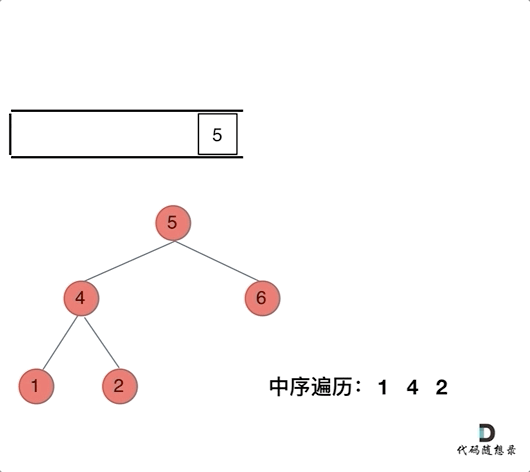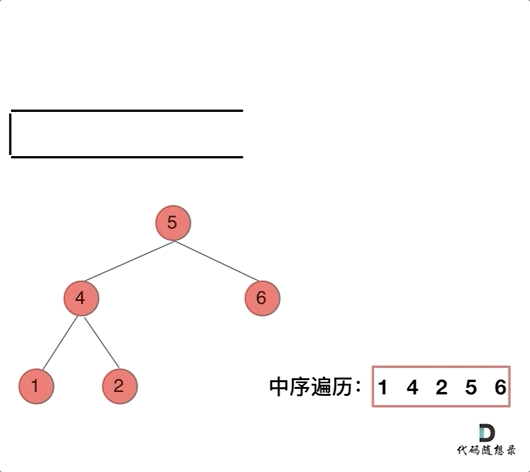
class Solution{
public:vector<int> inorderTraversal(TreeNode* root){vector<int> result;stack<TreeNode*> st;TreeNode* cur = root;while(cur != NULL || !st.empty()){if (cur != NULL){st.push(cur);cur = cur->left;}else {cur = st.top();st.pop();result.push_back(cur->val);cur = cur->right;}}return result;}
};后序遍历(迭代法)
再来看后序遍历,先序遍历是中左右,后续遍历是左右中,那么我们只需要调整一下先序遍历的代码顺序,就变成中右左的遍历顺序,然后在反转result数组,输出的结果顺序就是左右中了,如下图:

所以后序遍历只需要前序遍历的代码稍作修改就可以了,代码如下:
class Solution {
public:vector<int> postorderTraversal(TreeNode* root) {stack<TreeNode*> st;vector<int> result;if (root == NULL) return result;st.push(root);while (!st.empty()) {TreeNode* node = st.top();st.pop();result.push_back(node->val);if (node->left) st.push(node->left); // 相对于前序遍历,这更改一下入栈顺序 (空节点不入栈)if (node->right) st.push(node->right); // 空节点不入栈}reverse(result.begin(), result.end()); // 将结果反转之后就是左右中的顺序了return result;}
};#总结
此时我们用迭代法写出了二叉树的前后中序遍历,大家可以看出前序和中序是完全两种代码风格,并不像递归写法那样代码稍做调整,就可以实现前后中序。
这是因为前序遍历中访问节点(遍历节点)和处理节点(将元素放进result数组中)可以同步处理,但是中序就无法做到同步!
上面这句话,可能一些同学不太理解,建议自己亲手用迭代法,先写出来前序,再试试能不能写出中序,就能理解了。
那么问题又来了,难道 二叉树前后中序遍历的迭代法实现,就不能风格统一么(即前序遍历 改变代码顺序就可以实现中序 和 后序)?
当然可以,这种写法,还不是很好理解,我们将在下一篇文章里重点讲解,敬请期待!
Morris 中序遍历
思路与算法
Morris 遍历算法是另一种遍历二叉树的方法,它能将非递归的中序遍历空间复杂度降为 O(1)O(1) O ( 1 ) 。
Morris 遍历算法整体步骤如下(假设当前遍历到的节点为 xxx):
-
如果 xxx 无左孩子,先将 xxx 的值加入答案数组,再访问 xxx 的右孩子,即 x=x.rightx = x.\textit{right} x = x . right。
-
如果 xxx 有左孩子,则找到 xxx 左子树上最右的节点(即左子树中序遍历的最后一个节点, xxx 在中序遍历中的前驱节点),我们记为 predecessor\textit{predecessor} predecessor。根据 predecessor\textit{predecessor} predecessor 的右孩子是否为空,进行如下操作。
- 如果 predecessor\textit{predecessor} predecessor 的右孩子为空,则将其右孩子指向 xxx,然后访问 xxx 的左孩子,即 x=x.leftx = x.\textit{left} x = x . left。
- 如果 predecessor\textit{predecessor} predecessor 的右孩子不为空,则此时其右孩子指向 xxx,说明我们已经遍历完 xxx 的左子树,我们将 predecessor\textit{predecessor} predecessor 的右孩子置空,将 xxx 的值加入答案数组,然后访问 xxx 的右孩子,即 x=x.rightx = x.\textit{right} x = x . right。
其实整个过程我们就多做一步:假设当前遍历到的节点为 xxx,将 xxx 的左子树中最右边的节点的右孩子指向 xxx,这样在左子树遍历完成后我们通过这个指向走回了 xxx,且能通过这个指向知晓我们已经遍历完成了左子树,而不用再通过栈来维护,省去了栈的空间复杂度。
中序遍历演示:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:vector<int> inorderTraversal(TreeNode* root) {
vector <int> res;
TreeNode *predecessor = nullptr;
while(root != nullptr){if (root->left!= nullptr){predecessor = root->left;while(predecessor->right!= nullptr && predecessor->right != root ){predecessor = predecessor->right;}if (predecessor->right == nullptr){predecessor->right = root;root = root->left;}else{res.push_back(root ->val);predecessor->right = nullptr;root = root->right;}}else{res.push_back(root->val);root = root->right;}} return res;}
};
Morris遍历的详细解释+注释版
一些前置知识:
- 前驱节点,如果按照中序遍历访问树,访问的结果为ABC,则称A为B的前驱节点,B为C的前驱节点。
- 前驱节点pre是curr左子树的最右子树(按照中序遍历走一遍就知道了)。
- 由此可知,前驱节点的右子节点一定为空。
主要思想:
树的链接是单向的,从根节点出发,只有通往子节点的单向路程。
中序遍历迭代法的难点就在于,需要先访问当前节点的左子树,才能访问当前节点。
但是只有通往左子树的单向路程,而没有回程路,因此无法进行下去,除非用额外的数据结构记录下回程的路。
在这里可以利用当前节点的前驱节点,建立回程的路,也不需要消耗额外的空间。
根据前置知识的分析,当前节点的前驱节点的右子节点是为空的,因此可以用其保存回程的路。
但是要注意,这是建立在破坏了树的结构的基础上的,因此我们最后还有一步“消除链接”’的步骤,将树的结构还原。
重点过程: 当遍历到当前节点curr时,使用cuur的前驱节点pre
- 标记当前节点是否访问过
- 记录回溯到curr的路径(访问完pre以后,就应该访问curr了)
以下为我们访问curr节点需要做的事儿:
- 访问curr的节点时候,先找其前驱节点pre
- 找到前驱节点pre以后,我们根据其右指针的值,来判断curr的访问状态:
- pre的右子节点为空,说明curr第一次访问,其左子树还没有访问,此时我们应该将其指向curr,并访问curr的左子树
- pre的右子节点指向curr,那么说明这是第二次访问curr了,也就是说其左子树已经访问完了,此时将curr.val加入结果集中
后序遍历:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:void addPath(vector<int> & vec,TreeNode *node){int count = 0;while(node!=nullptr){++count;vec.emplace_back(node->val);node = node->right;}reverse(vec.end() - count,vec.end());}vector<int> postorderTraversal(TreeNode* root) {
vector<int>res;
if (root == nullptr){return res;
}
TreeNode *p1 = root,*p2= =nullptr;
while(p1 != nullptr){p2 = p1->left;if(p2 != nullptr){while(p2->right != nullptr && p2->right != p1){p2 = p2 -> right;}if (p2 ->right ==nullptr){p2 ->right = p1;p1 = p1->left;continue;}else{p2->right = nullptr;addPath(res,p1->left);}}p1 = p1->right;
}
addPath(res,root);
return res;}
};
下面是上述代码的详细注释和解释。这段代码实现了对二叉树的后序遍历(left-right-root)算法。 一般后序遍历有递归和迭代两种实现方法,这个解决方案使用了迭代方式,并利用了Morris遍历算法的思想,该算法用以减少空间复杂度至O(1),通过修改树的结构来记录访问路径。具体到这份代码,它实现了一种特殊方式的后序遍历。
struct TreeNode {int val;TreeNode *left;TreeNode *right;TreeNode() : val(0), left(nullptr), right(nullptr) {}TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
};class Solution {
public:// 将从当前节点到最右子节点的路径逆序加入到结果数组中void addPath(vector<int> & vec,TreeNode *node){int count = 0;while(node != nullptr){++count; // 记录路径长度,以便逆序vec.emplace_back(node->val); // 加入当前节点值node = node->right; // 移动到右子节点}reverse(vec.end() - count,vec.end()); // 将刚刚记录的路径逆序}vector<int> postorderTraversal(TreeNode* root) {vector<int>res;if (root == nullptr){ // 如果根节点是空,则直接返回空结果return res;}TreeNode *p1 = root,*p2 = nullptr;while(p1 != nullptr){p2 = p1->left;if(p2 != nullptr){// 寻找左子树中的最右节点,即当前p1子树的前驱while(p2->right != nullptr && p2->right != p1){p2 = p2 -> right;}if (p2 ->right == nullptr){// 建立临时的指向p1的链接,方便后面返回到p1并访问右子树p2 ->right = p1;p1 = p1->left; // 继续遍历左子树continue;}else{// 如果前驱的right已经指向了p1,说明左子树已经访问完,需要断开链接p2->right = nullptr;// 将从当前节点到最右子节点的路径逆序加入到结果数组中addPath(res,p1->left);}}p1 = p1->right; // 访问右子树}// 由于根节点最后被访问,所以在最后将从根节点开始的直到最右节点的路径逆序加入。addPath(res,root);return res;}
};
这段代码通过定义addPath函数来实现将一段路径逆序加入结果数组中。此函数的关键应用是在遍历到左子树的最右侧时,可以按后序遍历的要求实际上逆序地处理节点(因为原本是直接通过right指针向右访问,但逆序后实际上形成了从底部向上访问左子树的每个节点的效果,符合后序遍历的访问顺序)。整体算法在处理每个左子节点的时候,尝试找到它的前驱节点,如果未被访问,则建立一条临时的回溯链接,一旦找到或重新访问到,就删除这条链接,使用addPath函数逆序地加入这部分节点的值到结果中,最后处理右子节点。整个过程中不使用递归或栈,而是通过修改原树结构来达到访问的目的,最终还原树的结构。 这种方法特别之处在于它利用了树的结构作为遍历过程中的“栈”,通过修改节点的right指针来进行遍历的回溯,从而实现了空间复杂度为O(1)的后序遍历。这是一种非常巧妙且效率高的遍历方式,特别适用于要求低空间复杂度的场景。
二叉树的统一迭代法
#思路
此时我们在二叉树:一入递归深似海,从此offer是路人 **(opens new window)** 中用递归的方式,实现了二叉树前中后序的遍历。
在二叉树:听说递归能做的,栈也能做! **(opens new window)** 中用栈实现了二叉树前后中序的迭代遍历(非递归)。
之后我们发现迭代法实现的先中后序,其实风格也不是那么统一,除了先序和后序,有关联,中序完全就是另一个风格了,一会用栈遍历,一会又用指针来遍历。
实践过的同学,也会发现使用迭代法实现先中后序遍历,很难写出统一的代码,不像是递归法,实现了其中的一种遍历方式,其他两种只要稍稍改一下节点顺序就可以了。
其实针对三种遍历方式,使用迭代法是可以写出统一风格的代码!
重头戏来了,接下来介绍一下统一写法。
我们以中序遍历为例,在二叉树:听说递归能做的,栈也能做! **(opens new window)** 中提到说使用栈的话,无法同时解决访问节点(遍历节点)和处理节点(将元素放进结果集)不一致的情况。
那我们就将访问的节点放入栈中,把要处理的节点也放入栈中但是要做标记。
如何标记呢,就是要处理的节点放入栈之后,紧接着放入一个空指针作为标记。 这种方法也可以叫做标记法。
迭代法中序遍历
中序遍历代码如下:(详细注释)
class Solution {
public:vector<int> inorderTraversal(TreeNode* root) {vector<int> result;stack<TreeNode*> st;if (root != NULL) st.push(root);while (!st.empty()) {TreeNode* node = st.top();if (node != NULL) {st.pop(); // 将该节点弹出,避免重复操作,下面再将右中左节点添加到栈中if (node->right) st.push(node->right); // 添加右节点(空节点不入栈)st.push(node); // 添加中节点st.push(NULL); // 中节点访问过,但是还没有处理,加入空节点做为标记。if (node->left) st.push(node->left); // 添加左节点(空节点不入栈)} else { // 只有遇到空节点的时候,才将下一个节点放进结果集st.pop(); // 将空节点弹出node = st.top(); // 重新取出栈中元素st.pop();result.push_back(node->val); // 加入到结果集}}return result;}
};
看代码有点抽象我们来看一下动画(中序遍历):
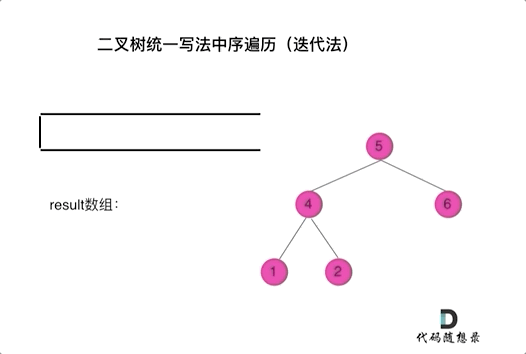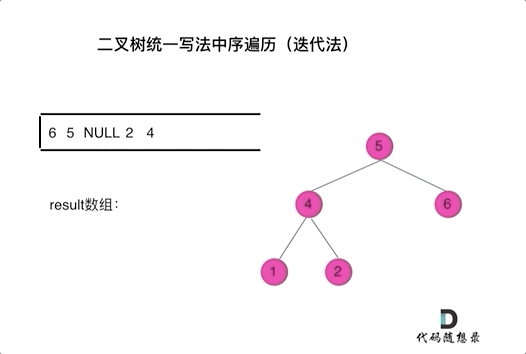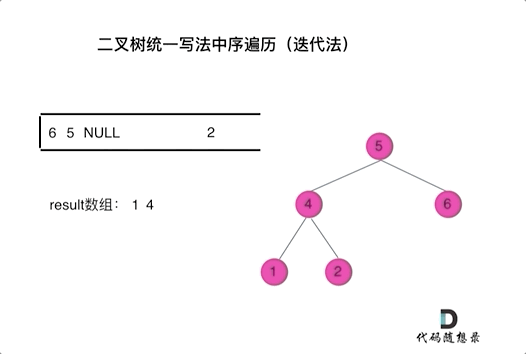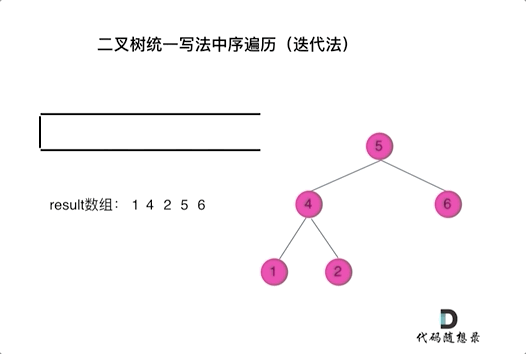
动画中,result数组就是最终结果集。
可以看出我们将访问的节点直接加入到栈中,但如果是处理的节点则后面放入一个空节点, 这样只有空节点弹出的时候,才将下一个节点放进结果集。
此时我们再来看前序遍历代码。
#迭代法前序遍历
迭代法前序遍历代码如下: (注意此时我们和中序遍历相比仅仅改变了两行代码的顺序)
class Solution {
public:vector<int> preorderTraversal(TreeNode* root) {vector<int> result;stack<TreeNode*> st;if (root != NULL) st.push(root);while (!st.empty()) {TreeNode* node = st.top();if (node != NULL) {st.pop();if (node->right) st.push(node->right); // 右if (node->left) st.push(node->left); // 左st.push(node); // 中st.push(NULL);} else {st.pop();node = st.top();st.pop();result.push_back(node->val);}}return result;}
};
#迭代法后序遍历
后续遍历代码如下: (注意此时我们和中序遍历相比仅仅改变了两行代码的顺序)
class Solution {
public:vector<int> postorderTraversal(TreeNode* root) {vector<int> result;stack<TreeNode*> st;if (root != NULL) st.push(root);while (!st.empty()) {TreeNode* node = st.top();if (node != NULL) {st.pop();st.push(node); // 中st.push(NULL);if (node->right) st.push(node->right); // 右if (node->left) st.push(node->left); // 左} else {st.pop();node = st.top();st.pop();result.push_back(node->val);}}return result;}
};
#总结
此时我们写出了统一风格的迭代法,不用在纠结于前序写出来了,中序写不出来的情况了。
但是统一风格的迭代法并不好理解,而且想在面试直接写出来还有难度的。
所以大家根据自己的个人喜好,对于二叉树的前中后序遍历,选择一种自己容易理解的递归和迭代法。
这篇关于代码随想录算法训练营第十三天:树的认知(补五一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





