本文主要是介绍统一大型语言模型和知识图谱:路线图,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【摘要】
大型语言模型(LLM),如ChatGPT和GPT4,由于其涌现能力和泛化性,正在自然语言处理和人工智能领域掀起新的浪潮。然而,LLM是黑箱模型,通常无法捕捉和获取事实知识。相反,知识图谱(KGs),例如维基百科和华普,是显式存储丰富事实知识的结构化知识模型。KGs可以通过为推理和可解释性提供外部知识来增强LLM。同时,KGs很难从本质上构建和演化,这对KGs中现有的生成新事实和表示未知知识的方法提出了挑战。因此,将LLM和KGs统一在一起并同时利用它们的优势是相辅相成的。在本文中,我们提出了LLM和KGs统一的前瞻性路线图。我们的路线图由三个通用框架组成,即:1)KG增强的LLM,它在LLM的预训练和推理阶段纳入了KG,或者是为了增强对LLM所学知识的理解;2) LLM增强的KG,利用LLM执行不同的KG任务,如嵌入、补全、构建、图到文(graph-to-text)生成和问答;以及3)协同LLM+KGs,其中LLM和KGs扮演着平等的角色,并以互利的方式工作,以增强LLM和KG,实现由数据和知识驱动的双向推理。我们在路线图中回顾和总结了这三个框架内的现有努力,并确定了它们未来的研究方向。
【笔记】
1【Introduction】
(1)KGs vs LLMs

(2)Contribution
路线图。我们提出了整合LLMs和KGs的前瞻性路线图。我们的路线图由三个统一LLM和KG的通用框架组成,即KG增强的LLM、LLM增强的KG和协同的LLM+KG,为这两种不同但互补的技术的统一提供了指导方针。
分类和审查。对于我们路线图的每个整合框架,我们提出了统一LLMs和KGs的详细分类和新的研究分类法。在每个类别中,我们从不同的整合策略和任务的角度回顾了研究,这为每个框架提供了更多的见解。
新进展的报道。我们涵盖LLMs和KGs的先进技术。我们包括对最先进的LLMs(如ChatGPT和GPT-4)以及新的KGs(如多模态知识图谱)的讨论。
挑战和未来方向概述。我们强调了现有研究中的挑战,并提出了几个有前景的未来研究方向。
2【Background】
(1)LLMs
现有的LLMs可以分为
1)Encoder-only LLMs:
仅编码器LLM,如BERT[1]、ALBERT[51]、RoBERTa[2]和ELECTRA[52],需要添加额外的预测头来解决下游任务。
2)Encoder-Decoder LLMs:
例如,T5[3]是通过掩蔽和预测掩蔽词的跨度来预训练的。UL2[55]统一了几个训练目标,例如不同的掩蔽跨度和掩蔽频率。编码器-解码器LLM(例如T0[56]、ST-MoE[57]和GLM-130B[58])能够直接解决基于某些上下文生成句子的任务,例如总结、翻译和问答。
3)Decoder-only LLMs:
这些模型的训练范式是预测句子中的下一个单词。
Prompt engineering:
提示可以包含几个元素,即1)指令(instruction)、2)上下文(context)和3)输入文本(input text)。指令是指示模型执行特定任务的短句。上下文为输入文本或少样本示例提供上下文。输入文本是需要由模型处理的文本。

(2)KGs
现有的KGs可以分为
1) 百科KGs:
Wikidata[20]是使用最广泛的百科全书式知识图之一,它包含了从维基百科上的文章中提取的各种知识。其他典型的百科全书式知识图,如Freebase[67]、Dbpedia[68]和YAGO[31],也源自维基百科。此外,NELL[32]是一个不断改进的百科全书式知识图,它自动从网络中提取知识,并随着时间的推移使用这些知识来提高其性能。有几种百科全书式的知识图谱以英语以外的语言提供,如CN-DBpedia[69]和Vikidia[70]。最大的知识图名为knowledge Occean(KO)7,目前包含487843636个实体和1731158349个中英文关系。
2)常识KGs:
ConceptNet[72]包含了广泛的常识性概念和关系,可以帮助计算机理解人们使用的单词的含义。ATOMIC[73]、[74]和ASER[75]关注事件之间的因果效应,可用于常识推理。其他一些常识性知识图,如TransOMCS[76]和CausalBanK[77],是自动构建的,以提供常识性知识。
3)领域特定KGs:
例如,UMLS[78]是医学领域中的特定领域知识图谱,它包含生物医学概念及其关系。
4)多模态KGs:
例如,IMGpedia[85]、MMKG[86]和Richpedia[87]将文本和图像信息合并到知识图谱中。这些知识图谱可用于各种多模态任务,如图像文本匹配[88]、视觉问答[89]和推荐[90]。

Application:

3【Roadmap & Categorization】
- Roadmap


4【KG-enhanced LLMs】

KG增强的LLM预训练
以往将KGs集成到大型语言模型中的工作可分为三部分:1)将KGs整合到训练目标中,2)将KGs整合到LLM输入中,3)通过额外的融合模块整合KGs。
1)将KGs整合到训练目标
这一类别的研究工作侧重于设计新颖的知识意识培训目标。一个直观的想法是在预培训目标中暴露更多的知识实体。GLM[105]利用知识图结构来分配掩蔽概率。具体来说,在一定数量的跳内可以到达的实体被认为是学习中最重要的实体,在预训练时给定一个更高的掩蔽概率。
此外,E-BERT[106]进一步控制了令牌级和实体级训练损失之间的平衡。训练损失值被用作令牌和实体的学习过程的指示,该学习过程动态地确定它们在下一个训练时期的比率。SKEP[104]也遵循类似的融合,在LLM预训练期间注入情感知识。SKEP首先通过利用PMI以及预定义的种子情绪词集合来确定具有积极情绪和消极情绪的词。然后,它将更高的掩蔽概率分配给单词掩蔽目标中识别的情感单词。
另一路工作明确地利用了与知识和输入文本的联系。如图9所示,ERNIE[91]提出了一种新的词-实体对齐训练目标作为预训练目标。具体来说,ERNIE将文本中提到的句子和相应的实体都输入到LLM中,然后训练LLM来预测文本标记和知识图中实体之间的对齐链接。类似地,KALM[92]通过结合实体嵌入来增强输入令牌,并且除了仅令牌的预训练目标之外还包括实体预测预训练任务。这种方法旨在提高LLM获取与实体相关知识的能力。最后,KEPLER[131]将知识图嵌入训练目标和掩蔽令牌预训练目标直接应用到基于共享变换器的编码器中。确定性LLM[107]专注于预训练语言模型,以获取确定性事实知识。它只掩盖了具有确定性实体的跨度作为问题,并引入了额外的线索对比学习和线索分类目标。WKLM[109]首先用其他相同类型的实体替换文本中的实体,然后将它们馈送到LLM中。对模型进行进一步的预训练,以区分实体是否已被替换。

2)将KGs整合到LLM输入

为了解决知识噪声问题,K-BERT[36]采取了第一步,通过可见矩阵将知识三元组注入句子中,其中只有知识实体可以访问知识三元组信息,而句子中的标记只能在自注意模块中看到彼此。为了进一步减少知识噪声,Colake[110]提出了一个统一的单词知识图(如图10所示),其中输入句子中的标记形成了一个完全连接的单词图,其中与知识实体对齐的标记与其相邻实体连接。
上述方法确实可以为LLM注入大量的知识。然而,他们大多关注热门实体,而忽略了低频率和长尾实体。DkLLM[111]旨在改进针对这些实体的LLM表示。DkLLM首先提出了一种新的测量方法来确定长尾实体,然后用伪令牌嵌入来替换文本中的这些选定实体,作为大型语言模型的新输入。此外,Dict-BERT[112]建议利用外部词典来解决这个问题。具体而言,Dict-BERT通过在输入文本的末尾附加字典中的稀有词定义来提高稀有词的表示质量,并训练语言模型以局部对齐输入句子和字典定义中的稀有单词表示,以及区分输入文本和定义是否正确映射。、
3)通过额外的融合模块整合KGs

如图11所示,ERNIE提出了一种文本知识双编码器架构,其中T-encoder首先对输入句子进行编码,然后使用T-encoder的文本表示对知识图谱进行处理。
BERT-MK[113]采用了类似的双编码器架构,但在LLMs的预训练过程中引入了知识编码器组件中相邻实体的额外信息。
然而,KG中的一些相邻实体可能与输入文本无关,导致额外的冗余和噪声。CokeBERT[116]专注于这个问题,并提出了一个基于gnn的模块,使用输入文本过滤掉不相关的KG实体。
JAKET [114] 建议融合大型语言模型中间的实体信息。模型的前半部分分别处理输入文本和知识实体序列。然后,将文本和实体的输出组合在一起。具体来说,实体表示被添加到文本表示的相应位置,这些位置由模型的后半部分进一步处理。K-adapters[115]通过适配器融合语言和事实知识,适配器只在变压器层中间添加可训练的多层感知,而大型语言模型的现有参数在知识预训练阶段保持冻结。这样的适配器是相互独立的,可以并行训练。
KG增强的LLM推理
大量工作研究保持知识空间和文本空间分开,并在推理时注入知识。这些方法主要关注问答 (QA) 任务,因为 QA 要求模型捕获文本语义含义和最新的现实世界知识。
1)动态知识融合
一种简单的方法是利用双塔架构,其中一个分离的模块处理文本输入,另一个处理相关的知识图谱输入[133]。然而,这种方法缺乏文本和知识之间的交互。因此,KagNet [94] 提出首先对输入 KG 进行编码,然后增强输入文本表示。相比之下,MHGRN[134]使用输入文本的最终LLM输出来指导KG上的推理过程。
然而,它们都只设计了文本和 KG 之间的单向交互。为了解决这个问题,QA-GNN [117] 提出使用基于 GNN 的模型通过消息传递联合推理输入上下文和 KG 信息。具体来说,QA-GNN 通过池化操作将输入文本信息表示为特殊节点,并将该节点与 KG 中的其他实体连接起来。然而,文本输入仅汇集到单个密集向量中,限制了信息融合的性能。JointLK [118] 然后提出了一个框架,该框架通过 LM-to-KG 和 KG-to-LM 双向注意机制在文本输入和任何 KG 实体之间的细粒度交互。

如图12所示,在所有文本tokens和 KG 实体上计算成对点积分数,分别计算双向注意力分数。此外,在每个关节 LK 层,KG 也是基于注意力分数动态剪枝的,以允许后面的层专注于更重要的子 KG 结构。尽管有效,但在 JointLK 中,输入文本和 KG 之间的融合过程仍然使用最终的 LLM 输出作为输入文本表示。GreaseLM[119]设计了llm每一层输入文本标记和KG实体之间的深度和丰富交互。架构和融合方法大多类似于第 4.1.3 节中讨论的 ERNIE [91],只是 GreaseLM 不使用纯文本 T-encoder来处理输入文本。
2)检索增强的知识融合

与上述将所有知识存储在参数中的方法不同,如图13所示,RAG[93]提出将非参数模块和参数模块相结合来处理外部知识。给定输入文本,RAG首先通过MIPS在非参数模块中搜索相关的KG,以获得多个文档。然后,RAG将这些文档视为隐藏变量z,并将它们作为附加上下文信息提供给Seq2Seq LLM增强的输出生成器,。研究表明,在不同的生成步骤中,使用不同的检索文档作为条件比仅使用单个文档来指导整个生成过程要好。实验结果表明,在开放域QA中,RAG优于其他仅参数和仅非参数的基线模型。与其他仅参数的基线相比,RAG还可以生成更具体、更多样、更真实的文本。
Story-fragments[122]通过添加一个额外的模块来确定显著的知识实体并将其融合到生成器中以改进架构生成长故事的能力。EMAT[123]通过将外部知识编码到键值存储器中并利用快速最大内积搜索进行存储器查询,进一步提高了这种系统的效率。REALM[121]提出了一种新的知识检索器,以帮助模型在预训练阶段从大型语料库中检索和处理文档,并成功地提高了开放领域问答的性能。KGLM[120]使用当前上下文从知识图中选择事实来生成事实句子。在外部知识图的帮助下,KGLM可以使用领域外的单词或短语来描述事实。
KG增强的LLM可解释性
1)用于LLMs探测的KGs

LAMA[14]是第一个通过使用KGs来探究LLM中的知识的工作。如图14所示,LAMA首先通过预定义的提示模板将KGs中的事实转换为完形填空语句,然后使用LLM来预测缺失的实体。预测结果用于评估LLM中存储的知识。
然而,LAMA忽略了提示不恰当的事实。例如,提示“Obama worked as a __”可能比“Obama is a __ by profession”更有利于语言模型对空白的预测。因此,LPAQA[124]提出了一种基于挖掘和转述的方法,以自动生成高质量和多样化的提示,从而更准确地评估语言模型中包含的知识。此外,Adolphs等人[126]试图使用示例使语言模型理解查询,并且实验在T-REx数据上获得了大量BERT的实质性改进。与使用手动定义的提示模板不同,Autoprompt[125]提出了一种自动方法,该方法基于梯度引导搜索来创建提示。
BioLAMA[135]和MedLAMA[127]没有使用百科全书式和常识性的知识图谱来探究一般知识,而是使用医学知识图谱来探索LLM中的医学知识。Alex等人[128]调查LLM保留不太流行的事实知识的能力。他们从wikidata知识图谱中选择非流行的事实,这些知识图谱具有低频率点击的实体。然后将这些事实用于评估,结果表明LLM在使用这些知识时遇到了困难,而缩放并不能显著提高尾部事实知识的记忆。
2)用于LLMs分析的KGs
用于预训练语言模型(LLM)分析的知识图谱(KGs)旨在回答以下问题,如“LLM如何生成结果?”和“LLM中的功能和结构如何工作?”。为了分析LLM的推理过程,如图15所示,KagNet[38]和QA-GNN[117]使LLM在每个推理步骤产生的结果接地到知识图谱。这样,LLM的推理过程可以通过从KGs中提取图结构来解释。

为了解释LLM的训练,Swamy等人[129]在预训练期间采用语言模型来生成知识图。LLM在训练期间获得的知识可以通过幼儿园的事实显式地揭示出来。为了探索隐式知识如何存储在LLM的参数中,Dai等人[39]提出了知识神经元的概念。具体而言,所识别的知识神经元的激活与知识表达高度相关。因此,他们通过抑制和放大知识神经元来探索每个神经元所代表的知识和事实。
5【LLM-augmented KGs】

LLM增强的KG嵌入
(1)LLM作为文本编码器

传统的知识图谱嵌入方法主要依靠KGs的结构信息来优化定义在嵌入上的评分函数(如TransE[25]和DisMult[183]。然而,由于结构连通性有限,这些方法在表示看不见的实体和长尾关系方面往往不足[184],[185]。为了解决这个问题,如图 16 所示,最近的研究采用 LLM 通过对实体和关系的文本描述进行编码来丰富 KG 的表示。
Pretrain-KGE[96]是一种具有代表性的方法,它遵循图16所示的框架。给定一个来自KGs的三元组(h, r, t),它首先使用LLM编码器将实体h, t和关系r的文本描述编码为表示:

Pretrain-KGE 在实验中使用 BERT 作为 LLM 编码器。然后,将初始嵌入输入到KGE模型中,生成最终的嵌入Vh、Vr和Vt。在KGE训练阶段,他们通过遵循标准的KGE损失函数来优化KGE模型:

γ是一个间隔(margin)超参数,v'_{h}, v'_{r}和v'_{t}是负样本。通过这种方式,KGE 模型可以学习足够的结构信息,同时保留 LLM 的部分知识,以实现更好的知识图嵌入。
KEPLER[40] 为知识嵌入和预训练的语言模型提供了一个统一的模型。该模型不仅使用强大的LLM生成有效的文本增强知识嵌入,也无缝地将事实知识集成到LLM中。
Nayyyeri等人[136]使用LLM生成世界级(world-level)、句子级(sentence-level)和文档级(document-level)表示。它们通过 Dihedron 和 4D 超复数的四元数表示集成到一个统一的向量中。Huang等人[137]将LLM与其他视觉和图编码器相结合,学习多模态知识图嵌入,提高下游任务的性能。CoDEx[138]提出了一种新的LLM损失函数,该函数通过考虑文本信息来指导KGE模型测量三元组的可能性。所提出的损失函数与可以与任何 KGE 模型合并的模型结构无关。
(2)LLM用于联合的文本和KG嵌入

另一种方法不是使用KGE模型来考虑图结构,而是直接使用LLM将图结构和文本信息同时合并到嵌入空间中。如图17所示,kNN-KGE[140]将实体和关系视为LLM中的特殊tokens。在训练期间,它将每个三元组 (h, r, t) 和相应的文本描述迁移到句子 x 中为
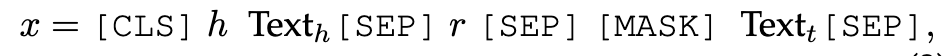
其中尾部实体被 [MASK] 替换。句子被送入LLM,然后对模型进行微调以预测被屏蔽的实体,公式为
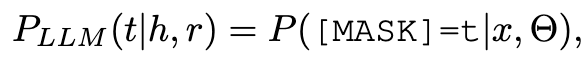
同样,LMKE [139] 提出了一种对比学习方法来改进 LLM 为 KGE 生成的嵌入学习。同时,为了更好地捕获图结构,LambdaKG[141]对1跳邻居实体进行采样,并将它们的tokens与三元组连接起来,作为输入到LLM的句子。
LLM增强的KG补全
知识图谱补全 (KGC) 是指在给定知识图谱中推断缺失事实的任务。与KGE类似,传统的KGC方法主要集中在KG的结构上,没有考虑大量的文本信息。然而,LLM 的最新集成使 KGC 方法能够对文本进行编码或生成事实以获得更好的 KGC 性能。这些方法根据其利用风格分为两类:1)LLM作为编码器(PaE),2)LLM作为生成器(PaG)。
(1)LLM作为编码器

如图 18 (a)、(b) 和 (c) 所示,这一系列工作首先使用仅编码器的 LLM 对文本信息和 KG 事实进行编码。然后,他们将编码表示输入到预测头中来预测三元组的合理性,该预测头可以是简单的 MLP 或传统的 KG 评分函数(例如 TransE和 TransR)。
a)联合编码
由于仅编码器 LLM(例如 Bert [1])擅长编码文本序列,因此 KG-BERT [26] 将三元组 (h, r, t) 表示为文本序列,并使用 LLM对其进行编码。

[CLS] token的最终隐藏状态被送入分类器以预测三元组的可能性,公式为

为了提高KG-BERT的有效性,MTL-KGC[142]为KGC框架提出了一种多任务学习,该框架将额外的辅助任务纳入模型的训练中,即预测(RP)和相关性排序(RR)。
PKGC[143]通过将三元组及其支持信息转换为具有预定义模板的自然语言句子来评估三元组(h,r,t)的有效性。然后,LLM对这些句子进行处理以进行二元分类。三元组的支持信息是通过描述函数从h和t的属性导出的。例如,如果三元祖是(LeBron James,member of sports team,Lakers),那么关于勒布朗·詹姆斯的信息就被描述为“Lebron James: American basketball player”。
LASS[144]指出,语言语义和图结构对KGC同样重要。因此,LASS被提议联合学习两种类型的嵌入:语义嵌入和结构嵌入。在这种方法中,三元组的全文被转发到LLM,并且分别计算h、r和t的相应LLM输出的平均池。然后将这些嵌入传递给基于图形的方法,即TransE,以重建KG结构。
b)MLM编码
许多工作引入了掩蔽语言模型(MLM)的概念来对KG文本进行编码,而不是对三元组的全文进行编码(图第18(b)段)。MEMKGC[145]使用掩蔽实体模型(MEM)分类机制来预测三元组的掩蔽实体。输入文本的形式为
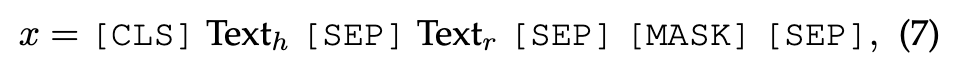
它试图最大化掩蔽实体是正确实体t的概率。此外,为了使模型能够学习看不见的实体,MEM-KGC集成了实体的多任务学习和基于实体文本描述的超类预测:

OpenWorld KGC[146]扩展了MEM-KGC模型,以通过流水线框架解决开放世界KGC的挑战,其中定义了两个顺序的基于MLM的模块:实体描述预测(EDP),一个辅助模块,用于预测具有给定文本描述的相应实体;不完全三重预测(ITP),为给定的不完全三元组(h,r,?)预测一个合理实体的目标模块。EDP首先用等式8对三元组进行编码,并生成最终隐藏状态,然后将其转发到ITP中,作为等式7中头部实体的嵌入,以预测目标实体。
c)分离编码
这些方法包括将三元组(h,r,t)划分为两个不同的部分,即(h,r)和t,这两个部分可以表示为

然后,这两个部分由LLM分别编码,[CLS]令牌的最终隐藏状态分别用作(h,r)和t的表示。然后将表示输入到评分函数中,以预测三元组的可能性,公式为
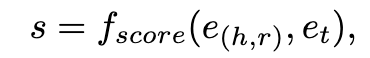
其中f_{score}表示类似于TransE的得分函数。
StAR[147]在其文本上应用孪生风格(Siamese-style)的文本编码器,将其编码为单独的上下文化表示。为了避免文本编码方法(例如KG-BERT)的组合爆炸,StAR采用了一个评分模块,该模块分别涉及确定性分类器和空间测量,用于表示和结构学习,它还通过探索空间特征来增强结构化知识。
SimKGC[148]是利用孪生(Siamese)文本编码器对文本表示进行编码的另一个例子。在编码过程之后,SimKGC将对比学习技术应用于这些表示。这个过程涉及计算给定三元组的编码表示与其正样本和负样本之间的相似性。特别地,三元组的编码表示与正样本之间的相似性被最大化,而三元组的编码器表示与负样本之间的类似性被最小化。这使SimKGC能够学习一个分离可信和不可信三元组的表示空间。为了避免过拟合文本信息,CSPromp KG[187]对KGC采用了参数高效的提示学习。
LP-BERT[149]是一种混合KGC方法,它结合了MLM编码和分离编码。这种方法包括两个阶段,即预训练和微调。在预训练期间,该方法利用标准MLM机制来用KGC数据预训练LLM。在微调阶段,LLM对这两个部分进行编码,并使用对比学习策略进行优化。
(2)LLM作为生成器
最近的工作使用LLM作为KGC中的序列到序列生成器。如图19(a)和(b)所示,这些方法涉及编码器-解码器或仅解码器LLM。LLM接收查询三元组(h,r,?)的序列文本输入,并直接生成尾部实体t的文本。

GenKGC[98]使用大型语言模型BART[5]作为骨干模型。受GPT-3[60]中使用的上下文学习方法的启发,其中模型拼接相关样本以学习正确的输出答案,GenKGC提出了一种关系引导的演示技术(relation-guided demonstration technique),该技术包括具有相同关系的三元组,以促进模型的学习过程。此外,在生成过程中,提出了一种实体感知的分层解码方法来降低时间复杂度。KGT5[150]介绍了一种新的KGC模型,该模型满足了此类模型的四个关键要求:可扩展性、质量、多功能性和简单性。为了实现这些目标,所提出的模型采用了一种简单的T5小型架构。该模型不同于以前的KGC方法,在以前的方法中,它是随机初始化的,而不是使用预先训练的模型。
KG-S2S是一个全面的框架,可应用于各种类型的KGC任务,包括静态KGC、时态KGC和少镜头KGC。为了实现这一目标,KG-S2S通过引入一个附加元素来重新表述标准的三元组KG事实,形成四元组(h,r,t,m),其中m表示附加的“condition”元素。尽管不同的KGC任务可能指的是不同的条件,但它们通常具有相似的文本格式,这使得不同KGC任务之间能够统一。KG-S2S方法结合了各种技术,如实体描述、soft prompt和Seq2Seq Dropout,以提高模型的性能。此外,它利用约束解码来确保生成的实体是有效的。

对于闭源的LLMs,AutoKG采用提示工程设计定制化提示[95]。如图20所示,这些提示包含任务描述、少样本示例和测试输入,指示LLM预测KG补全的尾部实体。
(3)PaE和PaG的比较
作为编码器的LLM(PaE)在由LLM编码的表示的顶部应用额外的预测头。因此,PaE框架更容易微调,因为我们只能优化预测头并冻结LLM。此外,对于不同的KGC任务,预测的输出可以很容易地指定并与现有的KGC函数集成。然而,在推理阶段,PaE需要以KGs为单位计算每个候选的分数,这可能在计算上很昂贵。此外,它们不能泛化到看不见的实体。此外,PaE需要LLM的表示输出,而一些最先进的LLM(例如GPT-4)是闭源的,并且不允许访问表示输出。
另一方面,LLM作为生成器(PaG),不需要预测头,可以在没有微调或访问表示的情况下使用。因此,PaG的框架适用于所有类型的LLM。此外,PaG直接生成尾部实体,使其在推理中高效,而不需要对所有候选进行排序,并且容易泛化到看不见的实体。但是,PaG面临的挑战是,生成的实体可能是多样化的,而不是存在于KGs中。此外,由于自回归生成,单个推理的时间更长。最后,如何设计一个强大的提示,将KGs输入LLM仍然是一个悬而未决的问题。因此,尽管PaG已经证明了KGC任务的良好结果,但在选择合适的基于LLM的KGC框架时,必须仔细考虑模型复杂性和计算效率之间的权衡。
(4)模型分析
Justin等人[188]对结合LLM的KGC方法进行了全面分析。他们的研究调查了LLM嵌入的质量,发现它们对于有效的实体排序来说是次优的。作为回应,他们提出了几种处理嵌入的技术,以提高其对候选检索的适用性。该研究还比较了不同的模型选择维度,如嵌入提取、查询实体提取和语言模型选择。最后,作者提出了一个有效地将LLM应用于知识图补全的框架。
LLM增强的KG构建
知识图谱构建涉及在特定领域内创建知识的结构化表示。这包括识别实体及其彼此之间的关系。知识图谱的构建过程通常包括多个阶段,包括1)实体发现,2)共指解析和3)关系提取。图21显示了在KG构建的每个阶段应用LLM的总体框架。最近的方法探索了4)端到端的知识图谱构建,包括一步构建完整的知识图谱或5)直接从LLM中蒸馏知识图谱。
(1)实体发现

KG构造中的实体发现是指从非结构化数据源中识别和提取实体的过程,例如文本文档、网页或社交媒体帖子,并将它们结合起来构建知识图谱。
a)NER
命名实体识别 (NER) 涉及识别和标记文本数据中的命名实体及其位置和分类。命名实体包括人员(people)、组织(organization)、位置(position)和其他类型的实体。最先进的 NER 方法通常使用 LLM 来利用它们的上下文理解和语言知识进行准确的实体识别和分类。基于识别出的 NER 跨度的类型,有三个 NER 子任务,即flat NER、嵌套 NER(nested NER) 和不连续 NER(Discontinuous NER)。1) Flat NER 是从输入文本中识别非重叠命名实体。它通常被概念化为一个序列标注问题,其中文本中的每个token根据其在序列中的位置分配一个唯一的标签 。2) Nested NER 考虑允许token属于多个实体的复杂场景。基于span的方法是嵌套NER的一个流行分支,它涉及枚举所有候选跨度(span)并将它们分类为实体类型(包括非实体类型)。基于解析的方法 [197]-[99] 揭示了嵌套 NER 和选区解析任务之间的相似性(预测嵌套和非重叠跨度),并建议将选区解析的见解集成到嵌套 NER 中。3) 不连续 NER 识别文本中可能不连续的命名实体。为了应对这一挑战,[200] 使用 LLM 输出来识别实体片段并确定它们是否重叠。
与特定于任务的方法不同,GenerativeNER[201]使用带有指针机制的序列到序列LLM来生成实体序列,该实体序列能够解决所有三种类型的NER子任务。
b)Entity Typing
实体分类(ET)旨在为上下文中提到的给定实体提供细粒度和超细粒度的类型信息。这些方法通常使用LLM对提及(mention)、上下文(context)和类型(type)进行编码。LDET[152]将预训练的ELMo嵌入[189]应用于单词表示,并采用LSTM作为其句子和提及编码器。
BOX4Types[153]认识到类型依赖性的重要性,并使用BERT来表示超矩形(框)空间中的隐藏向量和每个类型。LRN[154]考虑了标签之间的外在和内在依赖性。它使用BERT对上下文和实体进行编码,并使用这些输出嵌入进行演绎和归纳推理。MLMET[202]使用预定义的模板来构建BERT MLM的输入样本,并使用[MASK]来预测提及的上下文相关的同义词,这些同义词可以被视为类型标签。PL[203]和DFET[204]利用提示学习来进行实体键入。LITE[205]将实体分类公式化为文本推理,并使用RoBERTa-large-MNLI作为骨干网络。
c)Entity Linking
实体链接(EL),也称为实体消歧,涉及将文本中出现的实体提及链接到知识图中相应的实体。[206]提出了基于BERT的端到端EL系统,该系统联合发现和链接实体。ELQ[207]采用快速双编码器架构,为下游问答系统一次联合执行提及检测和链接。与之前在向量空间中将EL框定为匹配的模型不同,GENRE[208]将其形式化为序列到序列问题,自回归生成用自然语言表示的实体的唯一标识符注释的输入标记的版本。GENRE扩展到其多语言版本mGENRE[209]。考虑到生成EL方法的效率挑战,[210]在所有潜在提及中并行化自回归链接,并依赖于浅层高效解码器。ReFinED[211]通过利用基于LLM的编码器处理的细粒度实体类型和实体描述,提出了一种高效的zero-shot EL方法。
(2)共指解析
共指解析是找到引用文本中相同实体或事件的所有表达(即提及)。
Within-document CR 是指所有这些提及都在单个文档中的 CR 子任务。Mandar等人[156]通过用BERT替换之前的LSTM编码器[212]来初始化基于LLM的共指解析。这项工作随后介绍了 SpanBERT [157],它是在具有基于跨度的掩码语言模型 (MLM) 的 BERT 架构上预训练的。受这些工作的启发,Tuan Manh 等人[213] 通过将 SpanBERT 编码器合并到非 LLM 方法 e2e-coref [212] 中提出了一个强大的基线。CorefBERT 利用提及参考预测 (MRP) 任务,该任务屏蔽一个或几个提及,并要求模型预测掩码提及的相应所指对象。CorefQA [214] 将共指解析制定为问答任务,其中为每个候选提及生成上下文查询,并使用查询从文档中提取相关跨度。Tuan Manh等人[215]引入了一种门控机制和噪声训练方法,使用SpanBERT编码器从事件提及中提取信息。
为了减少大型基于LLM的NER模型所面临的大内存占用,Yuval等人[216]和Raghuveer等人[217]分别提出了start-to-end和近似模型,两者都利用双线性函数来计算提及和前件分数,同时减少对跨度级表示的依赖。
Cross-document CR 是指提及引用相同实体或事件可能跨越多个文档的子任务。CDML [158] 提出了一种跨文档语言建模方法,该方法在连接的相关文档上预训练 Longformer [218] 编码器,并使用 MLP 进行二元分类以确定一对提及是否相关。CrossCR [159] 利用端到端模型进行跨文档共指解析,该模型在黄金提及跨度上预训练提及评分器,并使用成对评分器将提及与所有文档中的所有跨度进行比较。CR-RL [160] 提出了一种基于演员-评论家深度强化学习的跨文档 CR 共指解析器。
(3)关系抽取
关系抽取涉及识别自然语言文本中提到的实体之间的语义关系。根据分析的文本范围,有两种关系抽取方法,即句子级 RE 和文档级 RE。
Sentence-level RE 专注于识别单个句子中的实体之间的关系。Peng等人[161]和TRE[219]引入LLM来提高关系提取模型的性能。BERT-MTB [220] 通过执行匹配的空白任务并结合设计的目标进行关系提取来学习基于 BERT 的关系表示。Curriculum-RE [162] 利用课程学习通过在训练期间逐渐增加数据的难度来改进关系提取模型。最近[221]引入了SpanBERT,并利用实体类型限制来减少嘈杂的候选关系类型。Jiewen [222] 通过将实体信息和标签信息结合到句子级嵌入中来扩展 RECI,这使得嵌入能够感知实体标签。
Document-level RE (DocRE) 旨在提取文档中多个句子之间的实体之间的关系。Hong等人[223]通过用LLM替换BiLSTM主干,为DocRE提出了一个强大的基线。HIN[224]使用LLM对不同级别的实体表示进行编码和聚合,包括实体、句子和文档级别。GLRE [225] 是一个global-to-local的网络,它使用 LLM 在实体全局和局部表示以及上下文关系表示方面对文档信息进行编码。SIRE [226] 使用两个基于 LLM 的编码器来提取句内和句间关系。LSR[227]和GAIN[228]提出了基于图的方法,在LLM之上诱导图结构,以更好地提取关系。DocuNet[229]将DocRE制定为语义分割任务,并在LLM编码器上引入了一个U-Net[230]来捕获实体之间的局部和全局依赖关系。ATLOP[231]关注DocRE中的多标签问题,可以用两种技术处理,即分类器的自适应阈值和LLM的局部上下文池。DREEAM[163]通过结合证据信息进一步扩展了和改进ATLOP。
(4)端到端KG构建
Kumar等人[97]提出一种从原始文本构建KGs的统一方法,其中包含两个LLM支持的组件。他们首先对命名实体识别任务的LLM进行微调,使其能够识别原始文本中的实体。然后,他们提出了另一种“2-模型BERT”来解决关系提取任务,其中包含两个基于BERT的分类器。第一个分类器学习关系类,而第二个二元分类器学习两个实体之间关系的方向。然后使用预测的三元组和关系来构建KG。
郭等人[164]提出了一种基于BERT的端到端知识提取模型,该模型可用于从文言文中构建知识库。Grapher[41]提出了一种新颖的端到端多级系统。它首先利用LLM生成KG实体,然后是一个简单的关系构建头,从而从文本描述中实现高效的KG构建。PiVE[165]提出了一种具有迭代验证框架的提示,该框架利用较小的LLM(如T5)来校正较大LLM(例如,ChatGPT)生成的KGs中的错误。为了进一步探索高级LLM,AutoKG为不同的KG构建任务(例如,实体分类、实体链接和关系提取)设计了几个提示。然后,它采用提示,使用ChatGPT和GPT-4进行KG构建。
(5)从LLM中蒸馏知识图谱

LLM已被证明可以隐式编码海量知识[14]。如图22所示,一些研究旨在从LLM中提取知识来构建KGs。COMET[166]提出了一种常识转换器模型,该模型通过使用现有元组作为训练的知识种子集来构建常识性KGs。使用这个种子集,LLM学习使其学习的表示适应知识生成,并产生高质量的新元组。实验结果表明,LLM中的内隐知识在常识性知识库中被转换为外显知识。BertNet[167]提出了一种由LLM授权的KG自动构建的新框架。它只需要将关系的最小定义作为输入,并自动生成不同的提示,并在给定的LLM中执行有效的知识搜索以获得一致的输出。构建的KGs表现出竞争性、多样性和新颖性,具有一组更丰富的新的复杂关系,这些关系是以前的方法无法提取的。West等人[168]提出了一种从LLM中提取符号知识的符号知识提取框架。他们首先通过从像GPT-3这样的大型LLM中提取常识性事实来微调小型学生LLM。然后,利用学生LLM生成常识KGs。
LLM增强的KG到文本生成
知识图谱到文本(KG到文本)生成的目标是生成准确、一致地描述输入知识图谱信息的高质量文本[232]。KG到文本生成将知识图谱和文本连接起来,显著提高了KG在更现实的NLG场景中的适用性,包括讲故事[233]和基于知识的对话[234]。然而,收集大量的图文并行数据具有挑战性且成本高昂,导致训练不足和生成质量差。因此,许多研究工作要么求助于:1)利用LLM的知识,要么2)构建大规模的弱监督KG-文本语料库来解决这个问题。
(1)利用LLM中的知识

作为将LLM用于KG到Text生成的开创性研究工作,Ribeiro等人[169]以及Kale和Rastogi[235]直接微调各种LLM,包括BART和T5,目的是为这项任务迁移LLM知识。如图23所示,这两项工作都将输入图谱简单地表示为线性遍历,并发现这种朴素的方法成功地优于许多现有的最先进的KG到文本生成系统。
然而,这些方法无法在KGs中显式地结合丰富的图语义。为了用KG结构信息增强LLM,JointGT[42]提出将保留KG结构的表示注入Seq2Seq大型语言模型中。给定输入子KG和相应的文本,JointGT首先将KG实体及其关系表示为令牌序列,然后将它们与输入LLM的文本令牌连接起来。在标准的自注意模块之后,JointGT使用池化层来获得知识实体和关系的上下文语义表示。最后,将这些汇集的KG表示聚合到另一个结构感知的自注意层中。JointGT还部署了额外的预训练目标,包括给定掩蔽输入的KG和文本重建任务,以提高文本和图形信息之间的一致性。李等人[170]专注于少数镜头场景。它首先采用了一种新颖的广度优先搜索(BFS)策略来更好地遍历输入KG结构,并将增强的线性化图表示馈送到LLM中以获得高质量生成的输出,然后将基于GCN和基于LLM的KG实体表示对齐。Colas等人[171]在对图进行线性化之前,首先将图转换为其适当的表示。接下来,通过全局注意力机制对每个KG节点进行编码,然后是图感知注意力模块,最终解码为令牌序列。与这些工作不同的是,KG-BART[37]保留了KG的结构,并利用图的注意力来聚合子KG中丰富的概念语义,这增强了模型在看不见的概念集上的泛化能力。
(2)构建大规模的弱监督KG-文本语料库
Jin等人[172]提出了一种1.3M的无监督KG来绘制维基百科中的训练数据。具体而言,他们首先通过超链接和命名实体检测器检测文本中出现的实体,然后只添加与相应知识图谱共享一组公共实体的文本,类似于关系抽取任务中的远程监督的想法[236]。他们还提供了1000多个人工标注的KG-to-Text测试数据,以验证预训练的KG-to-Text模型的有效性。同样,Chen等人[173]还提出了KG-grounded文本语料库,从English Wikidump中收集。为了确保KG和文本之间的联系,他们只提取至少有两个维基百科锚链接的句子。然后,他们使用这些链接中的实体在WikiData中查询周围的邻居,并计算这些邻居与原始句子之间的词汇重叠。最后,只选择高度重叠的对。作者探索了基于图和基于序列的编码器,并确定了它们在各种不同任务和设置中的优势。
LLM增强的KG问答

知识图谱问答(KGQA)旨在根据存储在知识图谱中的结构化事实找到自然语言问题的答案[237],[238]。KGQA中不可避免的挑战是检索相关事实,并将KGs的推理优势扩展到QA中。因此,最近的研究采用LLM来弥合自然语言问题和结构化知识图谱之间的差距[176],[177],[239]。将LLM应用于KGQA的一般框架如图24所示,其中LLM可以用作1)实体/关系抽取器和2)答案推理器。
(1)LLM作为实体/关系抽取器
Lukovnikov等人[175]是第一个将LLM用作关系预测的分类器,与浅层神经网络相比,其性能显著提高。Nan等人[176]介绍了两个基于LLM的KGQA框架,它们采用LLM来检测提到的实体和关系。然后,他们使用提取的实体关系对以KGs为单位查询答案。QA-GNN[117]使用LLM对问题和候选答案对进行编码,用于估计相关KG实体的重要性。实体被检索以形成子图,其中答案推理由图神经网络进行。Luo等人[174]使用LLM计算关系和问题之间的相似性,以检索相关事实,公式如下

此外,张等人[240]提出了一种基于LLM的路径检索器,用于逐跳检索与问题相关的关系,并构造多条路径。每条路径的概率可以计算为

检索到的关系和路径可以用作上下文知识,以提高答案推理器的性能:

(2)LLM作为答案推理器
答案推理器设计用于对检索到的事实进行推理并生成答案。LLM可以用作直接生成答案的答案推理器。例如,如图24所示,DEKCOR[177]将检索到的事实与问题和候选答案连接为
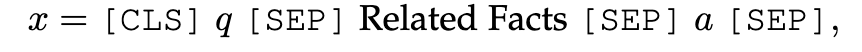
然后,它将它们输入LLM,以预测答案分数。在利用LLM生成x的表示作为QA上下文之后,DRLK[178]提出了一种动态层次推理器来捕获QA上下文和答案之间的交互,用于答案预测。Yan等人[239]提出了一个基于LLM的KGQA框架,该框架由两个阶段组成:(1)从KGs中检索相关事实;(2)基于检索到的事实生成答案。第一阶段类似于实体/关系提取器。给定候选答案实体a,pn来自KGs。但第二阶段是基于LLM的答案推理器。它首先使用KGs中的实体名称和关系名称来描述路径。然后,它将问题q和所有路径p1、……,pn连接起来以使输入样本为

这些路径被视为候选答案a的相关事实。最后,它使用LLM来预测假设“a是q的答案”是否得到这些事实的支持,公式化为

为了更好地通过KGs引导LLM推理,OreoLM[179]提出了一种插入LLM层中的知识交互层(KIL)。KIL与KG推理模块交互,在那里它发现不同的推理路径,然后推理模块可以对路径进行推理以生成答案。GreaseLM[119]融合了LLM和图神经网络的表示,以有效地推理KG事实和语言上下文。UniKGQA[43]将事实检索和推理统一到一个统一的框架中。UniKGQA由两个模块组成。第一个模块是语义匹配模块,它使用LLM将问题与其对应关系进行语义匹配。第二个模块是匹配信息传播模块,它沿着KGs上的有向边传播匹配信息,用于答案推理。类似地,ReLMKG[180]对大型语言模型和相关知识图谱执行联合推理。问题和语言化路径由语言模型编码,语言模型的不同层产生输出,引导图神经网络执行消息传递。该过程利用结构化知识图中包含的显式知识进行推理。StructGPT[241]采用定制化接口,允许大型语言模型(例如,ChatGPT)直接对KGs进行推理,以执行多步骤问答。
6【Synergized LLMs + KGs】

LLM和KGs的统一可以产生一个强大的知识表示和推理模型。在本节中,我们将从两个角度讨论协同LLM+KGs:1)知识表示和2)推理。我们总结了表4中的代表作。
知识表示
统一LLM和KGs用于知识表示的一般框架如图25所示。

KEPLER[40]提出了一个用于知识嵌入和预训练语言表示的统一模型。在KEPLER中,他们用LLM作为嵌入对文本实体描述进行编码,然后联合优化知识嵌入和语言建模目标。JointGT[42]提出了一种图-文本联合表示学习模型,该模型提出了三个预训练任务来对齐图和文本的表示。DRAGON[44]提出了一种自监督方法,从文本和KG中预训练联合语言知识基础模型。它以文本片段和相关的KG子图为输入,双向融合来自两种模式的信息。然后,DRAGON利用两个自监督推理任务,即掩蔽语言建模和KG链接预测来优化模型参数。HKLM[242]引入了一种统一的LLM,它结合了KGs来学习领域特定知识的表示。
推理
在问答任务中,QA-GNN[117]首先利用LLM来处理文本问题,并指导推理步骤。通过这种方式,它可以弥合文本和结构信息之间的差距,从而为推理过程提供可解释性。在知识图谱推理任务中,LARK[45]提出了一种LLM引导的逻辑推理方法。它首先将传统的逻辑规则转换为语言序列,然后要求LLM对最终输出进行推理。此外,siyuan等人[46]将结构推理和语言模式预训练统一在一个统一的框架中。给定文本输入,他们采用LLM来生成逻辑查询,该查询在KGs上执行以获得结构上下文。最后,将结构上下文与文本信息融合以生成最终输出。RecInDial[243]结合知识图谱和LLM,在对话系统中提供个性化推荐。KnowledgeDA[244]提出了一个统一的领域语言模型开发pipeline,以增强具有领域知识图谱的任务特定训练过程。
7【Future Direction & Conclusion】
- KG用于LLM的幻觉检测
- KG用于LLM的知识编辑
- KG用于黑箱LLM的知识注入
- KG用于多模态LLM
- LLM用于理解KG结构
- 协同LLM和KG的双向推理
【Conclusion】
将大型语言模型(LLM)和知识图谱(KGs)统一起来是一个活跃的研究方向,越来越受到学术界和工业界的关注。在这篇文章中,我们对该领域的最新研究进行了全面的概述。我们首先介绍了整合KGs以增强LLM的不同方式。然后,我们介绍了现有的将LLM应用于KG的方法,并基于各种KG任务建立了分类法。最后,我们讨论了这一领域的挑战和未来方向。我们希望本文能对这一领域有一个全面的了解,并推动未来的研究。
参考:
【论文阅读】《Unifying Large Language Models and Knowledge Graphs: A Roadmap》
这篇关于统一大型语言模型和知识图谱:路线图的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









