本文主要是介绍Python 全栈系列241 GFGo Lite迭代,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
说明
随着整个算网开发逐渐深入,各个组件、微服务的数量、深度在不断增加。由于算网是个人项目,我一直按照MVP(Minimum Viable Product )的原则在推进。由于最初的时候对架构、算法和业务的理解并没有那么深刻,所以MVP的内容还是在不断变化(增加)的。比较幸运的是,中间走的弯路比较少,整体方向上一直没有大偏差,应该可以在预期的时间内达到目标。
从工具和使用的角度来看,我一边在算网的概念下构造工具,一边在尝试使用这些工具提高我的效率/能力上限。过去,由于已知的、明确要实现的功能就很多,所以一直是不断急速前进,常见的一种情况是:工具开发好了,测试也好用,但是就扔在一边,继续开发别的新工具去了。
现在的情况是:完成一个MVP所需要新开发的功能几乎没有了,反而是将已有的工具用起来比较重要。
今年做的比较重要的改变是使用streamlit、gradio将微服务前后端一体化。这种方式最初是大语言模型广泛采用的,的确非常方便。对算网而言,大量的已开发组件和功能,将通过这种方式进行文档、测试和使用的一体化。
总之,现在的重点是实现(Realization)。
内容
1 GlobalFunc更新
1.1 程序
目前仍然采用vscode代码开发的方式,创建一个个新的py文件。
1.2 推送更新
步骤如下:
- 1 切到项目路径下
cd .../m4git/GlobalFunc - 2 导入操作对象
from op044_GlobalFunc_01BaseOpt import gfbase# 1 查看当前分枝
gfbase._get_current_branch()
# 2 扫描所有文件的信息
scan_dict = gfbase._get_scan_files()
# 3 提交git项目
gfbase._simple_commit_git()
# 4 刷新一个包的初始化文件
gfbase._generate_init_py('Base')
gfbase._generate_init_py('Parse')
gfbase._generate_init_py('TFIDF')
# 5 批量存储函数
some_pack_list = [x for x in scan_dict.keys() if x.startswith('Base.') or x.startswith('Parse.') or x.startswith('TFIDF.')]for some_file in some_pack_list:gfbase._save_a_file_rom(some_file)
2 GFGo Lite 更新
GFGo Lite 有所修改,文件在项目文件夹gfgo_lite_24090 下面
2.1 文件
切入gfgo_lite_build容器,里面已经有了一些依赖文件
- 1
init_funcs里面存放了数据库连接相关的函数 - 2 按模块执行加载,然后初始化
以下是从Base模块中加载一些函数的示例
from init_funcs import create_file,generate_init_py,RedisOrMongo, Naiveimport os
import json
# 声明空间# 在容器中启动
redis_cfg = Naive()
redis_cfg.redis_agent_host = 'http://172.17.0.1:24021/'
redis_cfg.redis_connection_hash = None# 模块Base
if True:# 声明当前要创建的程序文件夹:默认为funcstarget_folder = 'GlobalFunc'tier1 = 'sp_GlobalFunc'var_space_name = 'Base'# 分支,一般默认为masterbranch_name = 'master' tier2 = '_'.join([var_space_name, branch_name])the_space_name = '.'.join([tier1,tier2])target_folder = target_folder + '/' + var_space_nameos.makedirs(target_folder, exist_ok=True)rom = RedisOrMongo(the_space_name, redis_cfg.dict(),backend='mongo', mongo_servername='m7.24065')# 这个一般根据需要,或者代码中得来 --- 需要的列表项func_list = [ 'from_pickle','to_pickle','is_file_exists','gen_time_axis','ATimer2','get_time_str1','cols2s','create_folder_if_notexist','flat_dict','flatten_list']# func_list = [ 'from_pickle','to_pickle','pose_a_file']for some_name in func_list:# 获取 meta,data : data就是代码字符the_data = rom.getx(some_name)filename = the_data['meta']['name']filedata = the_data['data']create_file(target_folder, filename, filedata)# 生成初始化文件generate_init_py(target_folder)在导入新的包时,需要手动修改GlobalFunc下的__init__.py(与Base包和Parse包平级)。
from . import Base
from . import Parse
2.2 服务
在 /workspace下直接启动服务即可 python3 server.py。
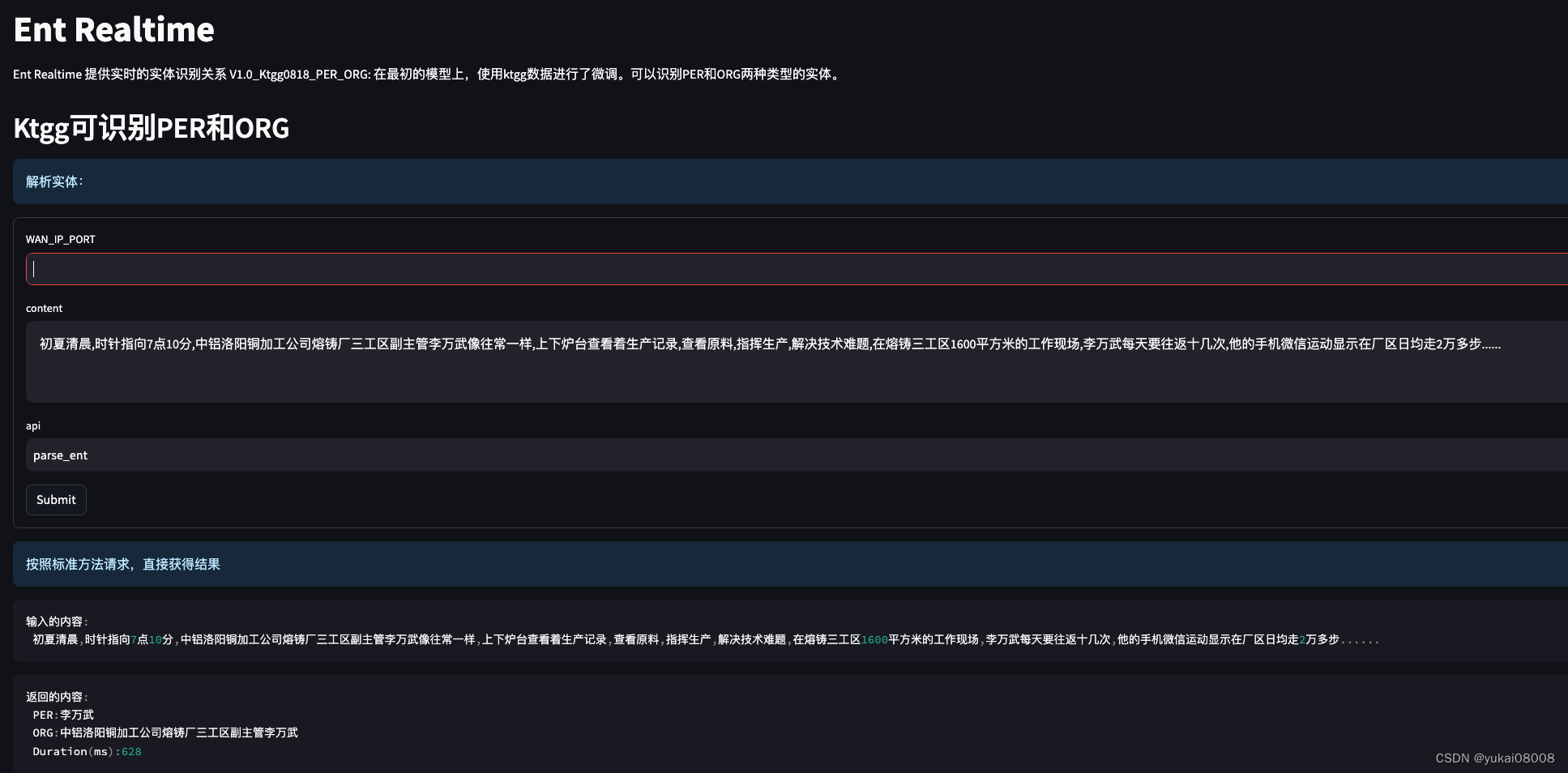
3 应用
3.1 通用函数 UCS
UCS是一个规范,为了支持这个规范,必须依赖一些特定(同时也是固定)的函数。因为函数的通用性,所以这些函数放在了最外层,每个函数都占据了一个api接口。
3.1.1 block (int)
整型block分割三件套
import requests as req some_dict = {}
some_dict['rec_id'] = 111111res = req.post('http://127.0.0.1:8000/get_brick_name/', json = some_dict).json()'0.0.0.11'some_dict = {}
some_dict['brick_name'] = '0.0.0.11'res = req.post('http://127.0.0.1:8000/get_brick_bounds/', json = some_dict).json()
[110000.0, 120000.0]some_dict = {}
some_dict['start_brick_name'] = '0.0.0.9'
some_dict['end_brick_name'] = '0.0.0.12'res = req.post('http://127.0.0.1:8000/get_brick_list/', json = some_dict).json()
['0.0.0.9', '0.0.0.10', '0.0.0.11'
3.1.2 time block
操作如下:时间支持字符和数值(时间戳)两种模式。
import requests as req # char
some_dict = {}
some_dict['dt_str_or_ts'] = '2024-01-31 11:11:11'
res = req.post('http://127.0.0.1:8000/get_time_brick_name/', json = some_dict).json()
'2024.01.31.11'# num
some_dict = {}
some_dict['dt_str_or_ts'] = 1706670671
res = req.post('http://127.0.0.1:8000/get_time_brick_name/', json = some_dict).json()
'2024.01.31.11'# char
some_dict = {}
some_dict['brick_name'] = '2024.01.31.11'
some_dict['char_or_num'] = 'char'
res = req.post('http://127.0.0.1:8000/get_time_brick_bounds/', json = some_dict).json()'''
In [13]: res
Out[13]: ['2024-01-31 11:00:00', '2024-01-31 12:00:00']
'''# num
some_dict = {}
some_dict['brick_name'] = '2024.01.31.11'
some_dict['char_or_num'] = 'num'
res = req.post('http://127.0.0.1:8000/get_time_brick_bounds/', json = some_dict).json()'''
In [15]: res
Out[15]: [1706670000, 1706673600]
'''some_dict = {}
some_dict['start_brick_name'] = '2024.01.31.11'
some_dict['end_brick_name'] = '2024.02.02.11'
res = req.post('http://127.0.0.1:8000/get_time_brick_list/', json = some_dict).json()'''
In [11]: res
Out[11]:
['2024.01.31.11','2024.01.31.12','2024.01.31.13','2024.01.31.14',...
'''3.2 功能函数
3.2.1 Base包的函数调用
以下是两个Base包函数的测试
import requests as req # 测试1:调用Base包的函数
kwargs = {'ts':None, 'bias_hours':8}
pack_func = 'Base.get_time_str1'some_dict = {}
some_dict['kwargs'] = kwargs
some_dict['pack_func'] = pack_funcres = req.post('http://127.0.0.1:8000/gfgo/', json = some_dict).json()
'2024-05-05 11:04:35'# 测试2:列表扁平化
kwargs = {'nested_list':[[1,2],[3],[4,5]]}
pack_func = 'Base.flatten_list'some_dict = {}
some_dict['kwargs'] = kwargs
some_dict['pack_func'] = pack_funcres = req.post('http://127.0.0.1:8000/gfgo/', json = some_dict).json()
[1, 2, 3, 4, 5]
有两点需要注意:
- 1 函数规范为全部关键字参数输入(主要是为了方便调用)
- 2 接口直接返回处理信息(而不是包上状态和消息)
3.3.3 Parse包的函数调用
x = "This is a sample text."
word_list = ["sample", "test", "string"]kwargs = {'x':x, 'word_list':word_list}
pack_func = 'Parse.judge_existence'some_dict = {}
some_dict['kwargs'] = kwargs
some_dict['pack_func'] = pack_funcres = req.post('http://127.0.0.1:8000/gfgo/', json = some_dict).json()True
3.4 服务迭代
推送新的变化
docker push myregistry.domain.com:24052/worker.andy.gfgo_lite_24090:v101
启动服务
docker run -d \--restart=always \--name=gfgo_lite_24090 \-v /etc/localtime:/etc/localtime \-v /etc/timezone:/etc/timezone\-v /etc/hostname:/etc/hostname\-e "LANG=C.UTF-8" \-w /workspace\-p 24090:8000\myregistry.domain.com:24052/worker.andy.gfgo_lite_24090:v101 \sh -c "python3 server.py"
公网调用
In [3]:...: some_dict = {}...: some_dict['brick_name'] = '2024.01.31.11'...: some_dict['char_or_num'] = 'num'...: res = req.post('http://WAN_IP:24090/get_time_brick_bounds/', json = some_dict).json()In [4]: res
Out[4]: [1706670000, 1706673600]4 总结与展望
RuleSet As A Func
将复杂的规则(判定)作为一个函数调用。
Series Apply
每个函数都要支持列表(多个元素)的并行处理。
踩过的一个小坑:GlobalFunc使用了一个公网机的Redis做ROM,而GFGoLite使用m7本地的redis,导致了逻辑上看起来更新了,但是实际未更新。
这篇关于Python 全栈系列241 GFGo Lite迭代的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





