本文主要是介绍HashMap扩容,Hash冲突的两种途径,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
之前一直以为Hash冲突就是不同的键计算出的hash值相同而导致的冲突,直到看见了下面这张图引发了我的思考
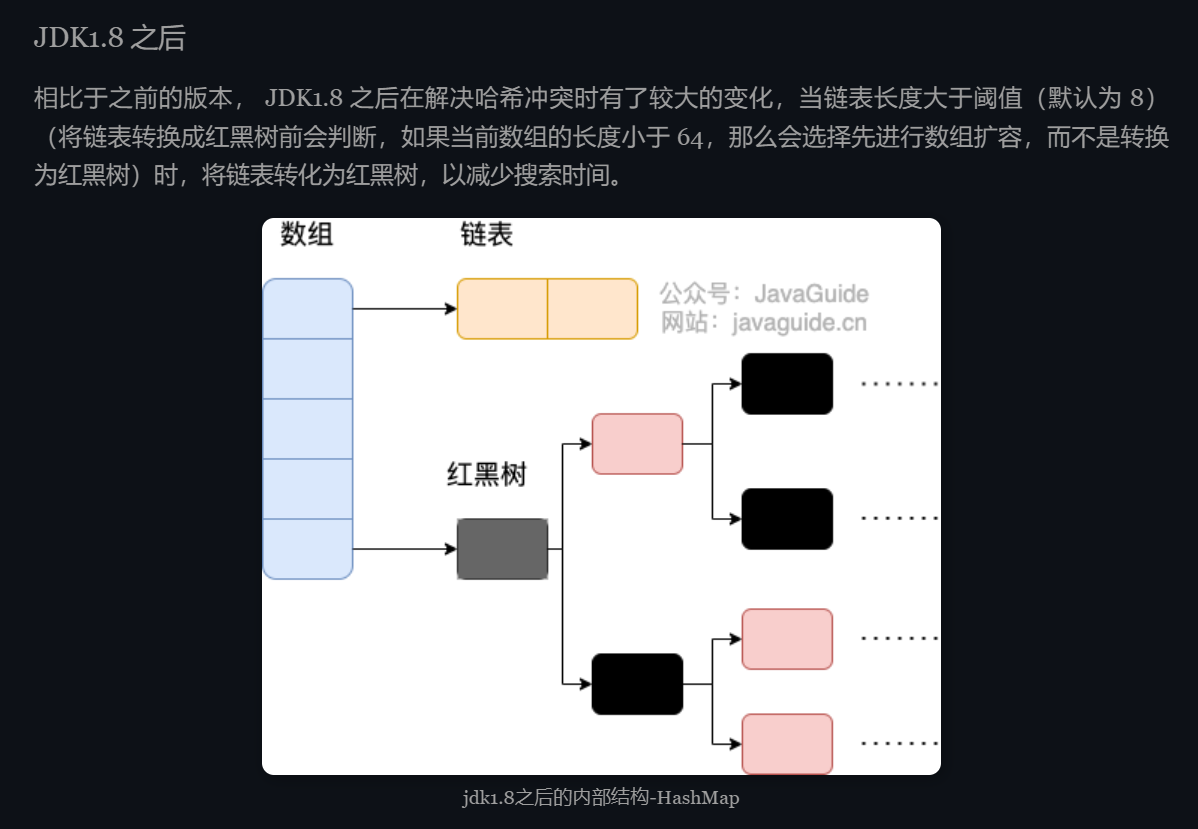
我疑惑,为什么冲突的值要加入的桶的链表满了后,要先进行数组判断是否扩容,扩不扩容最后不还是放到同一个桶中吗?最后还不是得把桶中的链表转为红黑树.了解了一下才发现:

是先根据键值对中的键来计算hash值,在根据hash值来获得索引位置,而这个索引位置就是键值对在数组中的桶的位置.
所以,hash冲突实际上是索引的冲突,有两种途径:

一种是不同的键生成了相同hash值,再通过模运算得到相同索引,
第二种是不同键计算出了不同的的hash值,但是取模后得到了相同索引
所以一切都是数据结构的课没认真听o(╥﹏╥)o
这篇关于HashMap扩容,Hash冲突的两种途径的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







