本文主要是介绍域名介绍,url的介绍+原理+特殊字符的处理,网络行为,http协议请求/响应的格式+结构,状态码介绍,临时/永久重定向,http报头常见字段,fiddler,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
引入
传递数据的方式
域名
引入
自动添加协议前缀
默认端口号
为什么要有域名
介绍
概念
URL
引入
介绍
原理
资源路径介绍
查询参数
片段标识符
特殊字符的处理
编码原理
解码原理
网络上的行为
把别人的东西拿下来
把自己的东西传上去
也可能两种都存在
请求
结构
报头
请求行
请求的方法
url
请求的协议版本
请求报头
如何区分报头和有效载荷
如何读取正文
结构图示
http响应
查看响应格式
telnet
图示
状态行
http服务端的协议版本
状态码
状态描述
http报头常见字段
content-type
referer
location
connection
fiddler
原理
抓包结果
postman
引入
传递数据的方式
os级别的网络协议(tcp/udp,ip,mac帧)的报头
- 是直接传递结构化数据+位段的方式直接传递的,这种方式能够高效地进行数据包的处理和传输
但应用层不建议直接这样
- 它需要传递序列化后的数据
- (可以类比我们的网络计算器代码,应用层部分包含了特定的序列化/反序列化方法)
我们接下来介绍的http协议就是应用层协议
接下来,来了解一些前提知识,他们都是http协议中的一部分
域名
引入
我们平时看到的网址,其实就是域名
- 比如:www.baidu.com
为什么我们能通过域名访问网站呢(也就是访问服务端)?
- 按照我们之前学习的,客户端都是通过ip地址+端口号访问服务端的,为什么域名也可以?
- 其实域名只是一个入口,在浏览器里会进行域名解析,最终得到目标网站的ip地址,然后再结合端口号去访问
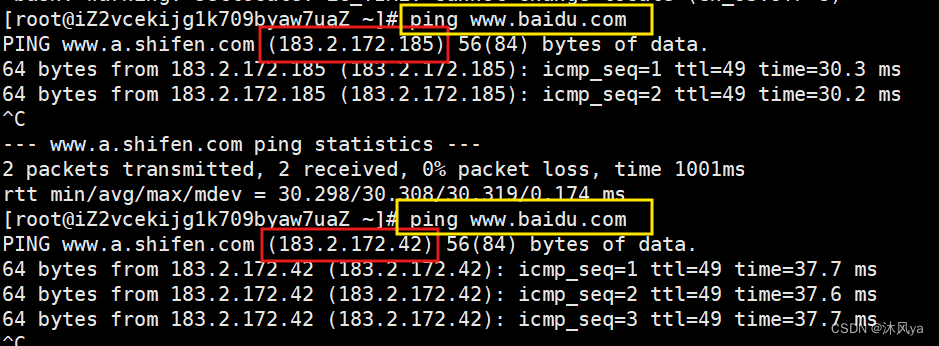
- 其实通过ping命令,我们就可以看到这个转换后的结果:
但是,我们无法直接用ping得到的ip访问官网:
- 因为它的ip一直在变化
- 所以我上网搜了搜 -- 36.152.44.95 这个ip是可以访问的

自动添加协议前缀
当我们在浏览器输入ip地址时,会自动为它添加http/https协议前缀:
- 36.152.44.9 -> http://36.152.44.9/
默认端口号
为什么仅凭ip地址就可以访问到服务呢?我们可没有输入端口号啊
- 之前我们就探讨过,服务端的ip地址和端口号必须强相关,必须是众所周知的
- 就像110和报警电话一样,提到一个,就要能想到另一个
- 所以,他们的端口号必然也是要被浏览器知道的 -> 所以,浏览器会在识别到协议类型后,自动添加端口号
其中,知名的两个应用层协议 -- http和https
- 他们的默认端口号分别是 -- 80,443
- 所以,当我们在浏览器中输入ip地址后,会默认识别成http协议类型,然后添加它对应的端口号80
为什么要有域名
域名的可读性更好,也更容易记住
- 如果让你用一堆莫名其妙的数字去访问某个网站,你会愿意吗?
- 压根就不知道这个网站是干嘛的,万一是钓鱼链接什么的,点进去不就完蛋了
域名一般都是有对应含义的,比如英文/拼音:
- 比如:www.baidu.com,你会知道它是百度的官网
介绍
概念
HTTP(Hypertext Transfer Protocol,超文本传输协议)是一种用于传输超文本(如HTML)数据的应用层协议,它是万维网的基础之一
- 通过URL定位访问资源的位置 -- 浏览器使用HTTP协议获取该URL指定的资源并在浏览器中呈现
- HTTP协议底层使用可靠的传输协议(通常是TCP)来在客户端和服务器之间传输数据
- 在浏览器/服务器模式(bs模式)下,数据在客户端(浏览器)和服务器之间通过HTTP传输
URL
引入
我们首先来见一见url:
- (比如我正在写博客时的url):
- 对,其实就是我们每天都能看见的这个网址
- 可以看到,它的开头部分其实就是我们上面介绍的 -- 添加了http协议前缀的域名

介绍
URL(统一资源定位符)是一种用于定位和识别互联网上资源的标准格式
- 它是网络上资源的唯一地址,使用户可以方便地访问各种资源,如网页、图像、视频、文件等
说是这么说,为什么url能标识全网唯一的网络资源呢?
原理
首先来看看它的结构:
- 其中,user:pass现在已经很少在url里出现了,因为我们有单独的登录页面
- + 域名(上面我们已经介绍过了,解析后就是ip地址) -- 唯一的一台主机
+ 协议和端口号 -- 该主机上唯一的服务(端口号可以忽略,因为协议都有自己的默认端口号)
+ 资源路径 -- 该服务上一个特定的资源(范围从第一个根目录开始,到问号前截止)
所以,url就实现了标识全网唯一的一个资源

资源路径介绍
注意看资源路径部分的分隔符,都是/,这个和linux的路径分隔符是一样的
- 所以,我们可以猜测,这个服务是部署在linux上的
其中,第一个/叫做web根目录,但它不一定等同于根目录(有可能是相对路径)
因为linux下一切皆文件 -> 所有的资源都视作文件 -> 所以它用资源在文件系统里的路径来标识资源
查询参数
用于向服务器传递额外的信息(在url中可能需要把自己的东西上传上去)
- 以?开头
- 以key=value的键值对形式,将一些动态数据上传
- 如果要上传多个参数,用&分隔
类似于:

片段标识符
指定资源中的特定部分
- 比如:文档中的章节、锚点或特定内容
- 或是:如果是那种有左右箭头的查看图片,可能会带有这个作为图片的标识符
- #section-2 将会定位到文档中的 ID 为 section-2 的部分
特殊字符的处理
如果我们提交/获取到的数据,本身包含url中规定的分隔符(或者叫特殊字符),需要额外进行编码和解码
- 这样就保证出现在url里的特殊字符,一定是具有特殊功能的
- 保证url的格式一定是正确的
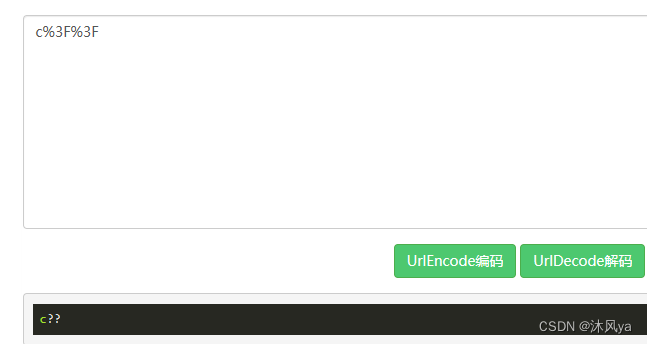
编码原理
- 常用字符都有对应的ascii码,将这个ascii码转换为16进制
- 对于中文符号(有多个字节)来说,规则是:
解码原理
- 其实就是根据编码原理,把它反过来恢复成10进制,然后以ascii码的形式拿到
网上有现成的源码和在线转换工具:
- url编码解码工具,UrlEncode编码,UrlDecode解码-站长工具 (wujingquan.com)


网络上的行为
在网络上的请求(也就是行为),无非也就是两种:
把别人的东西拿下来
获取网页
下载图片
把自己的东西传上去
用户的注册/登录
上传视频
也可能两种都存在
比如:在软件上刷视频
- 会从远端服务器上把视频资源传到本地
- 也会把你的浏览信息上传上去,分析喜好
- 然后按照喜好推荐视频
请求
当我们拿着域名访问网站时,就相当于向服务端发起了一次http请求
结构
请求分为两部分
- 报头 -- 请求行,请求报头
- 有效载荷 -- 请求正文(表示要上传的内容,可以没有)
报头
报头部分(请求行和请求报头)都以回车换行符(/r/n)为分隔
- 虽说是一行一行的,但实际在io时还是以字节为单位,毕竟回车/换行符都是字符
- 就像我们在网络计算器里那样,虽然我们以换行符为分隔符,但还是把读出来的数据当做一个大字符串来看待的,只是打印的格式是一行一行的而已
请求行
请求行的字段分为三部分,以空格分隔
- 请求方法 url 请求的协议版本
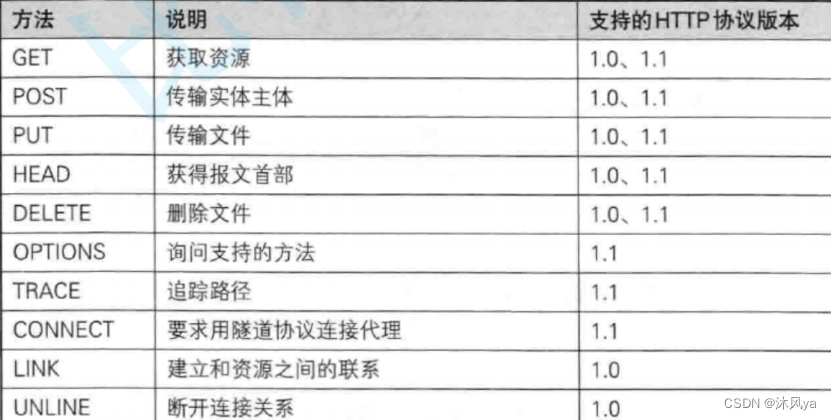
请求的方法
非常多:
绝大部分是两种:
- GET
- POST
其中
- get方法用于获取资源
- get和post方法都可以上传数据,只是上传的方式不同
url
用于定位要请求资源的位置
- 一般是从第一个/往后的内容(可能少部分请求会带域名)
请求的协议版本
浏览器支持的协议版本
- 最常见 的是1.0 , 1.1 , 2.0
- 最最常见的是1.1 -- 格式 HTTP/1.1
请求报头
以多行构成,都是http请求的请求属性
以键值对组成 -- key: value
如何区分报头和有效载荷
我们之前在网络计算器里是使用\n这个分隔符区分的
http这里,是增加了一个空行(只有\r\n)
- 可以把它视作第四部分,让它作为二者的分隔符
- 所以我们在读取时只需要按行读取,一旦读到的内容是空的,就说明已经将报头读完了
如何读取正文
虽然我们能知道报头如何读完,那正文呢?
我们连正文有没有都不清楚,即使有,有多少呢,如何知道自己读完了呢?
- 其实,我们上面有说到,请求报头里记录的是请求的属性
- 那么属性里会有一个字段content_length可以记录正文的长度
- 拿着这个长度,就可以在空行后读取对应长度的字节,拿到完整的正文
结构图示

http响应
查看响应格式
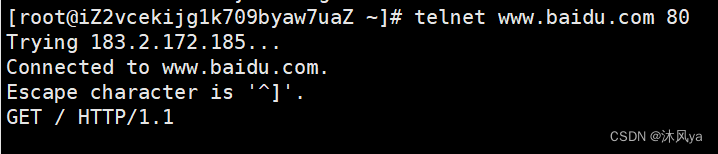
telnet
连接百度官网试试
以下是我们连接并发送请求的语句:
收到的结果:
根据看到的结果,会发现它和请求格式非常类似
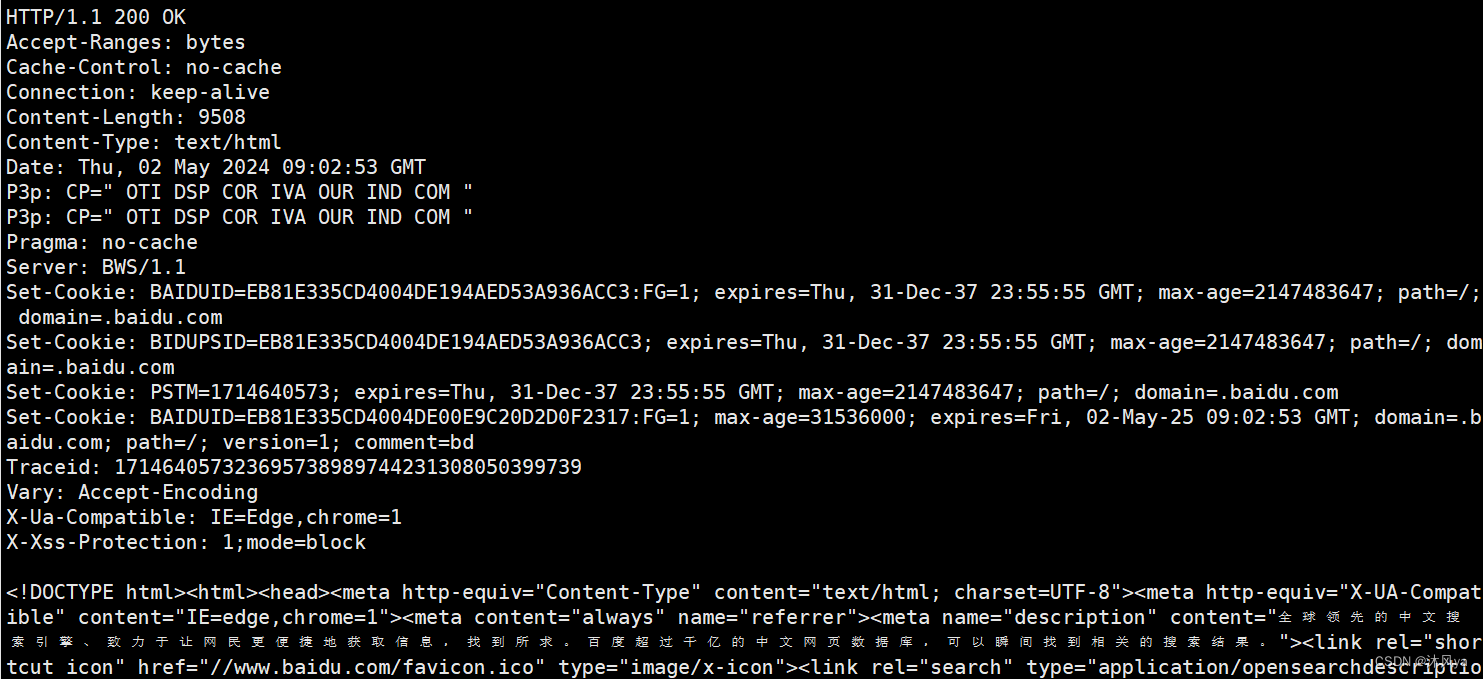
图示

状态行
根据看到的结果,状态行也分为三部分 -- http服务端的协议版本 状态码 状态描述
- 以空格为分隔符
http服务端的协议版本
为什么双方都要告知这个协议版本号呢?
- 因为两者不一定是同一版本的
- 引入 -- 为了软件的兼容性,服务端需要支持多个客户端版本
- 为了确保提供的服务符合版本,需要告知服务端,客户端使用的是哪个版本
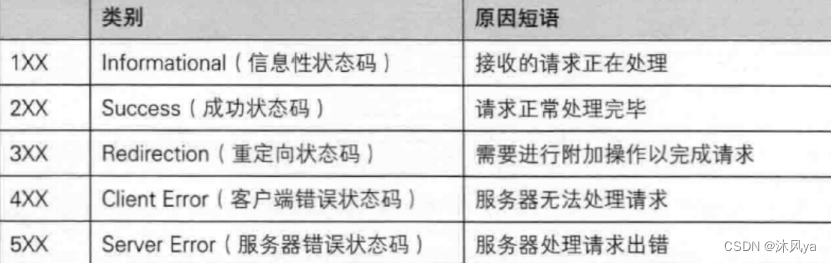
状态码
用于标识请求的状态
其中,1开头的我们很少见到
- 如果响应时间较长,http会及时向浏览器响应,说明自己正在处理中
2开头的比较常见,比如说我们刚刚的示例中表示成功的200
- 它就表示我们受理这个请求成功并且处理完毕,返回的就是正式的response
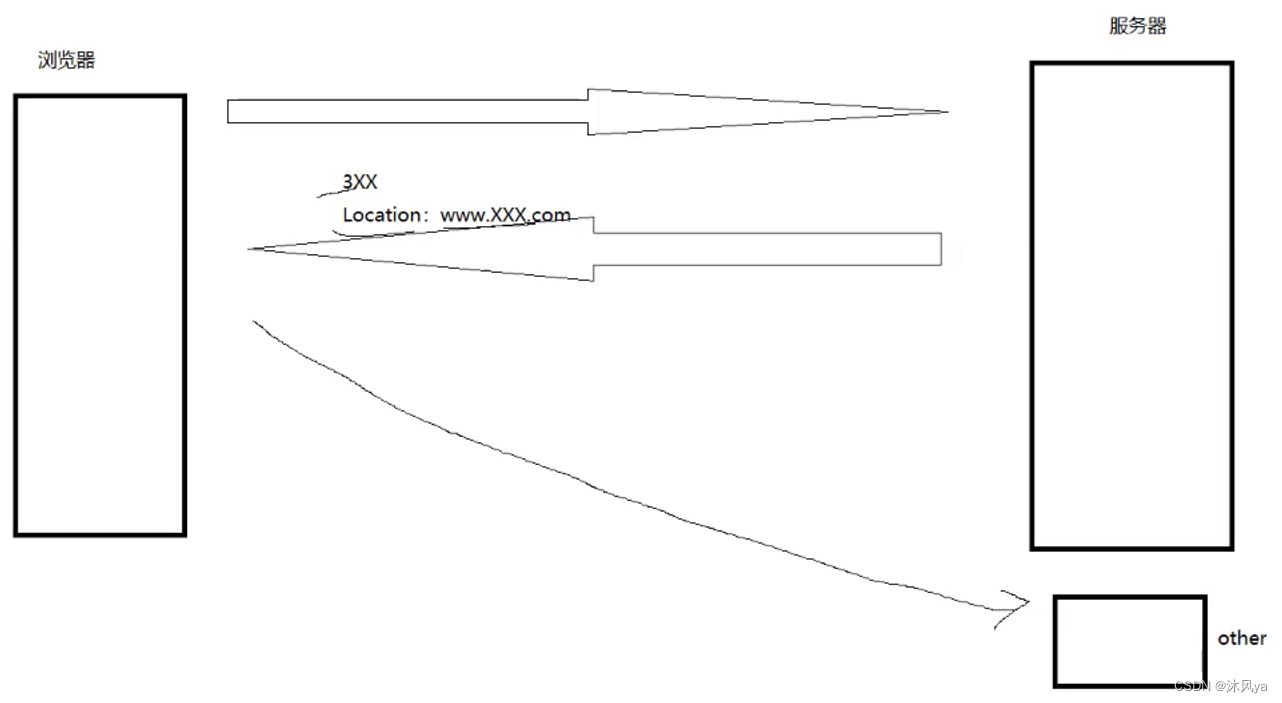
3开头的表示要重定向(在下面的报头字段里会再介绍一点)
- 就是指服务端会进行二次请求:
- 其中分为临时重定向(302)和永久重定向(301)
类比到现实中:
- 临时重定向 -- 因为某个原因,某节课在另一个教室上
- 永久重定向 -- 某家店搬迁到新地址了
回到http里,举一些会运用重定向的例子:
- 临时重定向 -- 某个网站需要登录,登录成功后会自动跳转到首页
- 永久重定向 -- 某个网站做不下去了,换了一个新域名(它有些会提示,有些就直接跳转)
4开头的表示客户端错误,一般如果网络没有错误的话,要么是客户端出错,要么是服务端出错
- 以及我们经常看见的404(Not Found),表示请求的资源不存在
- (因为服务端只能提供它拥有的资源,而用户却请求了它没有的资源,这自然属于不合理的请求,所以是客户端错误)
- 403(Forbidden)错误表示用户没有权限访问该资源
5开头的错误表示服务器错误
- 比如:它内部在处理时,需要拿到数据库数据,但却连接不上了 ; 创建线程/进程去处理请求,却创建失败了
状态描述
对状态码的描述字段
- 其实状态码和描述字段和我们之前的网络计算器的设计是一样的,有err_code,也有与之对应的字符串
- 并且,只要有请求,就一定有响应 (除非网络不好,没收到之类的)
其他两部分都和请求格式相同
http报头常见字段

content-type
用于表示当前资源的数据类型
- 如果不指定,默认识别成text/html类型,也就是文本类型
- 但如果我们想要在网页显示其他格式的资源,必须要指定,否则它无法正确解释
比如:网页中常出现的图片
- 它一般分为jpg / png格式
- 我们必须在content-type字段中填充它们对应的类型,才能被浏览器正确解析出来

referer
记录了当前页面的上一个页面
- 用于实现后退功能

location
当客户端浏览器向老版服务器发送请求时,如果该请求不支持/不想直接提供服务,就返回一个特定的响应:
- 3开头的状态码
- 报头字段带有location
指示客户端应该去新的地址发送请求
除了图中显示的这些字段,我们在实际代码里还会显示其他的字段:
connection
表示通信双方使用的是什么类型的连接
分为长连接和短连接
- 短连接 -- 一次连接仅支持处理一次请求,请求处理完毕则关闭连接
- 长连接 -- 一个网页通常对应多个资源(比如多个图片资源),它们都是需要不断发送http请求来获取的,而这里的一个连接可以支撑客户端获取多个资源,直到获取完毕
其中:
- HTTP/1.0版本默认使用的就是短连接(因为早期的网络资源比较少,使用短连接即可)
- 而1.1版本使用的则是长连接(一旦要获取的资源较多,一个连接=一个资源的方式太过低效,所以改为长连接)
这也就会导致,通信双方需要沟通各自的连接方式(毕竟即使它支持长连接,也可以不使用啊)
- 如何知道它们互相采用的是什么样的连接呢?
- 也就得依靠connection这个字段
- 如果双方都有connection字段,且都是keep-alive,则使用长连接
- 否则为短连接

fiddler
如果想要看见请求,需要使用抓包工具
比如:fiddler
原理
它会将主机的请求代为转发给服务器,然后将收到的服务器响应数据转发给主机
- 因为是工具替我访问,所以需要它重新连接远端
- vpn(也就是俗称的梯子)也是这个原理,代理替我们访问国外的服务端,然后再把响应转发给我们
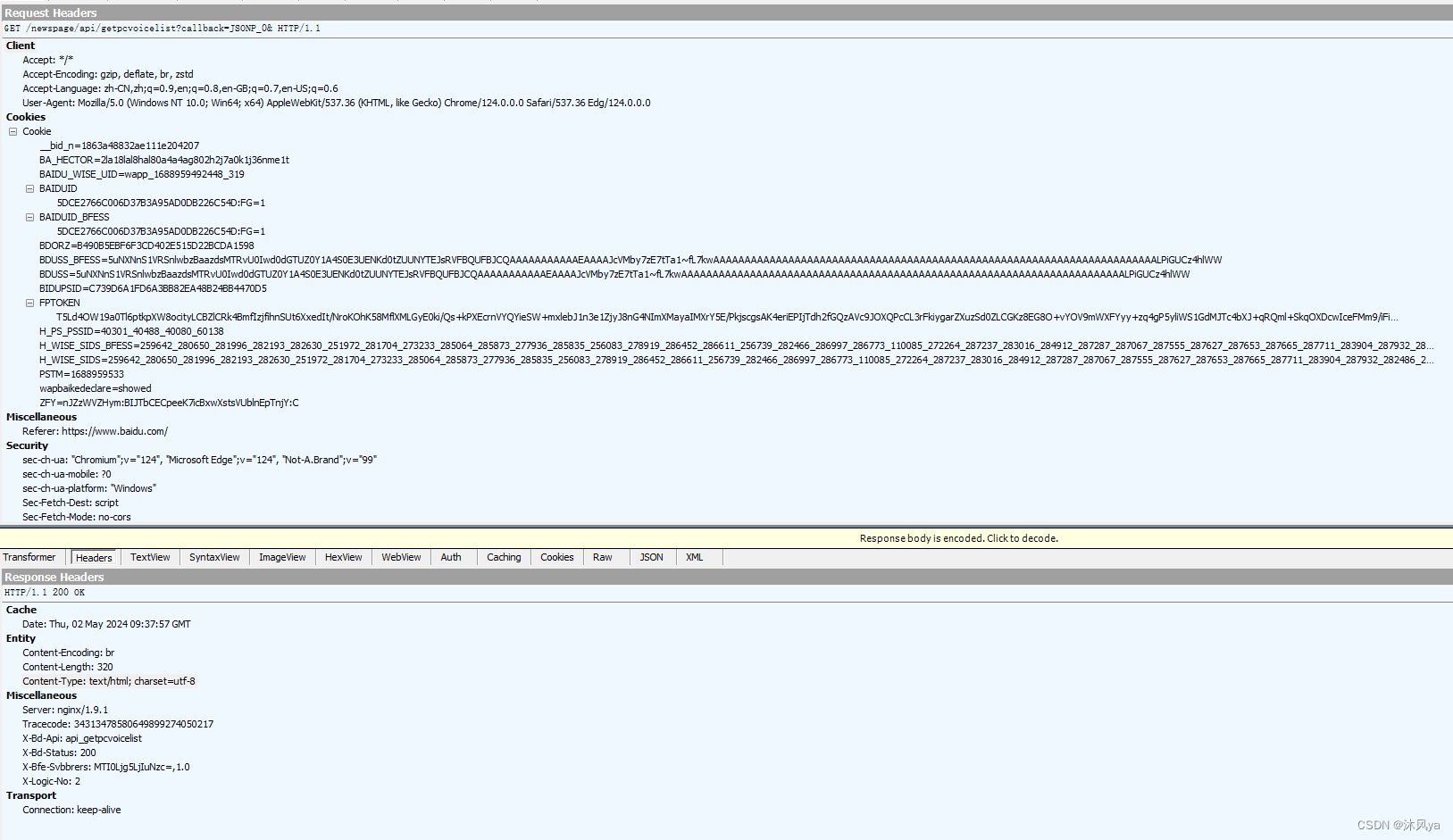
抓包结果
这个软件把报头和正文分成两个界面
请求在上面,响应在下面,均符合我们上面介绍的结构:

postman
也有类似浏览器的工具,可以帮我们构建请求,然后抓到响应
这篇关于域名介绍,url的介绍+原理+特殊字符的处理,网络行为,http协议请求/响应的格式+结构,状态码介绍,临时/永久重定向,http报头常见字段,fiddler的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




