本文主要是介绍rv1126的rknn1.7.5自有模型训练部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
几乎一年前, 弄过一次rv1126的平台的推理部署, 一年时间过去了, rknn从1.7.1, 进化到了1.7.5,原有的代码不太好用了, 因为最近有个客户要做1126平台的推理, 今天下午就花了几个小时, 从头再捋了一遍.
模型训练
这部分, 跟3588平台差不多, clone下yolov5的仓库, 并check out到7.0的版本.
git checkout tags/v7.0
保证是yolov5下面的这个版本:
我的训练集是之前那个训练集, 安全帽的, 包含训练, 测试, val, 类别就两个, person, 跟hat, 分别是戴帽子的人头, 跟不带帽子的人头.
仓库切到7.0commit之后, 修改models/common.py, 把default_act =nn.SiLU() 改成 ReLU

即把激活函数, 改为ReLU方式, 提升推理速度.
创建个data/safe_hat.yaml, 用于保存训练配置
path: ../person_hat-3/ # dataset root dir
train: images/train # train images (relative to 'path') 128 images
val: images/val # val images (relative to 'path') 128 images
test: images/test # test images (optional)# Classes
names:0: person1: hat
训练集目录结构:
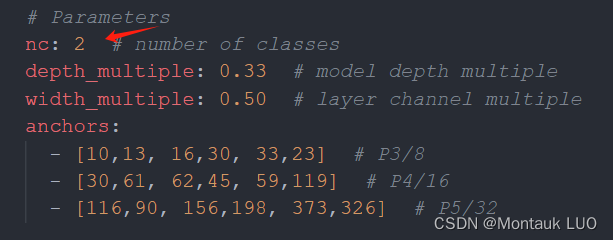
修改一下models/yolov5s.yaml, 将nc改为需要的类别数量, 这里是2
开启训练
python ./train.py --data ./data/safe_hat.yaml --cfg ./models/yolov5s.yaml --weights '' --batch-size 32 --epochs 120 --workers 0 --project safe_hat
没有问题的话, 开始训练了:
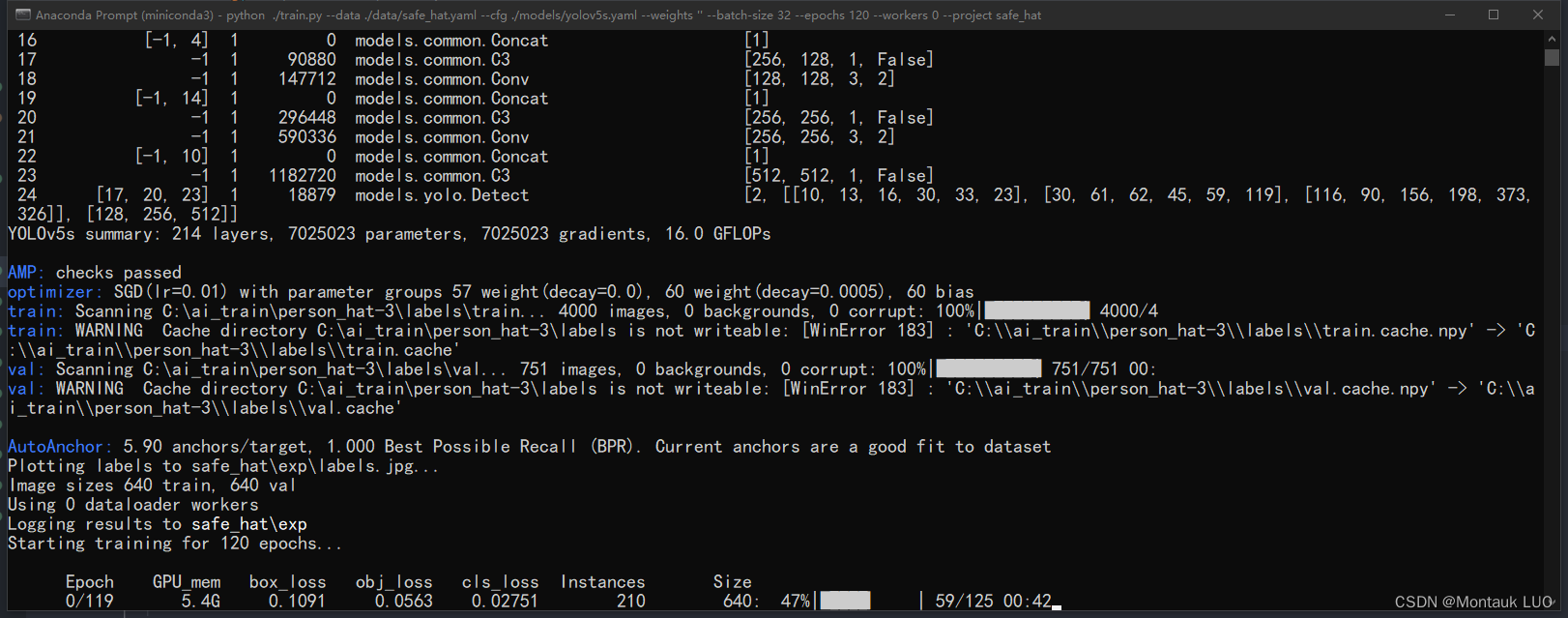
根据自己显存大小修改batch-size
根据模型精确度选择模型大小跟epochs数量, 并观察mAP变化.

120个epoch之后, mAP50是0.947, 差不多了.
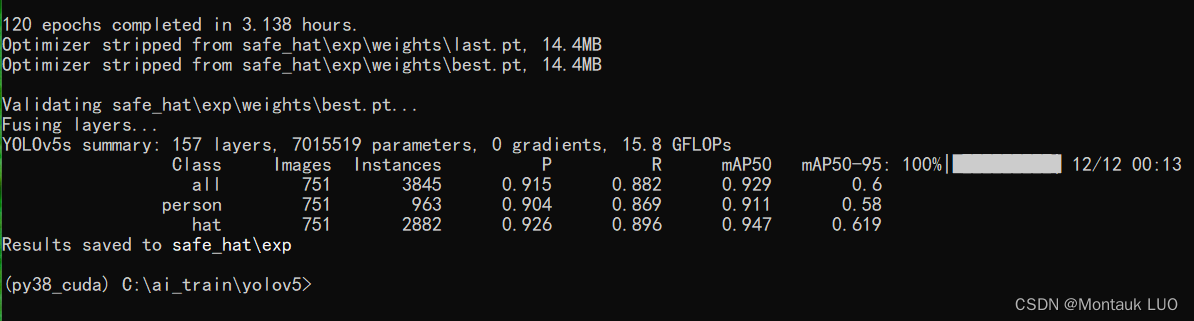
先测试一下, pt到底好不好用.
python detect.py --source C:\ai_train\person_hat-3\images\test\person_hat_2_534.jpg --weight C:\ai_train\yolov5\safe_hat\exp\weights\best.pt --view-img

有两个框的原因是这个图片是上下镜像了一下.
结果是ok的. 接下来是转onnx.
模型转换
- 修改export.py
shape = tuple((y[0] if isinstance(y, tuple) else y).shape) # model output shape
这一行, 改成:
shape = tuple((y[0] if (isinstance(y, tuple) or (isinstance(y, list))) else y).shape) # model output shape
- 修改models/yolo.py
将def forward(self, x): forward函数改为:
z = []
for i in range(self.nl):
x[i] = self.mi
return x[0],x[1],x[2]

转换成onnx, 注意, 这里别用优化参数
python export.py --weights C:\ai_train\yolov5\safe_hat\exp\weights\best.pt --include onnx
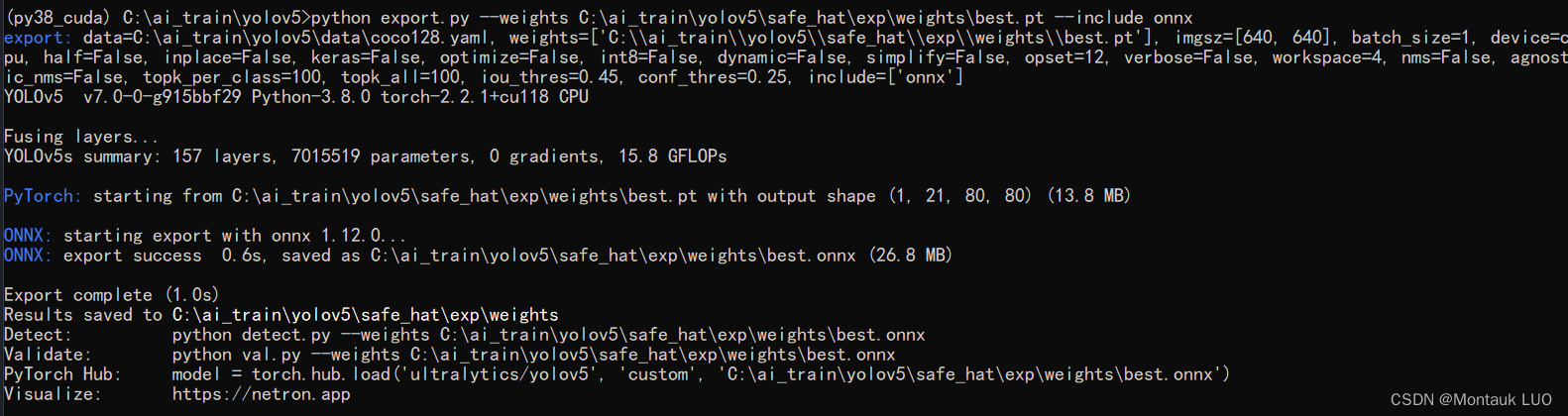
顺利的话, 会生成对应的onnx文件.
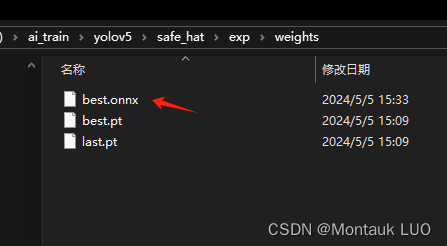
将这个best.onnx改个名字, 就叫safe_hat.onnx吧
- onnx转rknn 这部分比较重点:
安装rknn_toolkit_175过程略过
使用这个test.py
import os
import urllib
import traceback
import time
import sys
import numpy as np
import cv2
from rknn.api import RKNNONNX_MODEL = "safe_hat.onnx"
RKNN_MODEL = "safe_hat.rknn"
IMG_PATH = "./person_hat_2_1761.jpg"
DATASET = "./dataset.txt"QUANTIZE_ON = TrueBOX_THRESH = 0.5
NMS_THRESH = 0.6
IMG_SIZE = 640CLASSES = ("person", "hat")def sigmoid(x):return 1 / (1 + np.exp(-x))def xywh2xyxy(x):# Convert [x, y, w, h] to [x1, y1, x2, y2]y = np.copy(x)y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left xy[:, 1] = x[:, 1] - x[:, 3] / 2 # top left yy[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right xy[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right yreturn ydef process(input, mask, anchors):anchors = [anchors[i] for i in mask]grid_h, grid_w = map(int, input.shape[0:2])box_confidence = sigmoid(input[..., 4])box_confidence = np.expand_dims(box_confidence, axis=-1)box_class_probs = sigmoid(input[..., 5:])box_xy = sigmoid(input[..., :2]) * 2 - 0.5col = np.tile(np.arange(0, grid_w), grid_w).reshape(-1, grid_w)row = np.tile(np.arange(0, grid_h).reshape(-1, 1), grid_h)col = col.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)row = row.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)grid = np.concatenate((col, row), axis=-1)box_xy += gridbox_xy *= int(IMG_SIZE / grid_h)box_wh = pow(sigmoid(input[..., 2:4]) * 2, 2)box_wh = box_wh * anchorsbox = np.concatenate((box_xy, box_wh), axis=-1)return box, box_confidence, box_class_probsdef filter_boxes(boxes, box_confidences, box_class_probs):box_classes = np.argmax(box_class_probs, axis=-1)box_class_scores = np.max(box_class_probs, axis=-1)pos = np.where(box_confidences[..., 0] >= BOX_THRESH)boxes = boxes[pos]classes = box_classes[pos]scores = box_class_scores[pos]return boxes, classes, scoresdef nms_boxes(boxes, scores):x = boxes[:, 0]y = boxes[:, 1]w = boxes[:, 2] - boxes[:, 0]h = boxes[:, 3] - boxes[:, 1]areas = w * horder = scores.argsort()[::-1]keep = []while order.size > 0:i = order[0]keep.append(i)xx1 = np.maximum(x[i], x[order[1:]])yy1 = np.maximum(y[i], y[order[1:]])xx2 = np.minimum(x[i] + w[i], x[order[1:]] + w[order[1:]])yy2 = np.minimum(y[i] + h[i], y[order[1:]] + h[order[1:]])w1 = np.maximum(0.0, xx2 - xx1 + 0.00001)h1 = np.maximum(0.0, yy2 - yy1 + 0.00001)inter = w1 * h1ovr = inter / (areas[i] + areas[order[1:]] - inter)inds = np.where(ovr <= NMS_THRESH)[0]order = order[inds + 1]keep = np.array(keep)return keepdef yolov5_post_process(input_data):masks = [[0, 1, 2], [3, 4, 5], [6, 7, 8]]anchors = [[10, 13],[16, 30],[33, 23],[30, 61],[62, 45],[59, 119],[116, 90],[156, 198],[373, 326],]boxes, classes, scores = [], [], []for input, mask in zip(input_data, masks):b, c, s = process(input, mask, anchors)b, c, s = filter_boxes(b, c, s)boxes.append(b)classes.append(c)scores.append(s)boxes = np.concatenate(boxes)boxes = xywh2xyxy(boxes)classes = np.concatenate(classes)scores = np.concatenate(scores)nboxes, nclasses, nscores = [], [], []for c in set(classes):inds = np.where(classes == c)b = boxes[inds]c = classes[inds]s = scores[inds]keep = nms_boxes(b, s)nboxes.append(b[keep])nclasses.append(c[keep])nscores.append(s[keep])if not nclasses and not nscores:return None, None, Noneboxes = np.concatenate(nboxes)classes = np.concatenate(nclasses)scores = np.concatenate(nscores)return boxes, classes, scoresdef draw(image, boxes, scores, classes):for box, score, cl in zip(boxes, scores, classes):top, left, right, bottom = boxprint("class: {}, score: {}".format(CLASSES[cl], score))print("box coordinate left,top,right,down: [{}, {}, {}, {}]".format(top, left, right, bottom))top = int(top)left = int(left)right = int(right)bottom = int(bottom)cv2.rectangle(image, (top, left), (right, bottom), (255, 0, 0), 2)cv2.putText(image,"{0} {1:.2f}".format(CLASSES[cl], score),(top, left - 6),cv2.FONT_HERSHEY_SIMPLEX,0.6,(0, 0, 255),2,)def letterbox(im, new_shape=(640, 640), color=(0, 0, 0)):# Resize and pad image while meeting stride-multiple constraintsshape = im.shape[:2] # current shape [height, width]if isinstance(new_shape, int):new_shape = (new_shape, new_shape)# Scale ratio (new / old)r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])# Compute paddingratio = r, r # width, height ratiosnew_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh paddingdw /= 2 # divide padding into 2 sidesdh /= 2if shape[::-1] != new_unpad: # resizeim = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))left, right = int(round(dw - 0.1)), int(round(dw + 0.1))im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add borderreturn im, ratio, (dw, dh)if __name__ == "__main__":# Create RKNN objectrknn = RKNN()if not os.path.exists(ONNX_MODEL):print("model not exist")exit(-1)# pre-process configprint("--> Config model")rknn.config(reorder_channel="0 1 2",mean_values=[[0, 0, 0]],std_values=[[255, 255, 255]],optimization_level=3,target_platform="rv1126",output_optimize=1,quantize_input_node=QUANTIZE_ON,)print("done")# Load ONNX modelprint("--> Loading model")ret = rknn.load_onnx(model=ONNX_MODEL)if ret != 0:print("Load yolov5 failed!")exit(ret)print("done")# Build modelprint("--> Building model")ret = rknn.build(do_quantization=QUANTIZE_ON, dataset=DATASET)if ret != 0:print("Build yolov5 failed!")exit(ret)print("done")# Export RKNN modelprint("--> Export RKNN model")ret = rknn.export_rknn(RKNN_MODEL)if ret != 0:print("Export yolov5rknn failed!")exit(ret)print("done")# init runtime environmentprint("--> Init runtime environment")ret = rknn.init_runtime("rv1126", device_id="a9d00ab1f032c17a")if ret != 0:print("Init runtime environment failed")exit(ret)print("done")# Set inputsimg = cv2.imread(IMG_PATH)# img, ratio, (dw, dh) = letterbox(img, new_shape=(IMG_SIZE, IMG_SIZE))img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)img = cv2.resize(img, (IMG_SIZE, IMG_SIZE))# Inferenceprint("--> Running model")outputs = rknn.inference(inputs=[img])# post processinput0_data = outputs[0]input1_data = outputs[1]input2_data = outputs[2]input0_data = input0_data.reshape([3, -1] + list(input0_data.shape[-2:]))input1_data = input1_data.reshape([3, -1] + list(input1_data.shape[-2:]))input2_data = input2_data.reshape([3, -1] + list(input2_data.shape[-2:]))input_data = list()input_data.append(np.transpose(input0_data, (2, 3, 0, 1)))input_data.append(np.transpose(input1_data, (2, 3, 0, 1)))input_data.append(np.transpose(input2_data, (2, 3, 0, 1)))boxes, classes, scores = yolov5_post_process(input_data)img_1 = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)if boxes is not None:draw(img_1, boxes, scores, classes)# cv2.imshow("post process result", img_1)# cv2.waitKeyEx(0)# save resultcv2.imwrite("result.jpg", img_1)rknn.release()这个脚本支持联板调试, 需要修改onnx模型的名字, rknn模型的名字, 连扳测试用的jpg
这个时候, 把1126的板子的otg口用usb插接好, 给1126通上电.
这个时候如果运行adb devices可以看到1126是在线的.
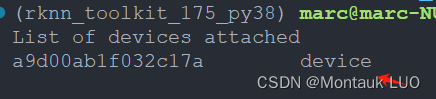
记录一下这个device id
修改CLASSES

device_id
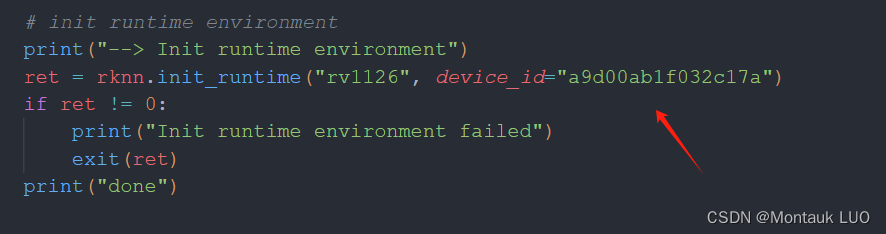
device_id改成自己1126的adb设备id
这个脚本最后会进行联板调试, 并生成一个rknn模型文件.
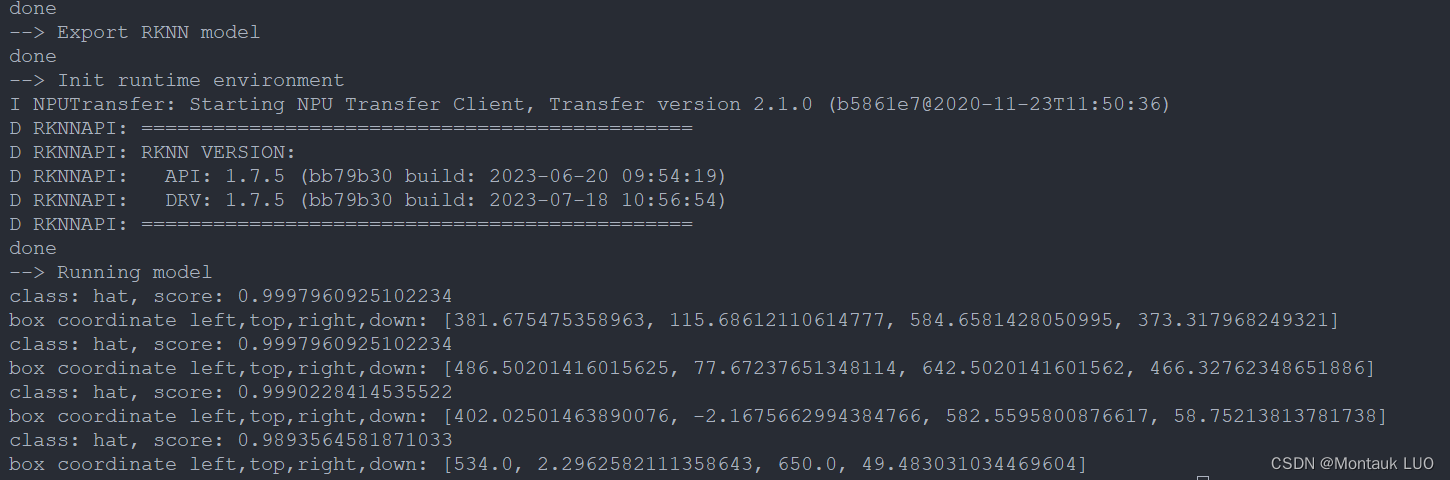
最后还会生成一个result.jpg
可以看到结果是ok的.

到这一步, rknn差不多就ok了.
修改应用, 类别数量, 模型文件名, 让我们看看效果:
值得注意的是, 我这个项目中推理部分单独做成了一个动态库.
记得把动态库adb push到板子上.
推理库:
https://github.com/MontaukLaw/yolo_detect_lib
应用:
https://github.com/MontaukLaw/single_vi_chn_yolo_rknn_rtsp
跑起来:

识别没问题, 类别文本后面的数字表示的是到某个点的距离(某个项目客户的要求), 而不是置信度.
置信度打印出来了.
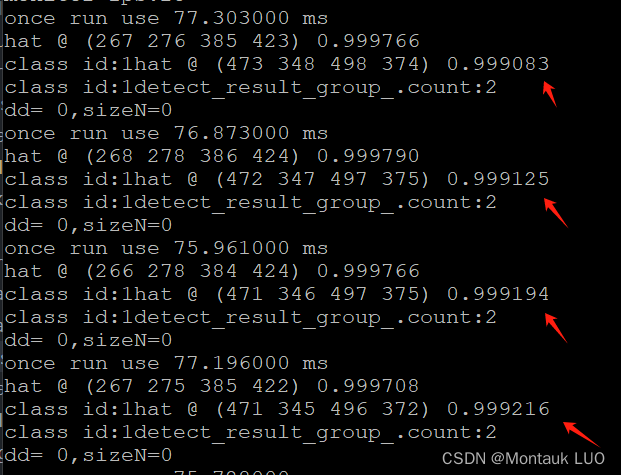
至此, 模型是ok的, 但是现在模型还不是预编译模型, 每次执行都会花1分钟左右初始化, 这个时候, 为了提升初始化的速度, 可以考虑使用脚本对模型进行预编译转换.
import sysif __name__ == '__main__':if len(sys.argv) != 3:print('Usage: python {} xxx.rknn xxx.hw.rknn'.format(sys.argv[0]))print('Such as: python {} mobilenet_v1.rknn mobilenet_v1.hw.rknn'.format(sys.argv[0]))exit(1)from rknn.api import RKNNorig_rknn = sys.argv[1]hw_rknn = sys.argv[2]# Create RKNN objectrknn = RKNN()# Load rknn modelprint('--> Loading RKNN model')ret = rknn.load_rknn(orig_rknn)if ret != 0:print('Load RKNN model failed!')exit(ret)print('done')# Init runtime environmentprint('--> Init runtime environment')# Note: you must set rknn2precompile=True when call rknn.init_runtime()# RK3399Pro with android system does not support this function.ret = rknn.init_runtime(target='rv1126', rknn2precompile=True)if ret != 0:print('Init runtime environment failed')exit(ret)print('done')ret = rknn.export_rknn_precompile_model(hw_rknn)rknn.release()使用方法就是
python export_rknn_precompile_model.py safe_hat.rknn safe_hat_precompile.rknn
即将非预编译模型, 转成预编译模型.
同样push到板子上, 跑起来, 就不用等待模型初始化等一分钟了.
这篇关于rv1126的rknn1.7.5自有模型训练部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








