本文主要是介绍山东大学软件学院创新项目实训开发日志——第10周,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
山东大学软件学院创新项目实训开发日志——第10周
项目名称:ModuFusion Visionary:实现跨模态文本与视觉的相关推荐
-------项目目标:
- 本项目旨在开发一款跨模态交互式应用,用户可以上传图片或视频,并使用文本、点、框等提示,精确分割出图片或视频中指定的物体,或者无提示地分割出所有物体。
- 基于分割出的物体,用户可以选择生成感兴趣的其他图片或视频。
- 内置推荐算法可以自动根据分割结果,推荐与之相关的信息。
本周完成的任务
1、添加了项目新功能:图生图
(1)所依赖模型:Stable-Diffusion
- Stable-Diffusion在具有“文生图”功能的同时,也提供了“图生图”功能。
- 并且“图生图”可以加入文本对其修改方向进行控制,具有一定的可控度。
- 模型部署在服务器上,本地通过将指定指令上传到服务器,服务器将生成结果写回本地,再传给前端展示。
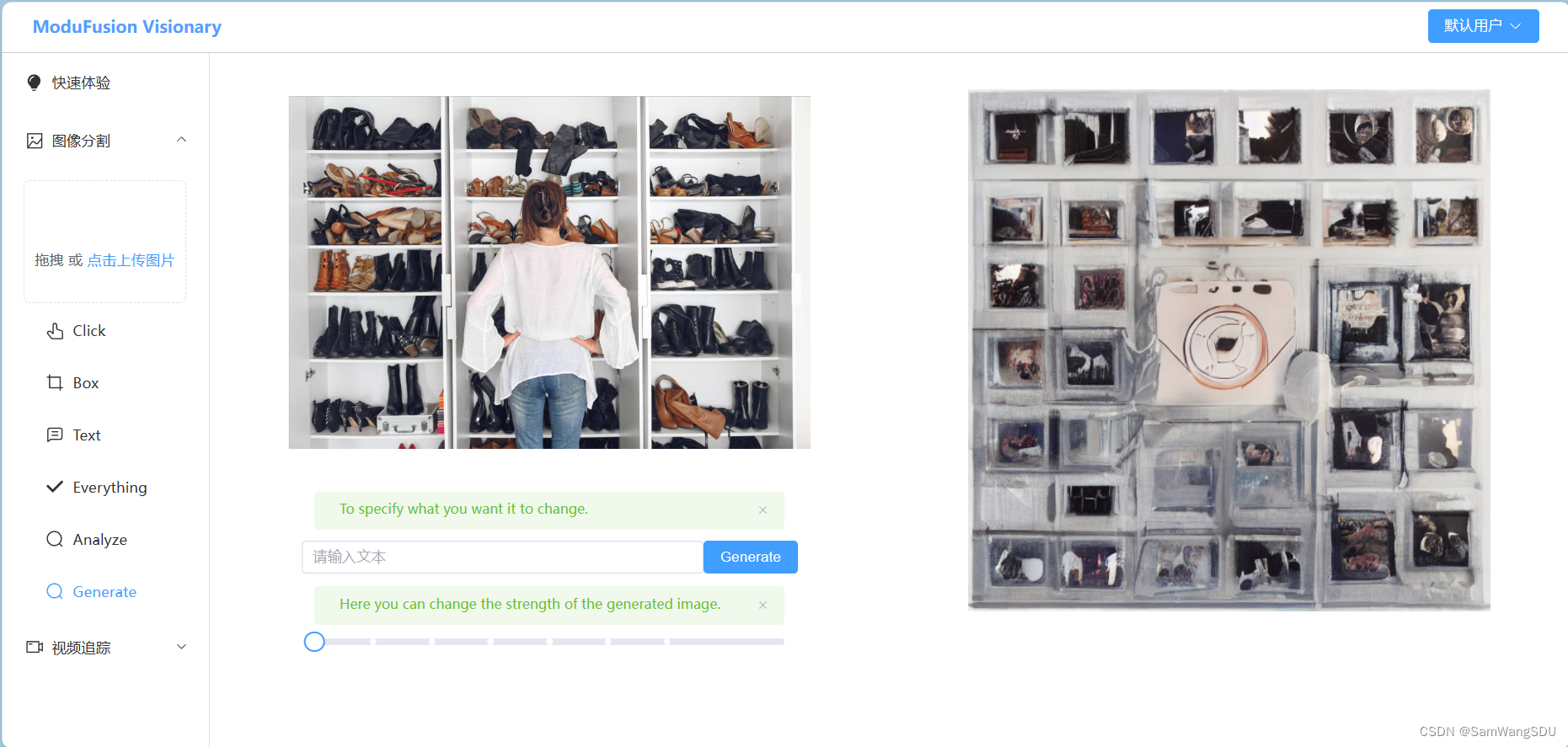
(2)功能概述:
- 用户点击侧边栏的“Generate”选项,即可进入图生图界面,用户可以在这里根据之前上传的图片生成与之相关的图片。
- 提供了“Strength”拖动条,用户可以选择合适的“strength”参数,用于控制生成的图片相对于原图片的变化幅度。
- 当用户不给予任何文本提示时,默认对原图片进行内容抽象;当用户给予文本提示时,会在原图片的基础上修改文本提示的内容。
(3)功能示例:
对于下面这张图片,当我们希望改变图中女人的穿着时,输入文本提示,“the woman wears a red shirt”,同时设置“strength”为0.75,生成的图片中女人便穿上了“red shirt”。


2、优化了图片分析功能
之前的图片分析功能是,当点击侧边栏的“Analyze”时,便自动开始对图片进行分析,期间将陷入很长时间的等待,这对于用户的体验非常不好,因为在此期间并不能看到分析界面究竟是什么样子,因此对其进行了功能分离:
- 当点击“Analyze”时,不再是直接陷入处理等待,而是进入"Analyze"界面。
- "Analyze"界面展示用户上传的图片,并提供了操作提示,引导用户进行操作。
- 用户可以点击“分析”按钮,对图片内容进行分析,分析结果将展示出来。
- 用户可以根据分析的结果点击“Recommend”按钮,系统将为其推荐相关图片。
- 添加了功能:用户可以自行输入文本,系统将根据用户输入的文本内容进行推荐,即实现“文生图”的裸自由性。

3、区别:
新功能“图生图”可以输入文本内容进行生成,而图片分析那里也可以输入文本内容进行生成,这两者有什么区别呢?
- “图生图”侧重在于根据原始图片的内容进行生成,生成的新图片都是在原图片的基础上改变的。
- 图片分析那里的图片生成则是纯粹的“文生图”。
下一阶段工作计划
- 优化当前界面响应逻辑,处理当前存在的小bug。
- 尽快部署完成视频帧定位功能。
这篇关于山东大学软件学院创新项目实训开发日志——第10周的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






