本文主要是介绍【视频超分】《BasicVSR: The Search for Essential Components in Video Super-Resolution and Beyond》CUHK 2012,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要:相比图像超分任务,视频超分网络会设计更多模块,因为它多了一个时空维度。因此复杂的设计结构在视频超分网络中是常见的。本文希望解开其中的要点,重新思考指导视频超分网络设计的基础模块,比如网络传播、对齐、聚合和上采样。通过重新设计已有的模块,本文提出了一个简洁的视频超分网络设计框架(BasicVSR),实验显示本文的方法优于SOTA的视频超分方法。另外,本文在BasicVSR框架的基础上提出了IconVSR超分网络,为了促进信息聚合设计了两个模块(1)信息重新填充机制。(2)成对传播策略。
主要贡献点:
1. 重新分析了视频超分网络中的四大模块(网络传播、对齐、聚合和上采样)的作用,以及它们的优缺点。提出了一个基础的视频超分框架BasicVSR,并在Reds和Vimeo数据集上验证了该框架的有效性。
2. 扩展BasicVSR框架,设计了信息重新填充机制和成对传播策略,促进信息聚合,即IconVSR网络。
方法
首先,本文分析了视频超分网络中网络传播方式、对齐、聚合和上采样四大模块的作用,实验观察到选择合适的传播方式和对齐形式可以带来大的效率提升。实验观察如下图所示。

本文建议使用双向传播策略做特征信息聚集,使用光流评估计算相邻帧之间的相关性,并以此为依据做特征对齐。在以上分析和观察的基础上,本文提出了一种在速度和性能上更优的视频超分框架BasicVSR。实验显示相比SOTA方法,本文所提方法BasicVSR的性能更优(PSNR 高 0.61db,速度快24倍)。另外,拓展方法IconVSR的性能相比BasicVSR更好, PSNR高0.31db。主网络结构图如下图所示。
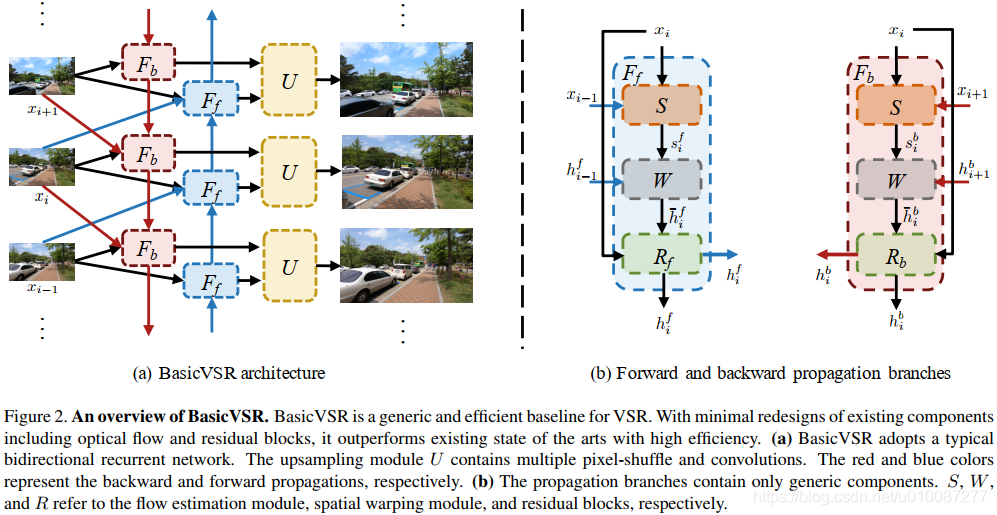
该网络的主要特点是1.使用双向传播策略加强特征信息传播;2.使用光流评估模块做特征对齐。另外两个模块使用通用结构:聚合模块使用通用特征concate结构,上采样模块使用通用的pixel-shuffle结构。下面分别分析这四个部分。
1. 信息传播形式。在视频超分网络中通常有三种形式:局部传播(滑动窗)、单向传播(递归)和双向传播(递归)。
1.1 局部传播使用一个滑动窗中的LR图像作为输入,然后利用这些局部信息完成重建任务。因此,它能够访问的信息限制在这些局部相邻帧中。缺少远距离帧不可避免地限制了该网络的表达潜力。如下图所示,当K减少,视频段中包含的帧数越多,相应的PSNR越高。这说明长距离的视频帧信息有利于重建任务。
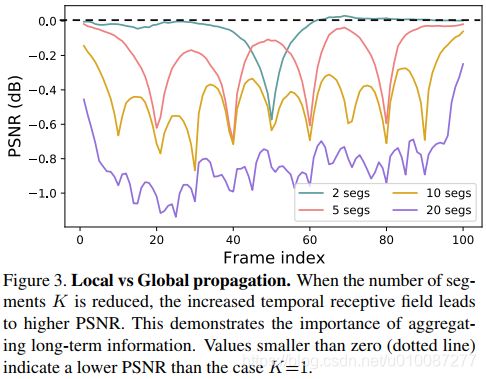
1.2 单向传播可以很好地解决上述问题。视频帧信息从第一帧到最后一帧逐帧传播。但是在这种传播形式下, 视频段中每帧接收的信息是不平衡的。第一帧无法接收后面帧的信息,而最后一帧可以接收前面所有帧的信息。因此,靠前的帧只能获得子优化结果。如下图所示,在早期时间步(0-5),单向传播的PSNR远低于双向传播,只使用部分帧(10-40)信息时比双向传播低0.5db左右。还可以看到,随着帧数增加,网络获得的视频帧信息增加,这种差距慢慢缩小。

1.3 双向传播可以很好的解决上述两个问题。BasicVSR采用典型的双向传播结构。假设输入LR图像,它的相邻帧
和
, 来自于前向和反向的相关特征
和
。我们有
其中和
分别为反向分支和前向分支。
2. 对齐模块。在视频超分任务中空间对齐非常重要,因为它负责对齐那些高度关联但是空间位置不对齐的图像/特征,以进行后续聚合。主流的对齐模块可以分为三类:无对齐、图像对齐和特征对齐。
2.1 无对齐。现有的基于递归传播的视频超分方法通常不做对齐。但是不对齐的图像/特征阻碍了后续的特征聚合,导致了标准以下的结果。没有合适的对齐,传播的特征与输入视频帧在空间上不对齐。像卷积操作,只有相对较小的可接受域,它没有足够的能力来聚合响应位置的信息。实验显示相比有对齐的网络,无对齐网络产生了1.19db的下降。这表明采用大的可接受域,去聚合来自远距离帧的信息是非常重要的。
2.2 图像对齐。之前的工作通过计算光流,在重建之前warp图像的方式执行对齐操作。最近Chan[2]的工作显示将对齐操作从图像层面转移到特征层面能够带来显著的提升。实验显示相比特征层面对齐,图像层面对齐的PSNR低0.17db。
2.3 特征对齐。BasicVSR采用光流做空间对齐。不同于之前的工作(对图像执行warp操作),本文对中间特征执行warp操作,以获得更好的表现。然后对齐特征传给残差块做细节重建。
其中S和W分别表示光流评估和空间warping模块。指残差块堆叠结构。
拓展网络IconVSR
以BasicVSR作为基础网络,我们介绍两个新颖的结构:信息重新填充机制和成对传播组元,分别用来缓解信息传播过程中的误差累积和促进信息聚合。下面分别介绍这两个模块。
1. 信息重新填充机制。在图像边界和阻塞区域(occluded regions)的不精确对齐是一个显著挑战,它会导致误差积累,特别是当我们在网络中采用长时期传播。为了缓解这些误差特征带来的不利影响,我们提出了一个信息重新填充机制,以做特征修正。如下图所示
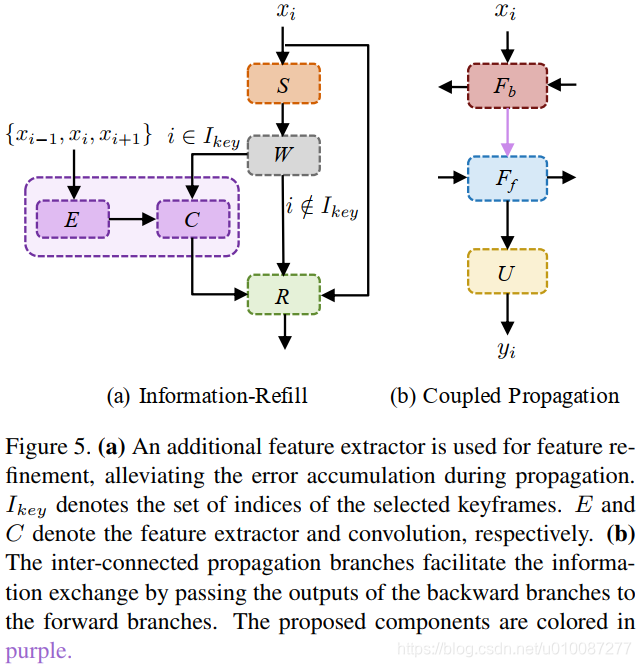
在上图(a)中
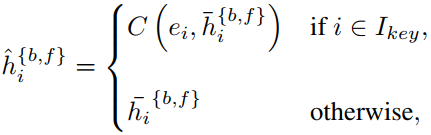
其中E和C分别对应特征提取器和卷积,表示选择的关键帧的索引集合。修正后的特征传给残差模块,做进一步的修复。
本文中特征提取器和特征混合只作用于稀疏选择的关键帧,所以它的计算量不大。
2. 成对传播连接。如图Figure5(b)所示,我们基于部分信息计算在每个传播分支中的特征,从之前的帧或者未来的帧。然后让传播模块内部连接。
通过成对传播连接,前向传播分支可以同时接收过去帧和未来帧的信息,这会带来更高质量的特征,由此获得更好的输出。
实验结果
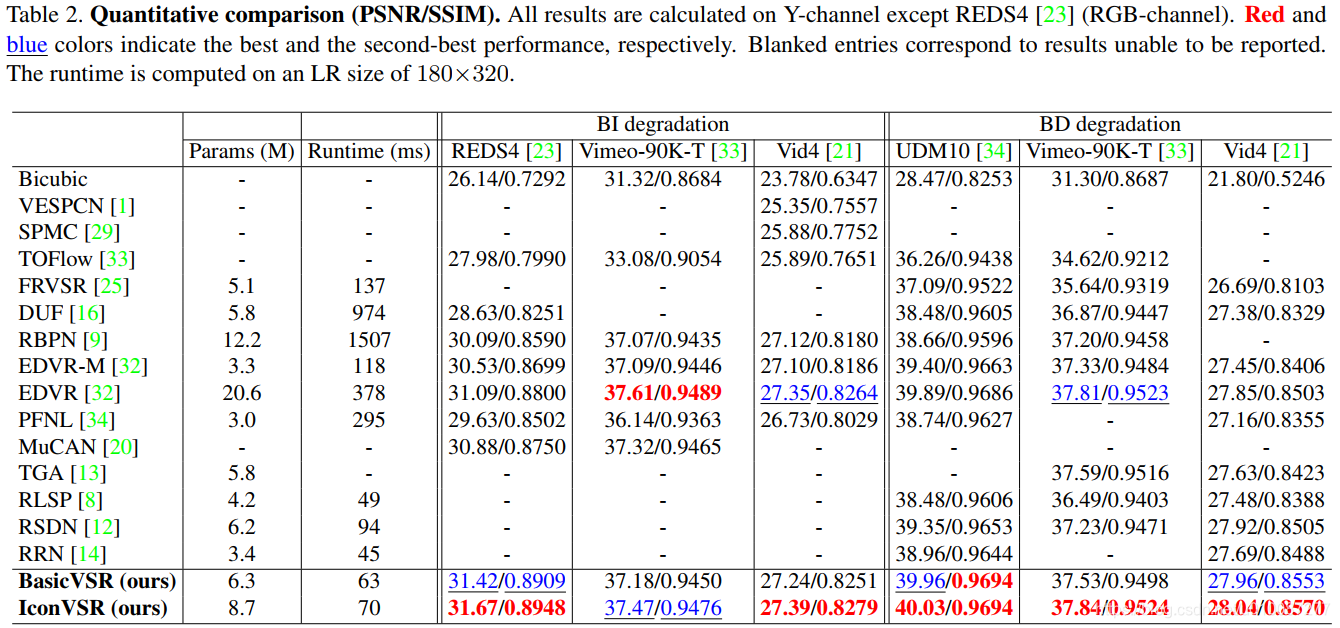
与STOA方法的综合性能比较

reference
[1].BasicVSR: The Search for Essential Components in Video Super-Resolution and Beyond.
paper:https://arxiv.org/abs/2012.02181v1
[2].Understanding Deformable Alignment in Video Super-Resolution.
paper:https://arxiv.org/abs/2009.07265v1
这篇关于【视频超分】《BasicVSR: The Search for Essential Components in Video Super-Resolution and Beyond》CUHK 2012的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





