本文主要是介绍redis 缓存一致性,缓存穿透,缓存雪崩,缓存击穿,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.缓存一致性:
缓存一致性就是通过各种方法保证缓存与数据库信息一种,其中最多的办法就是想尽一切办法对过期key进行清除,以保证redis和数据库信息一只,其中就包括了这篇文章中提到的内存淘汰策略,过期key的清除等等,当然也包括在代码中进行手动清除过期key,不过手动清除时需要注意要保证数据库的更新和redis的清除都成功完成,可以使用的方法包括,使用事务,使用相关服务将redis和数据库进行整合,或者只操作redis,再由redis操作数据库等等。
当我们选择手动事务更新数据库和redis保证其一致性时需要注意以下几点:
当我们更新数据库后,应该选择删除redis缓存,而不是更新,因为更新操作收益不大,并且操作繁琐容易出错。并且应该先更改数据库在删除缓存,因为更改操作耗时更长,如果先删除再修改,容易造成在修改过程中,数据被其他线程读取,然后向缓存中写入修改前的数据,而后删除则可以避免这种情况。
在高一致性的要求下可以采用手动更新数据库和redis,而低一致性的情况下可以使用redis自带的内存淘汰机制
2.缓存穿透
缓存穿透是指当一个数据为空时,缓存无法命中,数据库也无法命中,数据库无法命中导致无法写入redis,这样所有的请求都会涌入数据库,这就叫缓存穿透
解决方法分两种
1.返回null
当数据库没有数据时可以使redis缓存null值并且设置过期时间,这样便可以避免请求进入数据库,确实是会造成额外的性能损耗,以及当数据库存入数据时,在null过期时间之内无法访问到,会造成短时间内的数据不一致
2.布隆过滤
布隆过滤是将有可能会造成数据穿透的数据保存在一个极长的二进制数中,他会将这个数据经过十六个哈希函数的运算,最终映射到二进制数上
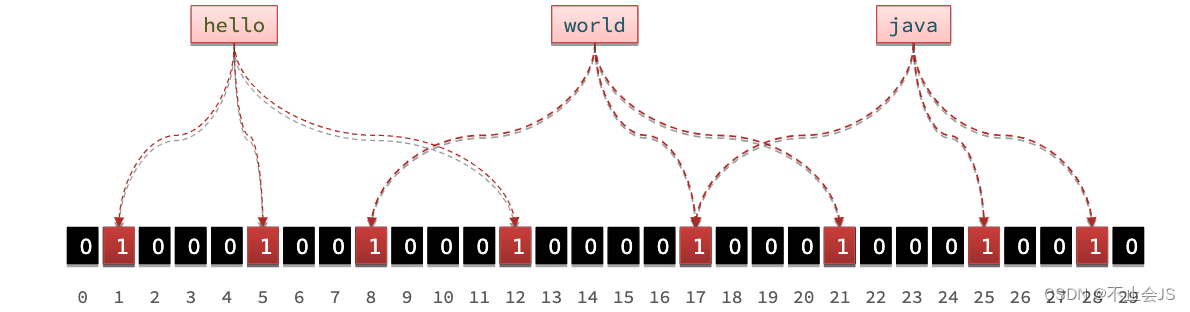
当再次请求这个数据时会先经过布隆过滤的十六个哈希函数,判断是否映射在了二进制数上,如果有则去访问,没有则不允许访问。当数据增多时,布隆过滤会造成误判,有可能将不存在的数据判定为存在,因为1过多,映射容易重复,不过概率极低
3.缓存雪崩
缓存雪崩是指同一时间大量key失效,或redis服务器宕机,导致大量请求涌入数据库。
解决方法包括:
1.设置不同的过期时间
通常,当我们设置缓存时,可能会给所有的缓存项设置相同的过期时间。这样做的问题在于,如果大量缓存同时过期,那么这些请求都会同时转到数据库上,可能会导致数据库瞬间压力过大。为了避免这种情况,我们可以对每个缓存项的过期时间添加随机的几分钟,这样缓存项的过期时间就会分散开来,避免同一时刻大量请求打到数据库。
2. 设置缓存重试策略
当缓存失效后,如果所有请求都立即转向数据库,数据库可能会处理不过来。我们可以设置一种机制,让这些请求不是立即都发送,而是通过一些延迟和重试的策略(比如,第一次失败后等待100毫秒,第二次失败后等待200毫秒),这样可以避免在极短的时间内给数据库带来过大的压力。
3. 使用熔断器
熔断器是一种自动开关机制,当检测到对数据库的请求过多时,它会暂时“断开”,阻止进一步的请求,以保护数据库。这可以防止在缓存失效后,大量请求直接涌向数据库造成的崩溃。
4. 预热缓存
预热缓存指的是在缓存正式到期和被删除前,系统自动地刷新缓存数据。这样,即使缓存条目过期,新的数据已经被加载并准备好,请求仍然可以从缓存中获取数据,而不需要去数据库中查询。
5. 使用分布式缓存
通过将缓存扩展到多个Redis服务器或使用其他分布式缓存系统,可以降低单个Redis实例出问题导致的影响。分布式缓存通过多个节点协作,即使某个节点出现故障,其他节点仍能提供服务。
6. 限流
限流是指对来自客户端的请求速率进行控制,确保系统在高流量时不会被过度负载。通过限制每秒处理的请求量,可以保护后端数据库不被过多的请求同时击垮。
4缓存击穿
缓存击穿是指一个用于大量高并发访问,并且缓存重建业务复杂的key失效,大量请求涌入数据库
解决方法分为两种
1.互斥锁
在线程访问redis失败,访问数据库的途中添加互斥锁,只有拥有锁的线程才能使用数据库数据并且重新构建缓存,其他线程只能等待该线程构建redis后使用缓存数据
2.逻辑过期
逻辑过期是互斥锁的加强版,他不在设置key的过期时间,而是通过字段的方式存储key过期时间,这样只有我们的代码特意查看时才会发现该key过期,而redis则不知道还会继续保留该key,而当一个线程发现过期时会获取锁并且重新构建redis,在这个过程中,其他没有获取锁的线程会继续用旧值完成业务。
这篇关于redis 缓存一致性,缓存穿透,缓存雪崩,缓存击穿的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!