本文主要是介绍Mysql报错红温集锦(一)(ipynb配置、pymysql登录、密码带@、to_sql如何加速、触发器SIGNAL阻止插入数据),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、jupyter notebook无法使用%sql来添加sql代码
可能原因:
1、没装jupyter和notebook库、没装ipython-sql库
pip install jupyter notebook ipython-sql
另外如果是vscode的话还需要安装一些相关的插件
2、没load_ext
%load_ext sql3、没正确的登录到mysql用户上
通过notebook添加mysql代码需要登陆对应的mysql用户和数据库
否则就会遇到$DATABASE_URL not set这种报错
sql.connection.ConnectionError: Environment variable $DATABASE_URL not set, and no connect string given.
怎么登录?格式如下

%sql mysql://A:B@C:D/E
A:用户名、B:密码
C:数据库服务器的IP地址,如果是连接本机就写 localhost
D:端口号,mysql默认的是3306,如果你改了设置就按你改的来
E:数据库名,例如经典的sakila
想看更细致的配置请看这篇文章,非常详细
如何在Jupyter Notebook里运行SQL? - 知乎 (zhihu.com)
二、最逆天的一集:密码带@怎么登录
典型报错是:
socket.gaierror: [Errno 11003] getaddrinfo failed
Connection info needed in SQLAlchemy format
也就是host获取的名字错误+格式问题
想一下,我们登录的格式是这样%sql mysql://A:B@C:D/E
密码B如果是 “abc@def” 就会导致def被认为是后面C的一部分,然后C就变成了 “def@C”,所以是socket的地址解析发生错误。
如果是普通的使用pymysql登录那没问题,因为密码是被独立出来了的
import pymysql
import sqlalchemy
# 数据库配置
config = {'host': 'localhost','user': 'root','password': 'abc@123','database': 'sakila','charset': 'utf8mb4','cursorclass': pymysql.cursors.DictCursor
}# 连接数据库
connection = pymysql.connect(**config)
cursor = connection.cursor()但如果是一句话直接输入就会变成这样
%sql mysql://root:abc@123@localhost:3306/sakila网上找了很多资料,没找到解决登录ipython-sql且密码带@的方法
偶然发现这个解析是可以使用URL编码的
在线编码转换工具(utf-8/utf-32/Punycode/Base64) - 编码转换工具 - W3Cschool
@就是%40,:就是%3A
除去@和:这些特殊符号,其他的符号应该都不会影响登录解析
所以改成把abc@123改成abc%40123就可以了
%sql mysql://root:abc%40123@localhost:3306/sakila另外一种解决方式就是新建一个user,授予他所有权限,让它的密码不带这些特殊符号,然后用它来登录。
三、to_sql怎么加速
Pandas to_sql详解-CSDN博客
这篇博客非常详细介绍了to_sql各个参数的含义
根据网上大佬的言论,在python中一条一条插入数据主要就是慢在反复连接数据库上
如果一次能够插入多个数据,就会很快了
根据这篇博客:pandas to_sql写入数据很慢_pandas,to_sql很慢,出现超时-CSDN博客
加入dtype之后就快了很多
import pandas as pd
from sqlalchemy import create_engine
from sqlalchemy.types import Integer
dfSTC=pd.DataFrame(TmpSTC,columns=['sno','tno','cno'])
print(dfSTC)connection_string = 'mysql://csq:csq@localhost:3306/xxx'
engine = create_engine(connection_string)
# dfSTC.to_sql('STC',con=engine,if_exists='append',index=False)
dfSTC.to_sql('STC',con=engine,if_exists='append',index=False,chunksize=10000,dtype={'sno':Integer(),'tno':Integer(),'cno':Integer()})但是在这之后,即便删掉dtype,也是一样的快,这让我很疑惑,无法复现慢速的to_sql了
下图,插入98万的数据只用了20s
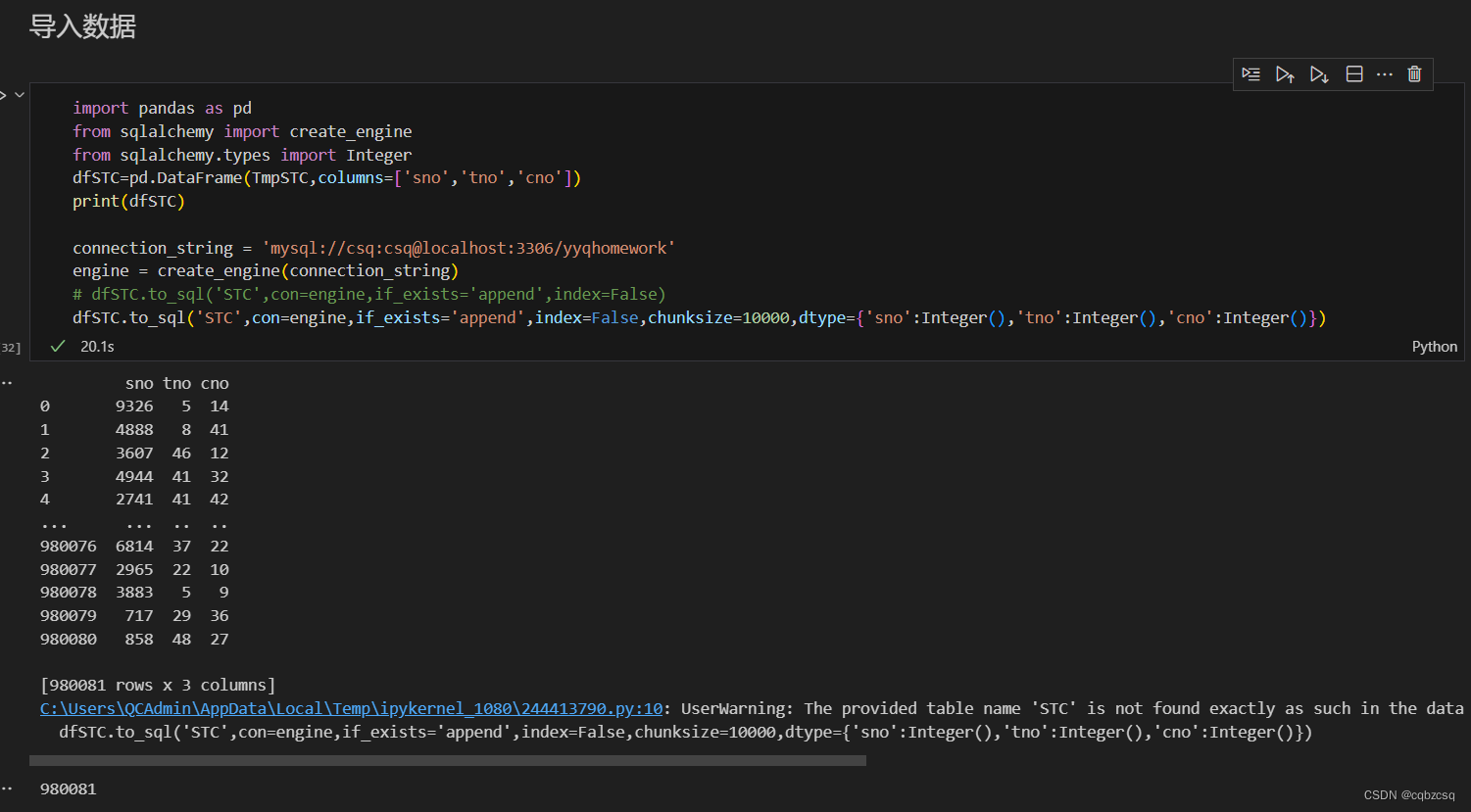
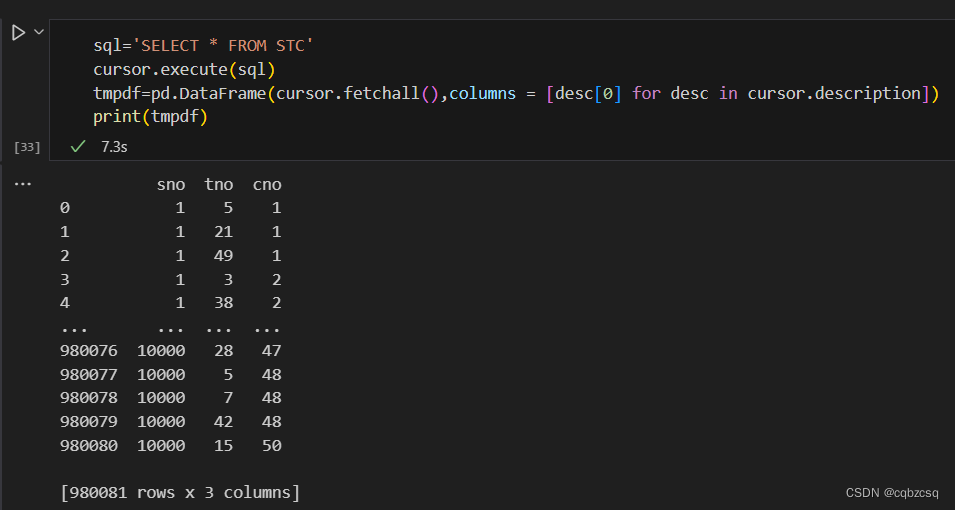
select一下,发现确实也插入进去了
有说法说sql插入的时候如果不规定dtype他会一直去推断类型,然后选择最大的类型,这会花很多时间,感觉也有道理。
而且我调整了一下chunksize,似乎并没有太大的影响,都是20s左右。
这个问题最后就不了了之了。
四、使用触发器阻止某条数据的插入与to_sql冲突了
在before insert的触发器里面写,当插入数据不满足某个条件时,直接使用mysql的SIGNAL语句raise一个报错出来,这样就会中断后续的插入事务
SIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = 'ASDF';但是如果想使用to_sql同时又加入这个类型的触发器,就会导致更加严重的问题
to_sql相当于一个批量插入的操作(?这点不确定)
如果在中途raise一个SIGNAL出来,就会导致整个insert的事务的中断,产生如下报错
OperationalError: (pymysql.err.OperationalError) (1644, 'ASDF')
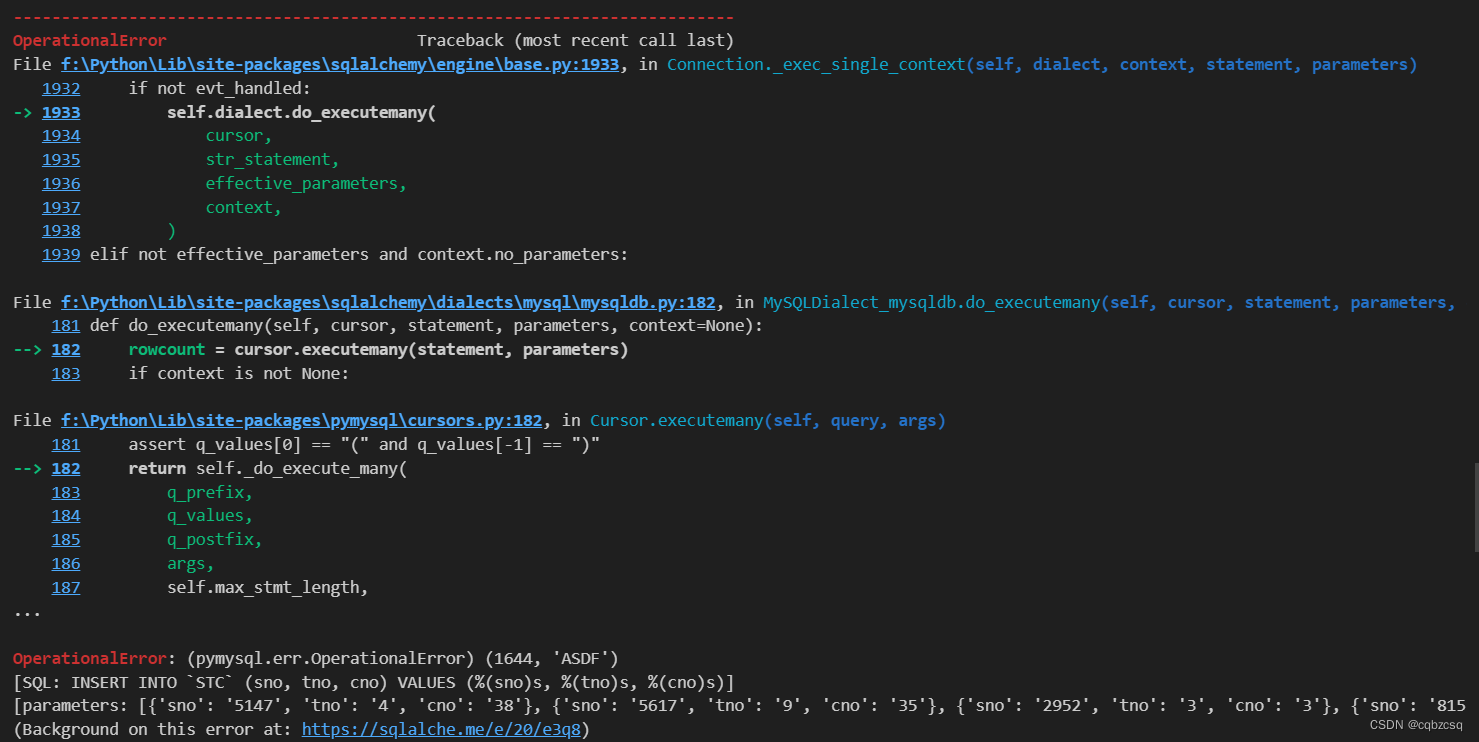
会发现这里的Error正是我们触发器中Raise的SIGNAL
所以,如果触发器中包含中断事务的话,最好不要和to_sql一类的函数使用(?
也就是这个问题现在还没法解决。。
但是
或许这只是问题的表面呢?
或许有更优秀的解决方法呢?
希望各路大神能够支支招解决这个问题
这篇关于Mysql报错红温集锦(一)(ipynb配置、pymysql登录、密码带@、to_sql如何加速、触发器SIGNAL阻止插入数据)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



