本文主要是介绍大模型T5,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

近年来,在大规模预训练语言模型上,各大公司的军备竞赛卷得十分激烈!
本文我们介绍Google推出的大一统模型——T5,同样是数据和实验多得让你瞠目结舌的论文,没错,就是在炫富,你有钱你也可以烧啊!(不过相比后来出现的GPT-3还是小巫见大巫)
T5论文:Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
1. 简介
T5 由谷歌的 Raffel 等人于 2020年7月提出,相关论文为“Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer”。
迁移学习技术在NLP领域的兴起,带来了一系列方法、模型和实践的创新。作者们提出了一种将所有的机遇文本的语言任务建模为文本到文本(text-to-text)的统一框架。作者系统研究了预训练目标、模型架构、未标注的数据集、迁移学习方法和其他因素在语言理解任务上的对比效果。通过一系列提升(规模和语料),T5在一系列摘要生成、问答、文本分类等任务中取得了SOTA的效果。
论文:https://arxiv.org/abs/1910.10683
代码:https://github.com/google-research/text-to-text-transfer-transformer
2. 概述
预训练可以让模型学习到可以被迁移到下游任务重的通用能力和知识。NLP中迁移学习通常通过未标注数据和非监督学习的方式实现,网络上每日数以TB级别的文本数据正好适用于训练更大的神经网络模型,达到更好的模型效果,因此近期涌现了很多种不同的NLP迁移学习方法,这些方法使用不同的预训练目标、不同的数据集、不同的benckmark和不同的fine-tuning方法。层出不穷的新模型、新方法,使得难以剖析新的贡献的效果,并了解现有转移学习方法的提升空间。为了更严格地分析,作者提出使用一种统一的迁移学习框架,从而能够系统地分析不同策略的效果和提升方向。
新框架的基本思想是把每一个文本相关的问题都建模为“文本到文本”问题。这样做的好处在于可以使用同一个模型、目标函数、训练和解码过程来对待每一个NLP任务,灵活性非常高;并且可以对比不同的迁移学习目标、标注数据和其他因素的影响,同时通过放大模型和数据的规模来探索NLP迁移学习的极限。
作者提出,他们并非想要提出一种新的方法,而是提出一种处理NLP任务的综合视角。因此,文章重点在综述现有方法和实证对比分析,为此将模型放大道极限(11B参数),为此他们构造了一个新的数据集(Colossal Clean Crawled Corpus, 简称C4),该数据集包含几百GB的从网上采集的干净的英文文本。
3. 模型架构
目前NLP领域的主流模式是先在大量无标签的数据上预训练一个语言模型,然后再在下游具体任务上进行有监督的fine-tune,以此取得还不错的效果。在这个模式下,各大公司争奇斗艳,各个机构奋起直追,今天A提出了一种预训练目标函数,明天B提出了另一种预训练目标函数,并且收集了更多的训练语料,后天C提出了参数更庞大的模型,采用了不同的优化策略......各家都声称自己是state-of-the-art,很难分析比较这些工作的有效贡献量。
因此,T5希望提出一个统一的模型框架,将各种NLP任务都视为Text-to-Text任务,也就是输入为Text,输出也为Text的任务。由此可以方便地评估在阅读理解、摘要生成、文本分类等一系列NLP任务上,不同的模型结构,预训练目标函数,无标签数据集等的影响。

T5:Text-to-Text Transfer Transformer
如图所示,T5(Text-to-Text Transfer Transformer)模型将翻译、分类、回归、摘要生成等任务都统一转成Text-to-Text任务,从而使得这些任务在训练(pre-train和fine-tune)时能够使用相同的目标函数,在测试时也能使用相同的解码过程。
注意这里回归任务对应的浮点数会被转成字符串看待,从而可以token by token的预测出来。虽然感觉奇怪,but anyway, it works。
T5模型结构
T5模型采用Transformer的encoder-decoder结构,之前介绍过GPT采用的是Transformer的decoder结构。

Transformer
T5模型和原始的Transformer结构基本一致,除了做了如下几点改动:
- remove the Layer Norm bias
- place the Layer Normalization outside the residual path
- use a different position embedding
T5与原生的Transformer结构非常类似,区别在于:
- 作者采用了一种简化版的Layer Normalization,去除了Layer Norm 的bias;将Layer Norm放在残差连接外面。
- 位置编码:T5使用了一种简化版的相对位置编码,即每个位置编码都是一个标量,被加到 logits 上用于计算注意力权重。各层共享位置编码,但是在同一层内,不同的注意力头的位置编码都是独立学习的。一定数量的位置Embedding,每一个对应一个可能的 key-query 位置差。作者学习了32个Embedding,至多适用于长度为128的位置差,超过位置差的位置编码都使用相同的Embedding。
T5(Text-to-Text Transfer Transformer)模型结构仍然是一个由Transformer层堆叠而成的Encoder-Decoder结构。Decoder 与Encoder很相似,但是Decoder中在自注意力层后还有一个标准的注意力层,这个标准的注意力层会将Encoder的输出参与到注意力的计算当中。Decoder的自注意力机制采用了自回归的通用注意力,即每个元素在计算注意力时只能考虑其前面位置的输出。Decoder 的最后一层,通过 Softmax 分类器输出每个元素属于每个词的概率,Softmax 分类器的权重与模型最前面的 Token Embedding 矩阵共享权重。
数据集C4
作者对公开爬取的网页数据集Common Crawl进行了过滤,去掉一些重复的、低质量的,看着像代码的文本等,并且最后只保留英文文本,得到数据集C4: the Colossal Clean Crawled Corpus。
作者基于Common Crawl ,通过删除 html 文件中的 markup 标和非文本内容,构造了大量文本数据。这些文本中包含大量的无效文本(非自然语言,例如菜单栏、错误信息、重复文本;无用文本,例如侮辱性语言、占位符文本、源代码等),作者利用以下启发式规则来清洗采集后的文本数据:
- 只保留以结束标点符号结束的行(即句号、感叹号、问号或末尾的引号)。
- 删除了少于5个句子的页面,只保留了至少包含3个单词的行。
- 删除了含有 "肮脏、顽皮、淫秽或其他不良词语清单"中的任何词语的页面。
- 删除了带有Javascript字样的行。
- 删除了带有 "lorem ipsum "的页面。
- 删除了任何包含大括号"{"的页面,由于大括号"{"出现在许多编程语言中,而不是在自然文本中。
- 为了消除数据集的重复性,以3个句子作为一个span单元,对于数据集中至少出现了一次的这样的片段,仅保留一份,删除其余的。
- 采用 langdetect 语种识别,过滤掉非英文且概率不低于0.99 的页面。
作者收集了2019年4月以来的网络文本数据,并按上述规则清洗,生产了包括750GB的干净的英文语料。
输入输出格式
我们来看如何将各种下游NLP任务都统一转化成Text-to-Text格式。
在下游任务上fine-tune模型时,为了告诉模型当前要做何种任务,我们会给每条输入样本加一个与具体任务相关的前缀。
- 翻译前缀translate English to German:
- 分类前缀cola sentence:
- 摘要前缀summarize:
等等。注意这里每个任务前缀的选择可以认为是一种超参,即人为设计前缀样式。作者发现不同的前缀对模型的影响有限,因此没有做大量实验比较选择不同前缀的结果。
一些特殊数据的处理:
- 评分任务(1-5分)被重分类为21类,每隔0.2分为一类。
- 指代消解(生成式):待判定的词左右两侧都加上*符号,模型需要输出这个词代表什么。
- 指代消解(判断是否匹配):将训练集中标记为True的样本构造数据集,False的不考虑,因为False的具体指代何物我们也不清楚。
- WNLI数据集不参与训练和评估。
4. 实验
4.1 baseline
模型架构:
经典的Encoder-Decoder结构,模型配置与BERT-base相当,编解码器各由12个Transformer Block构成,隐层维度为768,12个注意力头,参数量约为220M(BERT-base的2倍)。Dropout比例为0.1。
训练方式:
预训练:
- AdaFactor优化器,解码时采用贪心解码。
- 在C4上预训练524k(2的19次方)步,序列最长为512,batch size为128,训练时模型总共处理了约34B个token,这比BERT和RoBERTa少了很多。
- 学习率策略采用均方根的倒数:
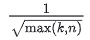 , 𝑘 为warmup步数,取值为10000, 𝑛 为当前步数。初始学习率为0.01。使用这种学习率策略的背景是,作者后面要对比不同的训练步数,这种方式可以在不确定训练步数的情况下自适应调整学习率。
, 𝑘 为warmup步数,取值为10000, 𝑛 为当前步数。初始学习率为0.01。使用这种学习率策略的背景是,作者后面要对比不同的训练步数,这种方式可以在不确定训练步数的情况下自适应调整学习率。
微调:
- 在所有任务上都是微调262k(2的18次方),使用常数学习率0.001,每5k步保存一次权重,并保存验证集最高的模型。
词典:
采用SentencePiece将文本切词为WordPiece词元,词典大小为32000。考虑到下游有翻译任务,作者按照英语:德语:法语:罗马尼亚语=10:1:1:1的比例构造语料库,重新训练SentencePiece模型。
非监督目标:
参考MLM,T5的解噪语言模型目标区别在于:
- mask的是连续的span,而非某一个token
- 多个连续被mask的片段,会被分配一个唯一的哨兵token,每个不同的哨兵token的id不一致
- 模型输出各个被mask的片段的哨兵token以及其原始文本,后面接一个终止符。

模型性能:
如下图所示,除了英语到法语的翻译任务,绝大部分任务在经过预训练后都能显著地涨点。

以下作者将从各个层面对比探讨更优的模型、数据和训练策略。
4.2 模型架构
不同模型的区别主要在于Transformer中自注意力中的mask设计,mask的设计策略决定了在计算自注意力时,哪些上下文信息会参与进来。下图展示了最常见的三类mask策略:
- 左侧:不加mask,左右两侧的上下文信息都参与注意力的计算,适用于BERT等双向的语言模型
- 中间:常规的斜对角 mask,仅前面的 token 会作为上下文信息参与注意力计算,适用于GPT等单向语言模型
- 右侧:部分不加mask,部分为斜对角的mask,适用于encoder-decoder等seq2seq的语言模型,Encoder中的输出序列及Decoder中前面的token会参与后面token的注意力计算

假设BERT-base的层数为 𝐿 ,参数量为 𝑃 ,FLOPs 为 𝑀
,作者设计一下不同的模型用于对比:
| 编码器层数 | 解码器层数 | 总参数量 | FLOPs | 备注 |
| L | L | P | M | |
| L | L | P | M | 编解码器参数共享 |
| L/2 | L/2 | P | M/2 | |
| 0 | L | P | M | 只有解码器 |
| 0 | L | P | M | 解码器为前缀,即包括输入和输出,输入序列无MASK |
训练时,除了 denoising 目标函数,还包含了常规的语言模型目标。对于Prefix LM,在句子中随机找一个切分点,切分点前的为输入序列,后面的为输出序列;对于只有Decoder的模型,从头开始预测。
对比结果:
- 采用Denosing 目标函数的 Encoder-Decoder 性能最好,Encoder与Decoder共享权重的模型也能取得很好的性能,因此可以考虑通过共享权重的方式减少模型参数量,但是仍然不降低模型精度;但是将模型层数减少一半会极大地损害模型性能。
- 相比于只有Decoder的模型,共享参数的Encoder-Decoder模型精度提高很多,说明引入Encoder-Decoder之间的注意力是有增益的。
- 采用Denoising目标函数比自回归LM目标函数的效果更好。

4.3 非监督学习目标
不同的目标函数:
- Seq2Seq:给定输入文本,生成输出文本
- BERT式:输入添加掩码的文本,输出被mask的文本
- Deshuffle:打乱输入文本片段后恢复顺序
- MASS式:输入添加掩码的文本,输出恢复后的原文
- 随机替换片段:随机mask掉连续的片段,恢复被mask的片段。
- 随机删除输入片段,输出被删除的片段
- 随机Mask 片段:随机mask掉连续的片段,然后逐个输出被mask的片段原文(即T5采用的方法)

对比结果:
- BERT式的MLM目标函数比Prefix LM的目标函数效果更好
- MLM的策略当中,随机替换片段的效果最好
- MLM的mask比例对模型的影响不是很大,最好的结果是采用15%的mask比例
- mask文本片段时,采用平均长度为3的片段时,相对性能最好



4.4 预训练数据集
对比不同的数据集:
- C4数据集
- Unfiltered C4数据集:未做过滤清洗的C4数据集(但是做了语种过滤)
- RealNews-like数据集:仅保留C4中新闻领域的内容
- WebText-like数据集:仅保留 Reddit的评分不低于3分的内容
- Wikipedia数据集:英文Wikipedia数据集
- Wikipedia + Toronto Books语料:英文Wikipedia数据集和TBC(电子书)数据集
对比结果:


4.5 训练策略
微调策略:
- 全部参数都微调
- 插入Adapter层:在FFN后面再加上全连接层变换,主要参数为全连接层采用不同的维度
- 逐层解冻:首先只更新最后一层的参数,然后更新倒数两层的参数,直到所有参数都被微调
结果:微调所有参数仍然是效果最好的。

多任务学习:
主要体现在训练数据集中包含不同类型任务的样本。
- 按照每个任务的样本比例混合采样
- 对样本比例加温度变换,重新构造混合样本
- 对每个任务采样相同数目的样本

组合多任务学习和微调:
- 非监督预训练+微调仍然是最优的策略
- 多任务预训练+微调也能取得不错的结果

4.6 更大模型、训练更久
- 模型放大2-4倍,训练步数增大1-2倍,性能有所提升,但无法明确两者的重要性
- 在默写任务上集成4个独立训练的模型也能显著增益

4.7 各方面集成
综上所述,作者发现,一个最优的预训练T5模型应该是这样的:
- 目标函数:Span-corruption,span的平均长度为3,corruption的概率为15%
- 更长的训练步数:采用C4数据集继续训练1M步(bs=2^11),总计约训练了1 万亿个token
- 模型大小:
- base版本:24层,隐层768维,12个注意力头,参数量为220M
- small版本:12层,隐层 512维,8个注意力头,参数量约为60M
- Large版本:48层,隐层1024维,16个注意力头,参数量约为770M
- 3B和11B版本:48层,隐层1024维,分别为32/128个注意力头,参数量达到了 2.8B和11B
- 多任务预训练:在非监督预训练时,混合有监督任务可以涨点。
- 微调:在每个任务上微调
- Beam Search:Beam size为4,长度惩罚为0.6

这篇关于大模型T5的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








