本文主要是介绍[论文阅读] 测试时间自适应TTA,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最初接触 CVPR2024 TEA: Test-time Energy Adaptation
[B站](1:35:00-1:53:00)https://www.bilibili.com/video/BV1wx4y1v7Jb/?spm_id_from=333.788&vd_source=145b0308ef7fee4449f12e1adb7b9de2
实现:
- 读取预训练好的模型参数
- 设计需要更新的模型参数,其他模块不进行梯度更新
- 设计辅助任务进行测试时间的模型更新
论文列表--待更新
- Contrastive Test-Time Adaptation(CVPR 2022)
- Improved Test-Time Adaptation for Domain Generalization(CVPR 2023)
- SoTTA: Robust Test-Time Adaptation on Noisy Data Streams(NeurIPS 2023)
- Feature Alignment and Uniformity for Test Time Adaptation(CVPR 2023)
- A Comprehensive Survey on Test-Time Adaptation under Distribution Shifts(arXiv 2023)
- TEA: Test-time Energy Adaptation(CVPR 2024)
Contrastive Test-Time Adaptation(CVPR 2022)
缩写:CoTTA
在测试时适应过程中将自监督对比学习与自我训练相结合。
PDF Code
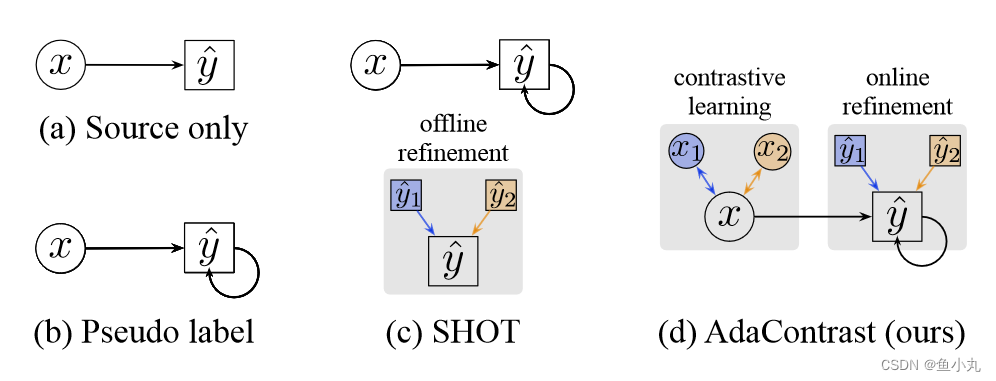
这个方法是利用对比学习的Moco为基本框架。主要流程如下图所示。
![对比测试时适应方法(AdaContrast)的框架:在适应开始时,模型和动量模型由源模型初始化。目标图像由一个弱增强和两个强增强转换。(a) 弱增强图像被编码为特征向量 w,用于根据与目标特征空间的余弦距离查找最近邻,该空间作为内存队列进行维护。对相关概率进行平均,然后进行 argmax 以获得用于自我训练和对比学习的精细伪标签 ˆ y。(b)将图像的两个强增强版本编码为动量对比度的查询和关键特征q,k[6,17],与自训练联合应用。不使用投影头;当前伪标签和历史伪标签用于排除同类负对。(c) 从弱增强图像中获得的伪标签 ˆ y 也用于监督强增强图像的预测,从而加强自训练中的弱-强一致性。多样性正则化也基于相同的预测。请注意,用于最近邻搜索和对比学习的队列是分开的,它们分别使用 w 和 k 进行更新(此处未说明)。](https://img-blog.csdnimg.cn/direct/8f617bb4346d4a908bb54764b36b79b7.png)
基本流程是:
对输入图片进行一次弱增强,两次强增强,分别输入到不同的编码器中。弱增强经过encoder得到的伪标签对强增强的输出进行监督。
弱图像增强获得的样本进入经过源模型参数初始化的encoder中获得概率分布,这个概率分布与内存队列中的概率分布计算距离,使用K个临近的概率分布的平均值作为当前样本的输出的概率分布,进行argmax变成用于自训练和对比学习的伪标签,然后当前样本的概率分布对内存队列进行更新。
两个强增强得到的输入进入Moco,一个是Encoder得到query,一个是momentum encoder得到key。momentum得到的key对key队列进行更新,利用伪标签的值mask相同类别的key,只是对不同类别进行对比学习(就是不会让正样本和正样本进行对比)。其余操作与Moco相同。
损失函数:weak aug输出作为伪标签进行监督的的CE Loss,一个CTR对比学习Loss,一个均匀分布Loss(防止错误的伪标签对模型造成不利影响,同时提高模型输出的多样性)
Improved Test-Time Adaptation for Domain Generalization(CVPR 2023)
PDF Code
目前TTA遇到的困难是:
- 辅助任务设计很困难,辅助任务设计不好,与原来损失如果不匹配,使用TTA性能会下降。目前大多设计一个看起来比较合理的辅助任务。
- 模型需要更新的参数设计也比较复杂,更新哪个模块设计比较困难。
主要是应用一致性损失。
![ITTA的训练过程。我们使用源域中的 x 作为特征提取器 fθ(·) 的输入来获得表示 z 及其增强版本 z′,其中应用了 [74] 中的增强技能。分类器 fφ(·) 和权重子网 fw(·) 用于计算主损失 Lmain 和可学习一致性损失 Lwcont。详情请参阅我们的文字。](https://img-blog.csdnimg.cn/direct/023b433a34e84e3bb5fd66e9229e7aef.png)
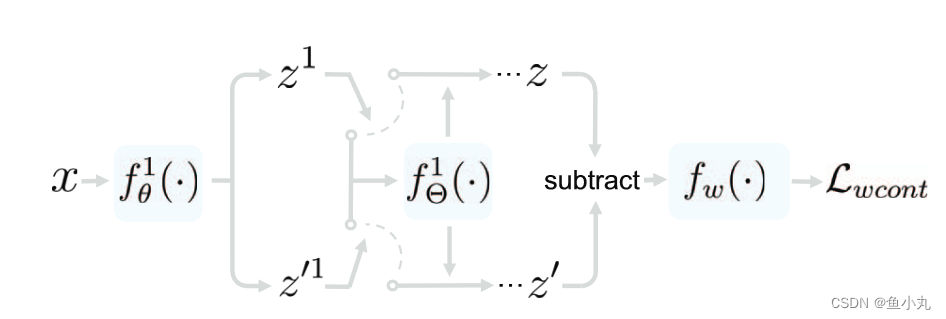
在每个block后面加入自适应模块。改动模块的激活层得到两个不同的特征,这两个特征的差经过fw之后要接近于0。其中胖一点的Θ是要更新的参数,瘦一点的θ是模型原来的参数这个是不在测试时间进行改变的。
SoTTA: Robust Test-Time Adaptation on Noisy Data Streams(NeurIPS 2023)
PDF Code
观察:如果测试集中有noise、对抗性样本等,TTA的性能会直线下降。
问题:现有的TTA方法都无可避免的适应了混杂在测试数据中的不好的样本,导致模型性能下降。
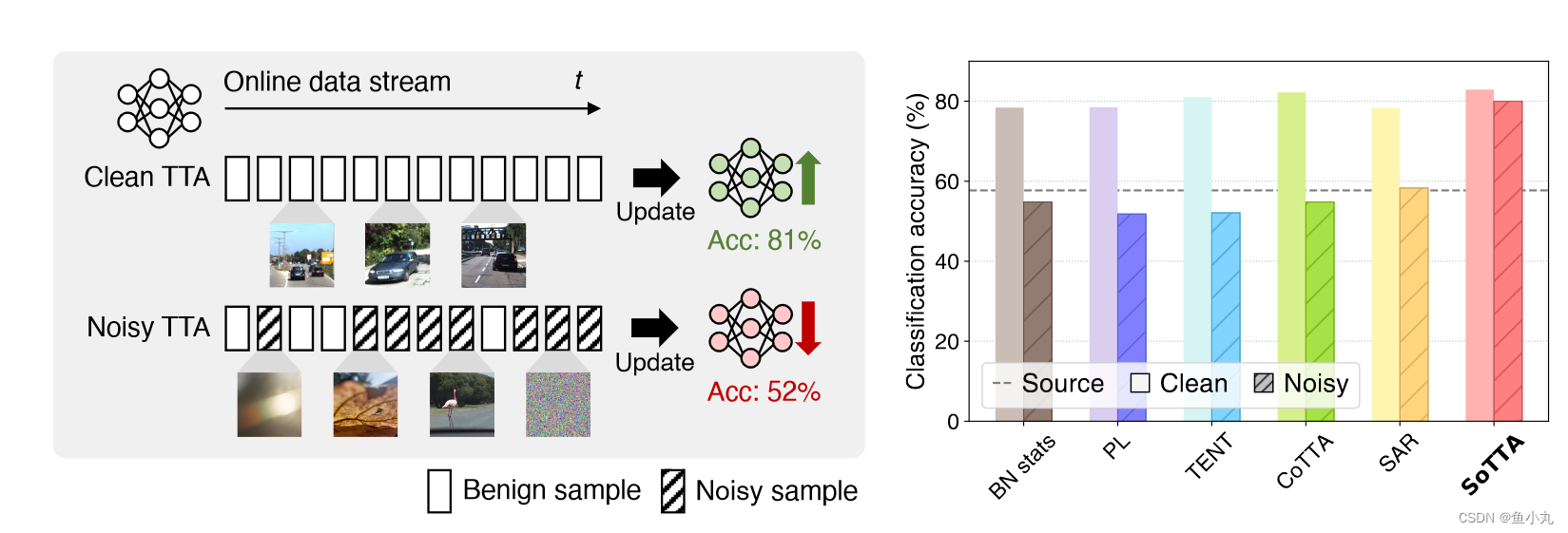
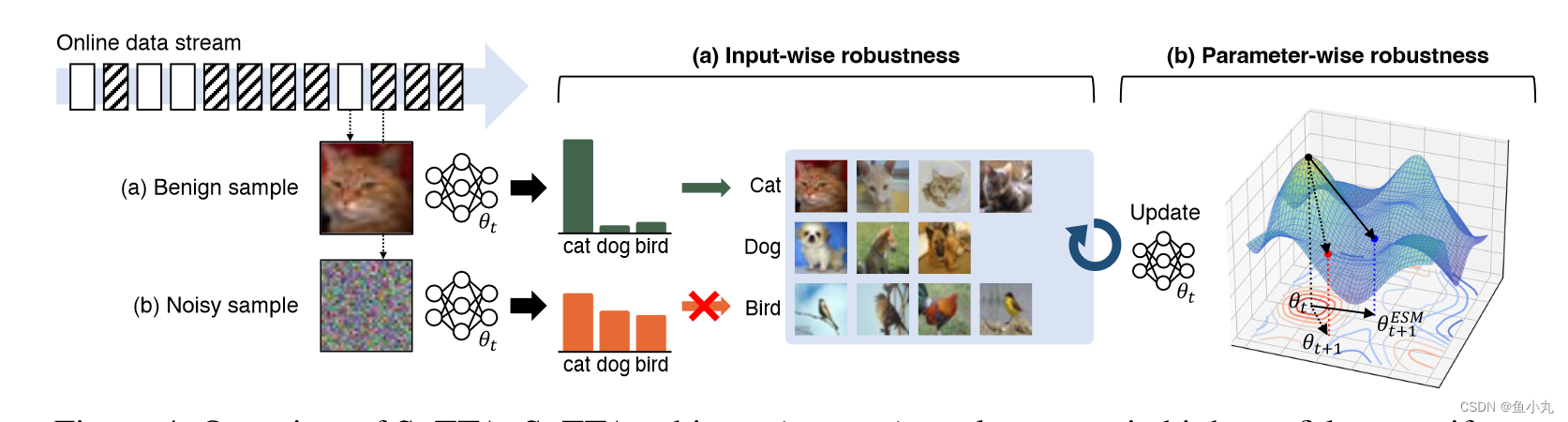
创新点:
- 高置信度均匀采样,选取良性样本进行memory更新。
- 熵锐度最小化,实现模型参数鲁棒性。
观察:噪声样本和良性样本的区别可以通过模型输出观察到。
memory更新:对数据进行筛选更新,保持memory中样本类别相对平衡有代表性,噪声低。
Loss函数:熵的一阶泰勒,使模型扰动前后保持不变。
Feature Alignment and Uniformity for Test Time Adaptation(CVPR 2023)
PDF Code
缩写:TSD
测试时间自蒸馏
首先将 TTA 作为功能修订问题来解决,因为源域和目标域之间存在域间隙。之后,按照两个测量对齐和均匀性来讨论测试时间特征修订。对于测试时间特征的均匀性,提出了一种测试时间自蒸馏策略,以保证当前批次和之前所有批次表示之间的均匀性一致性。对于测试时特征对齐,提出了一种记忆空间局部聚类策略,以对齐即将到来的批次的邻域样本之间的表示。为了解决常见的噪声标签问题,提出了熵和一致性滤波器来选择和删除可能的噪声标签。
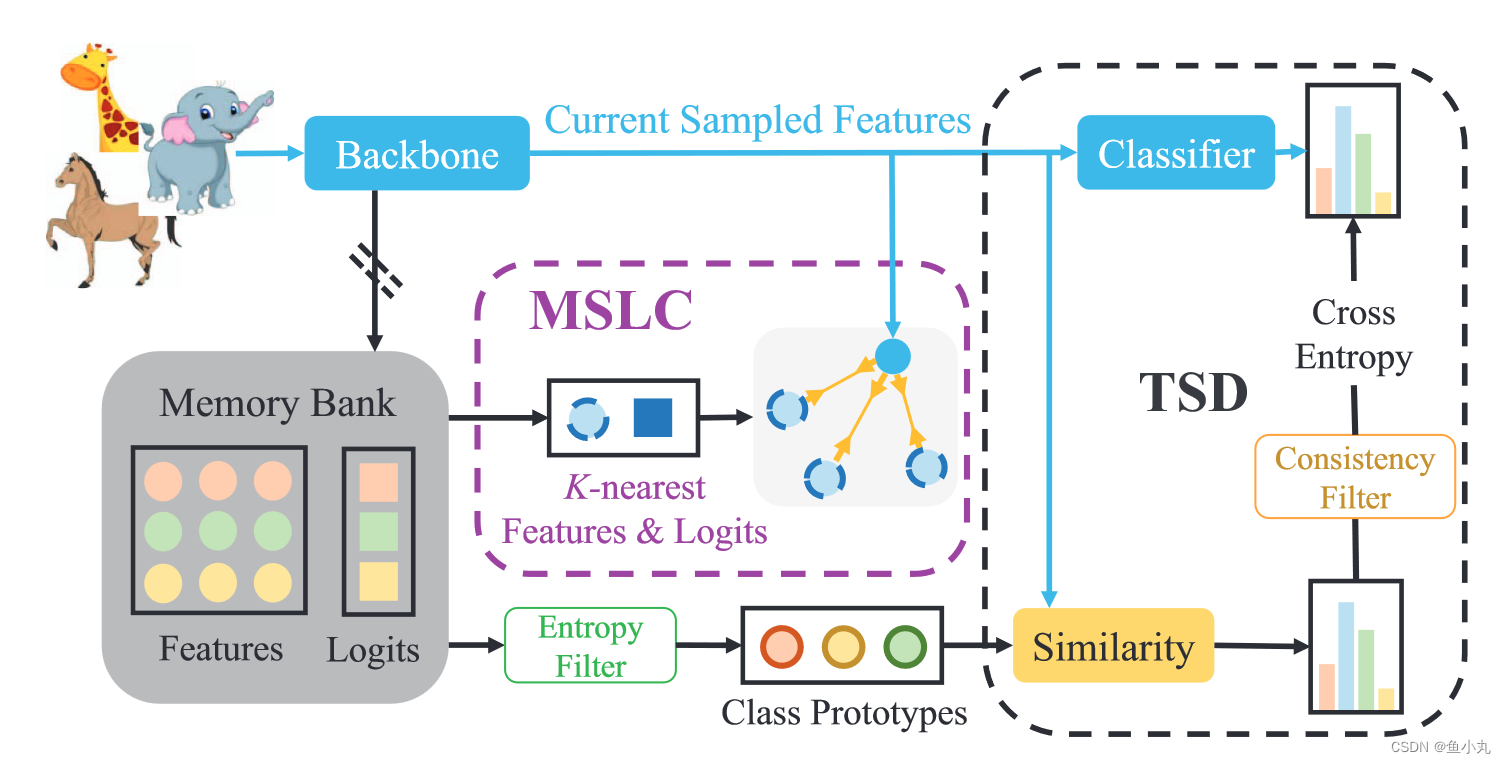
分类模型与原型模型输出的一致性。
我的理解,MSLC是对原型分类模型中的feature和Logits进行更新(更新原型向量,如果分类预测与原型预测一致,则让临近的原型向量与当前得到的特征更加接近,否则就远离,动量更新),TSD是计算分类模型和原型模型输出的一致性损失(为了防止原型模型输出的噪声先经过过滤器再计算CE Loss)。
A Comprehensive Survey on Test-Time Adaptation under Distribution Shifts(arXiv 2023)
PDF github综述(没看完)
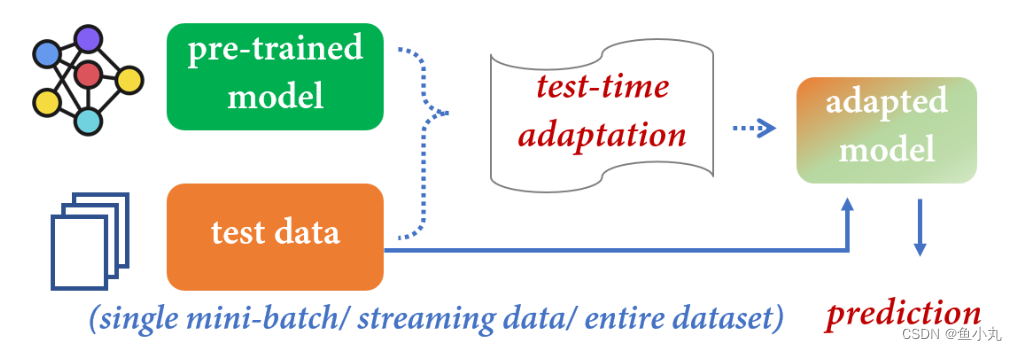
TTT:有Training data,可以改变模型训练的策略,重新训练一个新的模型。
TTA:只有预训练好的模型和测试数据。
这篇综述也说了一些相关的领域,比如自监督、半监督、领域泛化、领域适应、测试增强、迁移学习、持续学习等,对概念理解有帮助。


因为之后主要研究无源域自适应所以,只把无源域自适应部分进行整理。


TEA: Test-time Energy Adaptation(CVPR 2024)
PDF Code
缩写:TEA
观察:Test data的能量越低,测试的准确率越高。
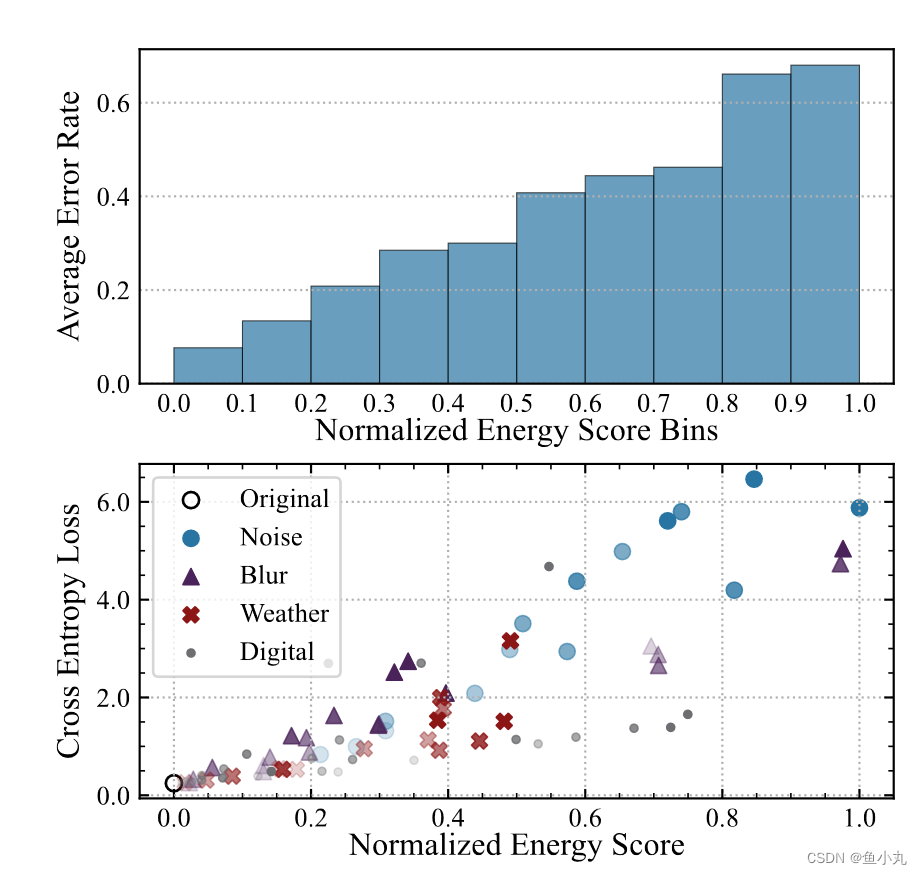
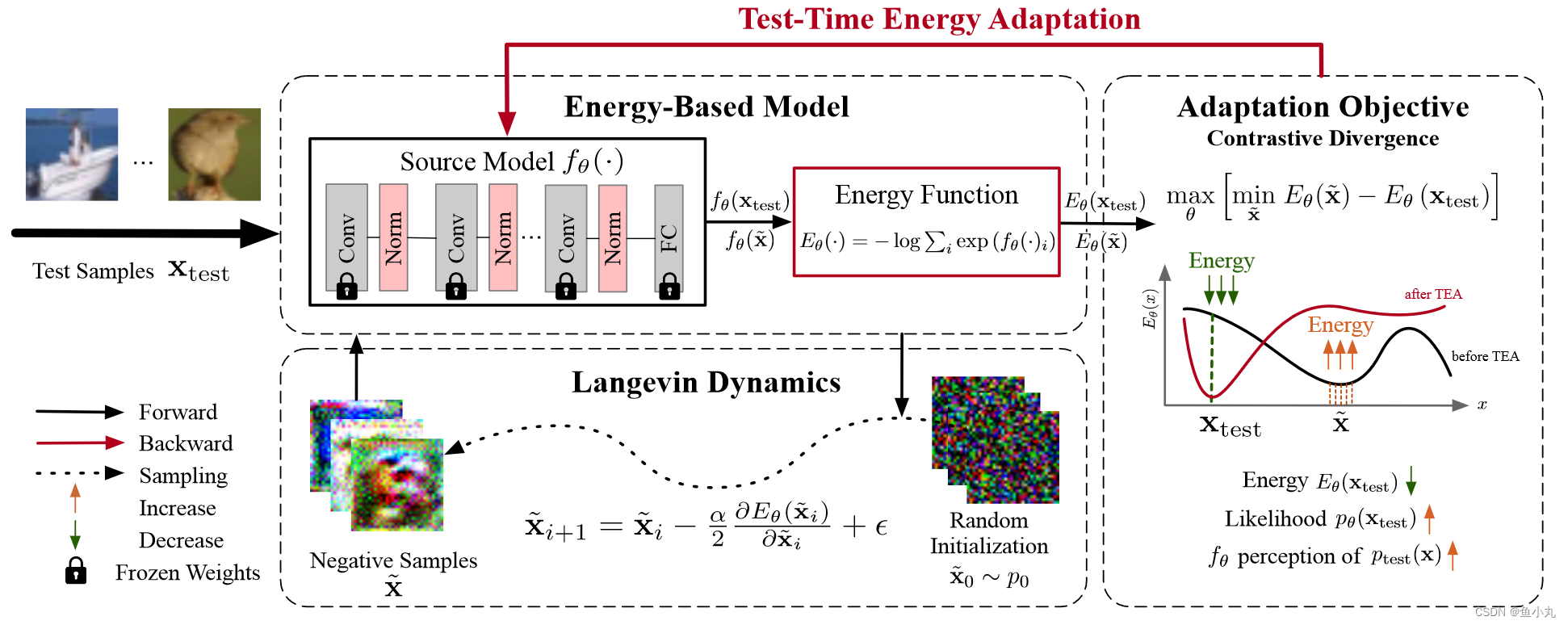
让模型自行感知,以降低测试样本的能量,提高模型的泛化能力。
- 把分类器做成一个能量模型。
- 从模型中采样能量低的伪样本,提高伪样本的能量,降低测试数据的能量。
看代码就是:从模型中采样能量低的伪样本,初始化得到一个输入,进入模型中得到梯度,根据梯度更新获得大致的局部最小值,作为伪样本,也就是模型中能量低的样本。
这篇关于[论文阅读] 测试时间自适应TTA的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







