本文主要是介绍论文辅助笔记:Tempo 之 model.py,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0 导入库
import math
from dataclasses import dataclass, asdictimport torch
import torch.nn as nnfrom src.modules.transformer import Block
from src.modules.prompt import Prompt
from src.modules.utils import (FlattenHead,PoolingHead,RevIN,
)1TEMPOConfig
1.1 构造函数
class TEMPOConfig:"""Configuration of a `TEMPO` model.Args:num_series: 时间序列的数量, N input_len: 输入时间序列的长度, Lpred_len: 预测时间序列的长度, Yblock_size: 块的最大长度(openai gpt2 固定)n_layer: Transformer 层的数量n_head: 多头注意力机制中的头数量n_embd: 嵌入维度的数量patch_size: 块的大小,用于将输入时间序列分割成多个小块patch_stride: 块的步幅,用于指定块之间的重叠程度revin: 是否使用 RevIN(归一化和逆变换)affine: 在 RevIN 中是否使用仿射变换embd_pdrop:嵌入层的 dropout 率resid_pdrop: 残差连接的 dropout 率attn_pdrop: 注意力层的 dropout 率head_type: 输出层的类型,可以是 FlattenHead 或 PoolingHeadhead_pdtop: 输出层的 dropout 率individual: 是否为每个组件使用独立的输出层lora: 是否使用 LoRA(低秩近似)lora_config: LoRA 的配置model_type: 模型类型,默认为 gpt2interpret: 是否输出组件以便解释"""num_series: intinput_len: intpred_len: intpatch_size: intpatch_stride: intblock_size: int = Nonen_layer: int = Nonen_head: int = Nonen_embd: int = Nonerevin: bool = Trueaffine: bool = Trueembd_pdrop: float = 0.1resid_pdrop: float = 0.1attn_pdrop: float = 0.1head_type: str = "flatten"head_pdtop: float = 0.1individual: bool = Falselora: bool = Falselora_config: dict = Noneprompt_config: dict = None#Prompt 模块的配置model_type: str = "gpt2"interpret: bool = False1.2 todict
TEMPOConfig 类实例转换为一个字典
def todict(self):return asdict(self)'''
asdict 是 Python 的 dataclasses 模块提供的一个函数,用于将数据类实例转换为字典。这个方法将当前实例的所有属性转换为字典键值对,并返回这个字典。
'''
1.3 __contains__
重载了 Python 的 __contains__ 魔术方法,使得 TEMPOConfig 实例可以像字典一样使用 in 操作符来检查属性是否存在。
def __contains__(self, key):return key in self.todict()
1.4 __getitem__
重载了 __getitem__ 魔术方法,使得 TEMPOConfig 实例可以像字典一样通过键来获取属性值
def __getitem__(self, key):return getattr(self, key)
1.5__setitem__
重载了 __setitem__ 魔术方法,使得 TEMPOConfig 实例可以像字典一样通过键来设置属性值
def __setitem__(self, key, value):setattr(self, key, value)
1.6 update
通过一个字典 config 更新 TEMPOConfig 实例的属性
def update(self, config: dict):for k, v in config.items():setattr(self, k, v)
2 TEMPO
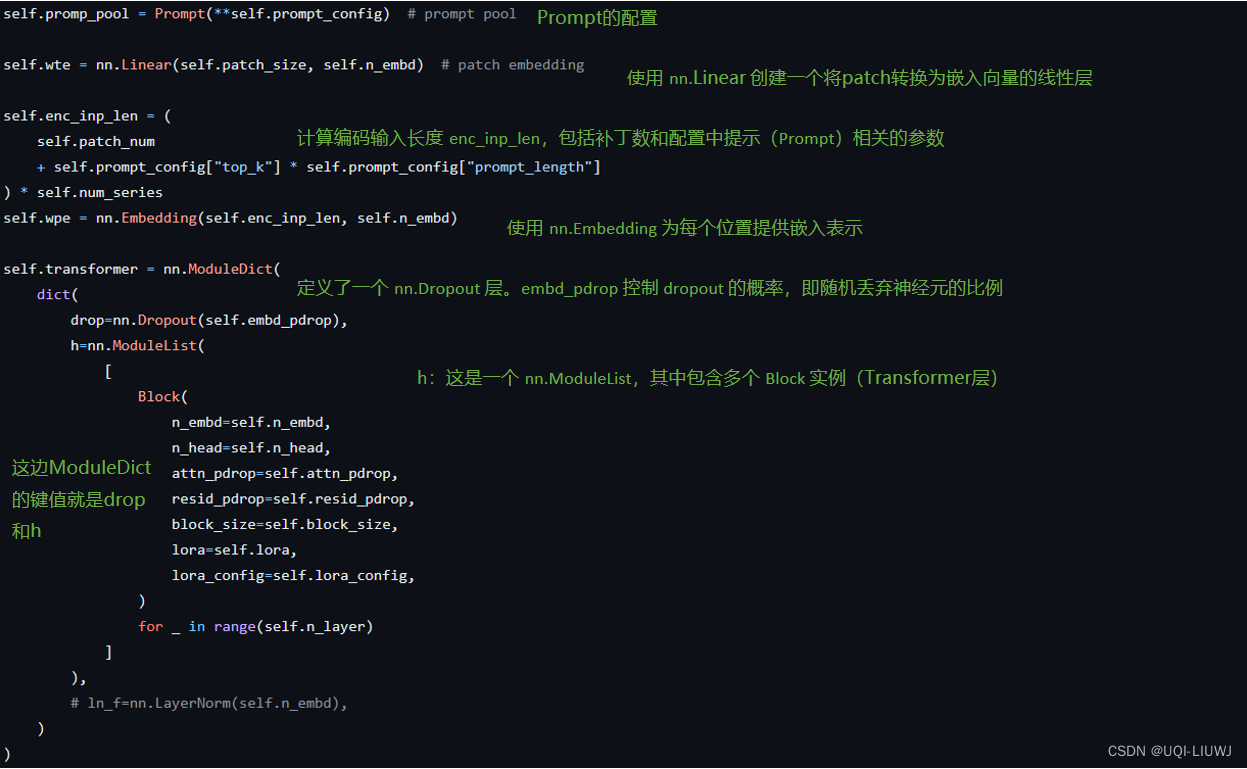
class TEMPO(nn.Module):"""Notation:B: 批次大小N: 时间序列的数量E: 嵌入维度P: 块的数量PS: patch的大小L: 输入时间序列的长度Y: 预测时间序列的长度"""models = ("gpt2",)#支持的模型类型列表head_types = ("flatten", "pooling")#支持的输出层类型params = {"gpt2": dict(block_size=1024, n_head=12, n_embd=768),}'''模型的参数,例如 "gpt2" 模型的块大小、注意力头数和嵌入维度等'''2.1 __init__


这篇关于论文辅助笔记:Tempo 之 model.py的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





