本文主要是介绍深度学习500问——Chapter08:目标检测(6),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
8.3.7 RetinaNet
8.3.7 RetinaNet
研究背景
- Two-Stage 检测器(如Faster R-CNN、FPN)效果好,但速度相对慢。
- One-Stage 检测器(如YOLO、SSD)速度快,但效果一般。

作者对one-stage检测器准确率不高的问题进行探究,发现主要问题在于正负类别不平衡(简单-难分类别不均衡)。
We discover that the extreme foreground-background class imbalance encountered during training of dense detectors is the central cause
作者建议通过重新设计标准的交叉熵损失(cross entropy loss)来解决这种类别不平衡(class inbalance)问题,即提出Focal Loss。
We propose to address this class imbalance by reshaping the standard cross entropy loss such that it down-weights the loss assigned to well-classified examples. Our novel Focal Loss focuses training on a sparse set of hard examples and prevents the vast number of easy negatives from overwhelming the detector during training.
结合Focal Loss的one-stage检测器称为RetinaNet ,该检测器在COCO上mAP可以和特征金字塔网络(feature pyramid network,FPN)或者Mask R-CNN接近。
问:什么是类别不均衡(class inbanlance)?
答:负样本的数量大于正样本的数量,比如包含物体的区域(正样本)很少,而不包含物体的区域(负样本)很多。比如检测算法在早期会生成一大波的bbox。而一幅常规的图片中,顶多就那么几个object。这意味着,绝大多数的bbox属于background。
问:样本的类别不均衡会带来什么问题?
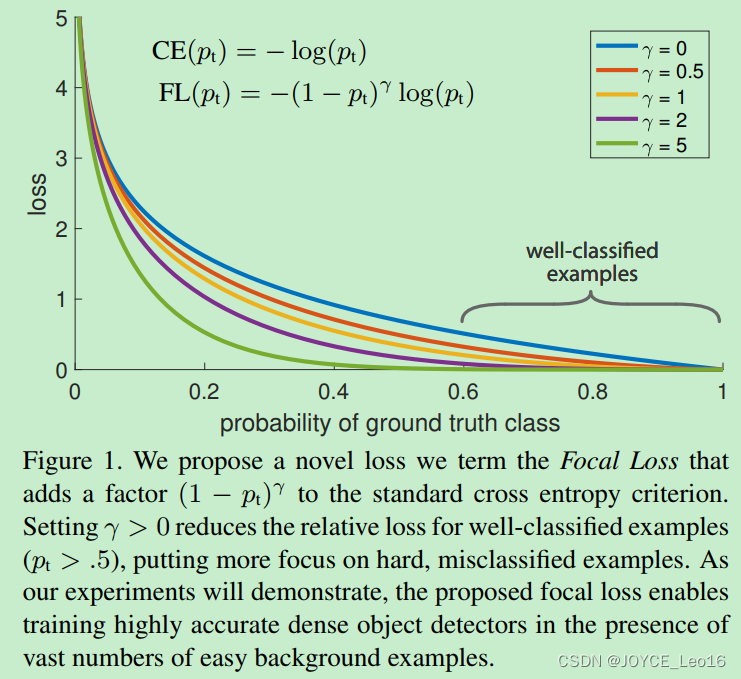
答:由于大多数都是简单易分的负样本(属于背景的样本),使得训练过程不能充分学习到属于那些有类别样本的信息;其次简单易分的负样本太多,可能掩盖了其他有类别样本的作用(这些简单易分的负样本仍产生一定幅度的loss,见下图蓝色曲线,数量多会对loss起主要贡献作用,因此就主导了梯度的更新方向,掩盖了重要的信息)。
This imbalance causes two problems: (1) training is inefficient as most locations are easy negatives that contribute no useful learning signal; (2) en masse, the easy negatives can overwhelm training and lead to degenerate models.
简单来说,因为bbox数量爆炸。正是因为bbox中属于background的bbox太多了,所以如果分类器无脑地把所有bbox统一归类为background,accuracy也可以刷的很高。于是乎,分类器的训练就失败了。分类器训练失败,检测精度自然就降低了。
问:为什么在two-stage检测器中,没有出现类别不平衡(class inbalance)问题?
答:因为通过RPN阶段可以减少候选目标区域,而在分类阶段,可以固定前景和背景比值(foreground-to-background ratio)为1:3,或者使用OHEM(online hard example mining)使得前景和背景的数量达到均衡。
RetinaNet 有哪些创新点
概述:
- New Loss:提出Focal Loss函数解决class inbalance
- New detector:RetinaNet = ResNet + FPN + Two sub-networks + Focal Loss
Focal Loss更加聚焦在困难样本(hard examples)上的训练。
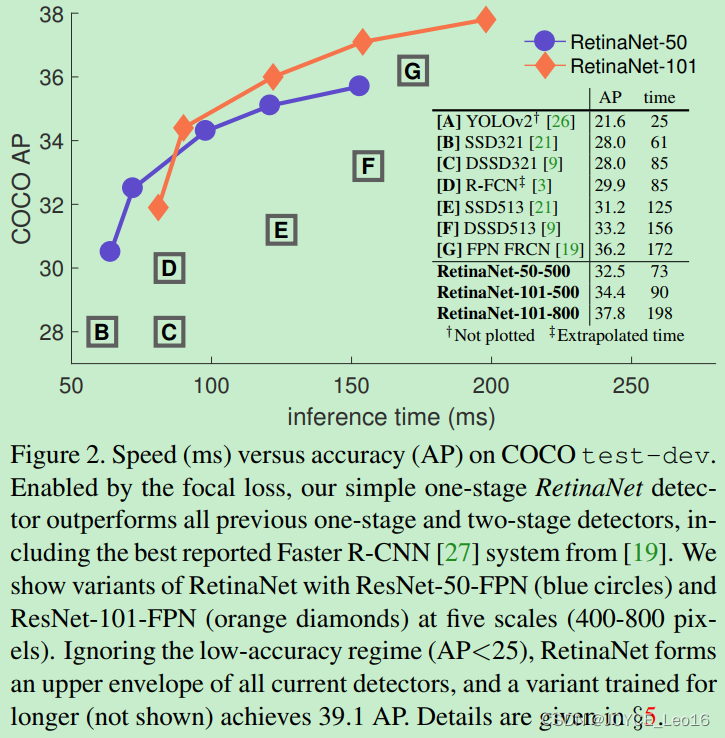
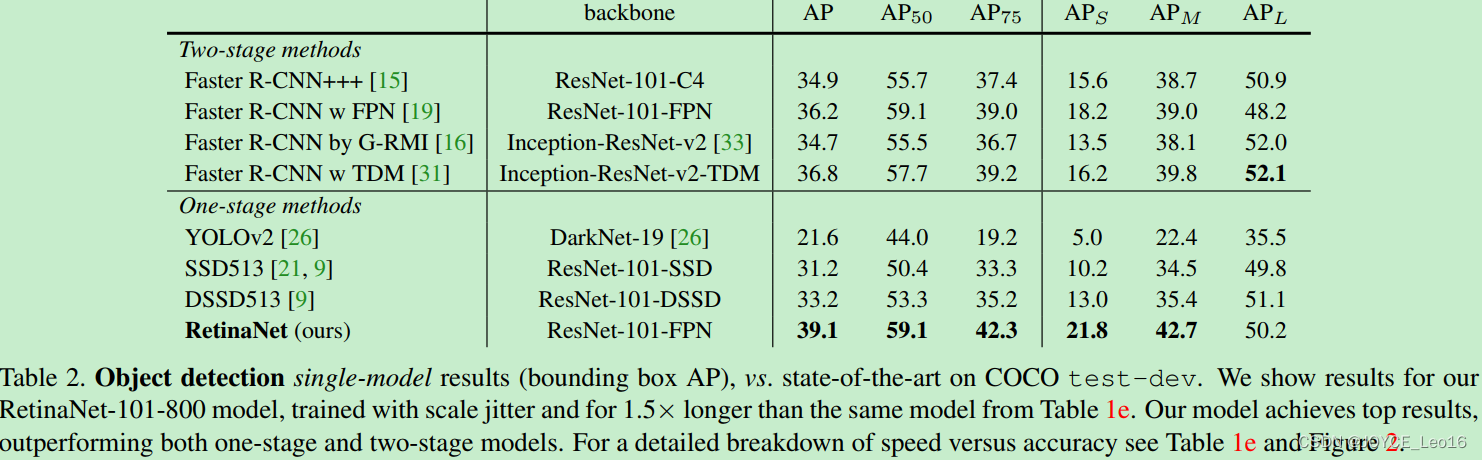
将Focal Loss与ResNet-101-FPN backbone结合提出RetinaNet(one-stage检测器),RetinaNet在COCO test-dev上达到39.1mAP,速度为5FPS。
RetinaNet检测器与当时最佳的其他检测器进行比较,无论是速度上还是准确率上都是最佳:
详解:
作者提出一种新的损失函数,思路是希望那些hard examples对损失的贡献变大,使网络更倾向于从这些样本上学习。
作者以二分类为例进行说明:
- 交叉熵函数CE
首先我们常使用的交叉熵损失函数:

上式中,y=+1或者y=-1。是y=+1的概率。作者定义pt为:

![]()
注:对交叉熵函数不了解的,可以参考:https://blog.csdn.net/chaipp0607/article/details/73392175
- 均衡交叉熵函数
要对类别不均衡问题对loss的贡献进行一个控制,即加上一个控制权重即可,最初作者的想法即如下这样,对于属于少数类别的样本,增大即可。
![]()
但这样有一个问题,它仅仅解决了正负样本之间的平衡问题,并没有区分易分/难分样本,按作者的话说:
While α balances the importance of positive/negative examples, it does not differentiate between easy/hard examples. Instead, we propose to reshape the loss function to down-weight easy examples and thus focus training on hard negatives.
问:为什么公式(3)只解决正负样本不均衡问题?
答:增加了一个系数,跟pt的定义类似,当label=1的时候,
=a;当label=-1的时候,
=1-a,a的范围也是0到1。因此,可以通过设定a的值(一般而言加入1这个类的样本数比-1这个类的样本数多很多,那么a会取0到0.5来增加-1这个类的样本的权重)来控制正负样本对总的loss的共享权重。
- Focal Loss
作者一开始给交叉熵损失函数添加modulating factor:
显然,样本越易分,pt就越大(pt→1),modulating factor趋近于0,则贡献的loss就越小,同样地,样本越难分,其pt就越小,modulating factor接近于1,则贡献的loss不受影响。
问:为什么pt越大,FL值越小?
答:根据公式(4)可知,FL与log(pt)中的pt成反比,与1-pt成正比,因此FL与pt的关系成反比。者是交叉熵的基本性质。当pt很大时(接近于1),FL值很小;而当pt很小时(接近于0),FL值会很大。
注:这里有个超参数-focusing parameter 。
放大了modulating factor的作用。
举原文中的一个例子,当pt=0.9时,带有modulating factor的focal loss是CE loss的100分之一,即进一步减小了正确分类的损失。
For instance, with
= 2, an example classified with pt = 0.9 would have 100× lower loss compared with CE and with pt ≈ 0.968 it would have 1000× lower loss. This in turn increases the importance of correcting misclassified examples (whose loss is scaled down by at most 4× for pt ≤ .5 and
在实际中,作者采用如下公式,即综合了公式(3)和公式(4)的形状,这样既能调整正负样本的权重,又能控制难易分类样本的权重:
![]()
这里的两个参数和
来控制,在实验中a的选择范围也很广,一般而言,当
增加的时,a需要减小一点,本文作者采用
,
效果最好。
- RetinaNet Detector
RetinaNet是由backbone网络和两个特殊任务的子网络(subnet)组成(属于one-stage检测器)。Backbone用来计算feature map;第一个子网络用来object classification,第二个子网络用来bounding box regression。
- Feature Pyramid Network Backbone

Anchor
Classification Subnet
Box Regression Subnet
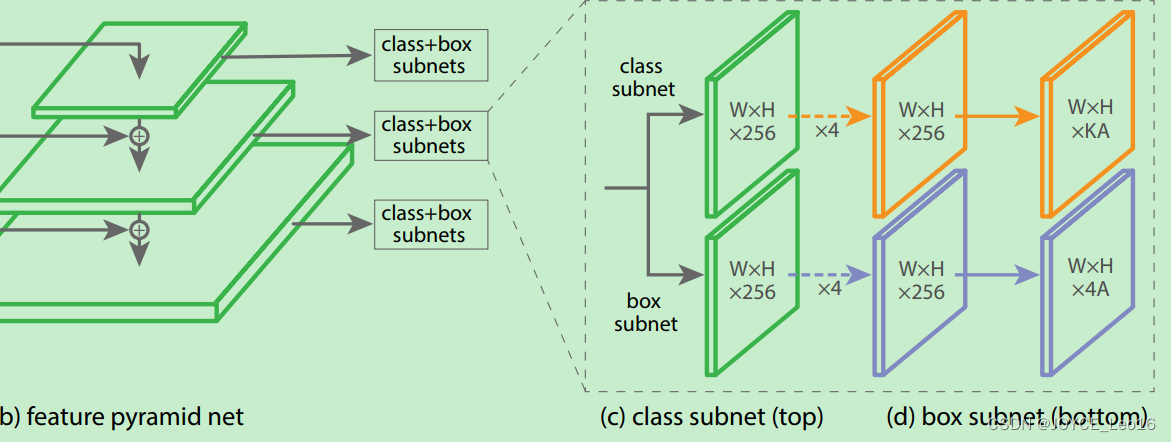
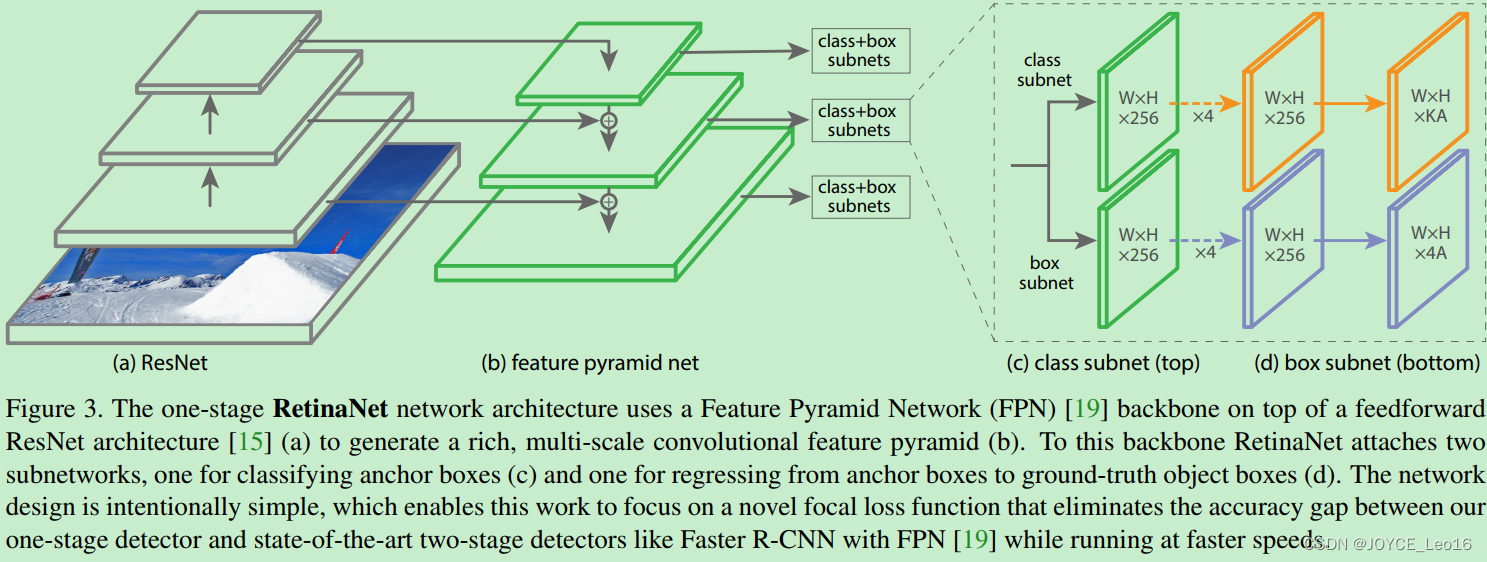
RetinaNet结构注意内容:
- 训练时FPN每一级的所有example都被用于计算Focal Loss,loss值加到一起用来训练;
- 测试时FPN每一级只选取score最大的1000个example来做nms;
- 整个结构不同层的head部分(上图中的c和d部分)共享参数,但分类和回归之间的参数不共享;
- 分类分支的最后一级卷积的bias初始化成前面提到的
;
作者:张磊_0503 链接:Focal Loss for Dense Object Detection解读 - 简书 來源:简书 简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
实验结果
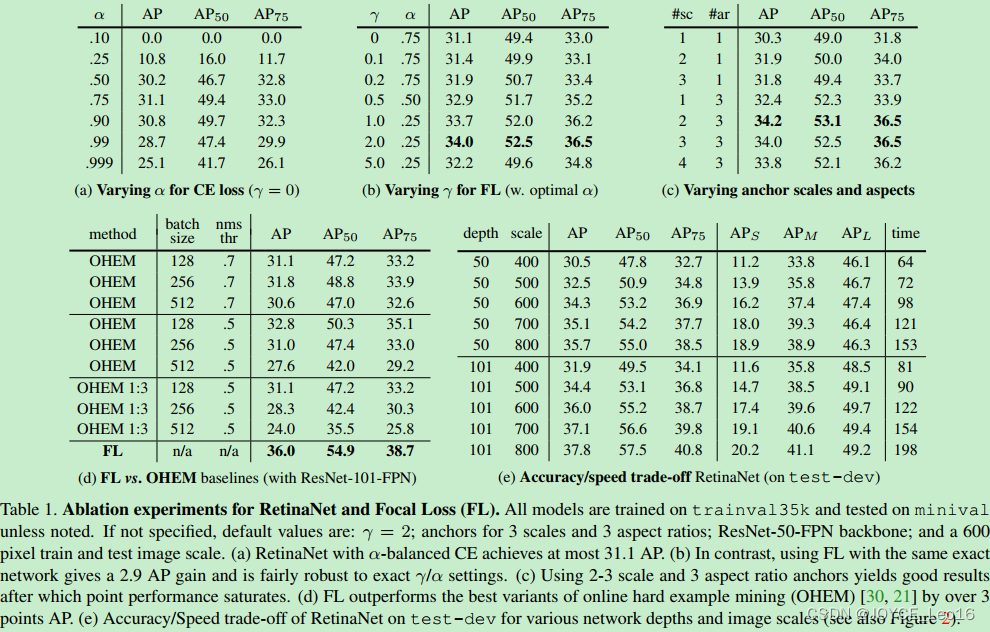
Tabel1 是关于 RetinaNet和Focal Loss的一些实验结果。
(a)是在交叉熵的基础上加上参数a,a=0.5就表示传统的交叉熵,可以看出当a=0.75的时候效果最好,AP值提升了0.9。
(b)是对比不同的参数和
的实验结果,可以看出是随着
的增加,AP提升比较明显。
(d)通过和OHEM的对比可以看出最好的Focal Loss比最好的OHEM提高了3.2AP。这里的OHME 1:3表示在通过OHEM得到的minibatch上强制positive和negative样本的比例为1:3,通过对比可以看出这种强制的操作并没有提升AP。
(e)加入了运算时间的对比,可以和前面的Figure2结合起来看,速度方面也有优势!注意这里RetinaNet-101-800的AP是37.8,当把训练时间扩大1.5倍同时采用scale jitter,AP可以提高到39.1.这就是全文和 table2中的最高的39.1AP的由来。
这篇关于深度学习500问——Chapter08:目标检测(6)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






