本文主要是介绍如何将任何 LLM 转变为嵌入模型?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文地址:How to turn any LLM into an embedding model
2024 年 4 月 22 日
嵌入模型在大型语言模型(LLM)的应用中发挥着核心作用,能够出色地处理文本相似度测量、信息检索和聚类等任务。然而,大多数嵌入模型所依赖的转换器架构与生成任务中所使用的架构并不相同。这导致了一个挑战:要将生成模型的大量工作成果转移到嵌入模型的改进上变得困难,需要付出额外的努力。
近期,Mila和服务管理自动化平台ServiceNow的研究人员提出了一种新的方法,名为LLM2Vec。这是一种简单且无监督的方法,能够将任何仅解码器的大型语言模型转化为高效的文本编码器。实验数据证明,LLM2Vec模型在嵌入任务上的性能达到了业内顶尖水平。
LLM2Vec不仅直观易懂,而且效率极高,为企业快速且低成本地创建专属的嵌入模型开辟了新的途径。
目前,嵌入模型主要使用的是预训练的双向编码器或编码器-解码器架构,如BERT和T5。相比之下,像GPT和Llama这样的解码器模型,它们的设计初衷并非用于生成令牌,而是将文本的语义内容编码成数值向量。
近期,研究人员开始探索使用仅解码器的大型语言模型进行文本嵌入。然而,由于解码器模型的单向注意力机制,它们在处理嵌入任务时受到一定限制。这种单向机制虽然对于生成任务非常有用,但在学习丰富的嵌入方面却稍显不足。
“例如,在检索任务中,我们需要一个强大的、遵循指令的文本编码器。这促使我们探索如何有效利用仅解码器的大型语言模型来表示文本。”麦吉尔大学和Mila的博士生、LLM2Vec论文的主要作者Parishad BehnamGhader在接受TechTalks采访时说。
仅解码器的大型语言模型之所以适合嵌入任务,有几个原因。首先,它们的训练方式使它们能够从所有输入令牌中学习,这与编码器模型在训练过程中部分屏蔽输入的方式不同。其次,解码器大型语言模型的研究非常活跃,并且拥有丰富的模型、技术和工具生态系统可供选择。最后,经过微调以遵循指令和人类偏好的大型语言模型,非常适合作为通用文本嵌入模型的基础,这些模型可以在多个任务中进行泛化。
LLM2Vec方法简单且无需监督,能够轻松地将任何仅解码器的大型语言模型转化为嵌入模型。
“当我们开始这个项目时,虽然有几篇论文探讨了使用仅解码器的大型语言模型来表示文本,但它们主要关注的是有监督的微调。”BehnamGhader解释说,“相比之下,我们的目标是开发一种通用的方法,它简单易行,适用于任何仅解码器的大型语言模型,而且不一定需要带标签的训练数据。因此,我们重点研究的是使用无监督和有监督的公开可用数据进行参数高效的微调。”
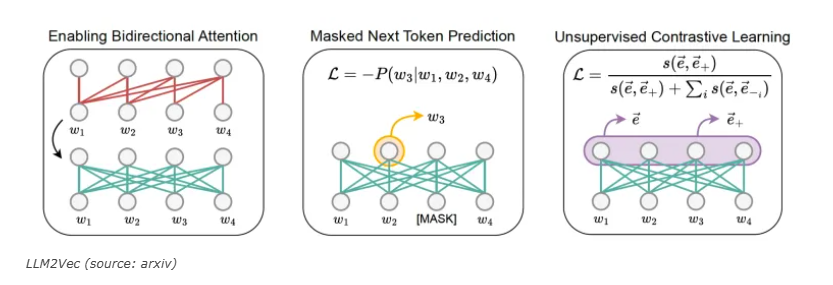
LLM2Vec的实施过程包括三个简单的步骤。首先,对模型进行修改,使其能够启用双向注意力。这样,每个令牌就能够关注到所有其他令牌,而不仅仅是像仅解码器的大型语言模型那样只查看之前的令牌。
接下来,模型在掩码下一个令牌预测(MNTP)任务上进行训练。MNTP将下一个令牌预测与掩码语言建模相结合,从而提高了模型的嵌入能力。
最后,模型在SimCSE上进行微调。SimCSE是一种用于句子嵌入的无监督对比学习技术。在这一步中,训练输入序列被复制,每个序列由于模型的丢弃操作而具有不同的掩码节点,导致同一序列的两个不同表示。对比学习的目标是迫使模型最大化相同输入序列的不同版本之间的嵌入相似性,并最小化与批次中其他序列表示之间的相似性。这一步骤可以应用于任何序列集合,从而大大减少了收集训练数据的工作量。
“LLM2Vec是一种通用方法,适用于任何仅解码器的大型语言模型。”BehnamGhader表示,“鉴于仅解码器的大型语言模型在我们领域的广泛应用,我们认为能够将它们转化为编码器非常重要,这为从头开始训练编码器提供了一种计算效率高的替代方案。”
许多大型语言模型应用都采用了检索增强生成(RAG)技术,这种技术需要嵌入段落和文档。通过使用LLM2Vec,相同的仅解码器大型语言模型可以同时作为嵌入和生成任务的核心。这大大降低了基础设施需求,并确保了嵌入和生成模型之间的一致性。
“我们认为,像检索这样的文本嵌入任务,可以从仅解码器大型语言模型的能力中获益良多,比如它们遵循指令的特性。”Parishad BehnamGhader解释说。
LLM2Vec的实际应用
研究人员将LLM2Vec应用在了三个仅解码器的大型语言模型上,这些模型的参数从13亿到70亿不等,并在单词和序列级别的任务上评估了生成的模型。
他们使用来自英语维基百科的数据执行了MNTP和无监督对比学习步骤,因为这些数据包含在模型预训练时所用的语料库中。这确保了这两个适应步骤不会教授模型除了如何关注未来令牌以及如何构建序列表示之外的任何新知识。
在降低训练成本方面,他们采用了低秩适应(LoRA)技术。有趣的是,使用LLM2Vec微调一个拥有70亿参数的模型,整个过程在80GB的A100 GPU上完成仅需不到4小时,这意味着成本低于10美元。而且,由于LLM2Vec中使用的训练数据来自训练解码器模型时所用的语料库,因此整个过程既快速又高效。
实验结果表明,LLM2Vec模型特别适用于序列级别的任务。在大量文本嵌入基准(MTEB)上,经过LLM2Vec转换的模型为无监督模型设立了新的最高水平。
考虑到大多数仅编码器的模型大小只是仅解码器的大型语言模型的一小部分,研究人员还在小型模型上测试了LLM2Vec。
“可以肯定的是,你打算使用LLM2Vec转换的仅解码器模型的大小,会对其性能产生一定影响。”BehnamGhader指出,“为了证明LLM2Vec不仅适用于大型模型,我们还将其应用在了相对较小规模的仅解码器模型上。”
他们对具有13亿参数的Sheared-LLaMA模型进行了实验,结果表明LLM2Vec在小规模上也是有效的。研究人员已经开源了LLM2Vec的代码,并发布了他们为实验训练的模型。
“LLM2Vec是朝着更好地利用这些模型进行文本嵌入任务迈出的第一步。”BehnamGhader表示,“我们特别期待将我们的方法应用于资源匮乏的环境,并使用它为那些我们没有足够训练数据从头开始训练模型的语言创建编码器模型。”
这篇关于如何将任何 LLM 转变为嵌入模型?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







