本文主要是介绍FIFO Generate IP核使用——Data Counts页详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在Vivado IDE中,当看到一个用于设置数据计数选项的选项卡时,需要注意的是,尽管某些选项值可能因为当前的配置而显示为灰色(即不可选或已禁用),但IDE中显示的有效范围值实际上是你可以选择的真实值。即使某些值在视觉上被灰化,它们仍然是可用的,只要你的FIFO配置支持这些值。然而,通常灰化的值是因为它们在当前FIFO的特定配置下不适用或不推荐。
1 选择Native 接口采用Common时钟Standard模式时(Built-in除外)
此时,只需要配置Data Count的宽度。
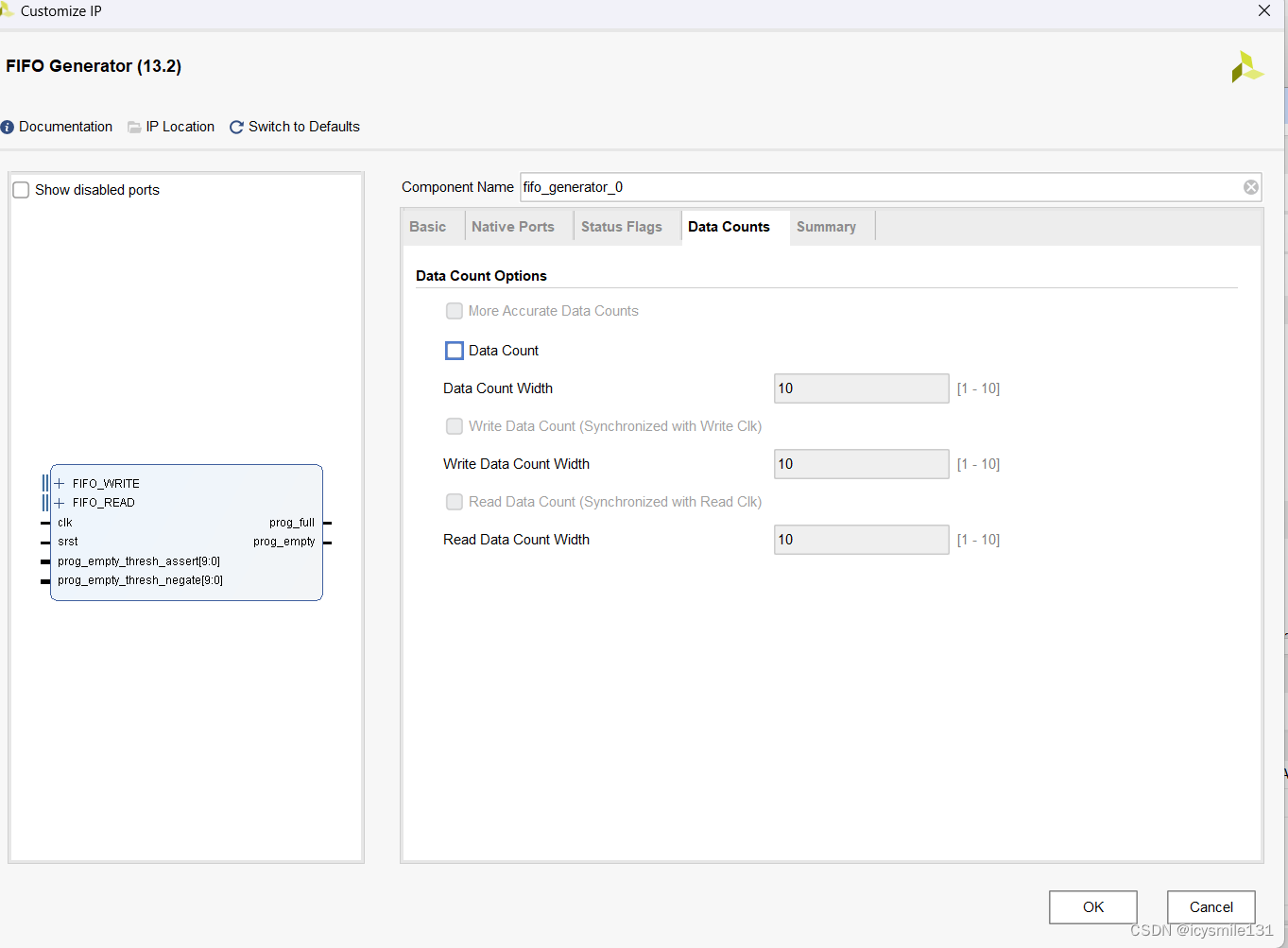
数据计数的目的是输出用于显示FIFO中当前存储的数据字数量。其宽度可以是指定数据计数总线的宽度,最大宽度为log2(depth),其中depth是FIFO的深度(即最大可以存储的数据字数量)。如果指定的宽度小于最大允许宽度,那么总线的较低位将被截去。
假设FIFO的深度为8(即可以存储8个数据字),可以指定一个2位的数据计数总线,这2位将只能提供四种状态:00(FIFO为空)、01(FIFO包含1到2个数据字)、10(FIFO包含3到4个数据字)、11(FIFO包含5到8个数据字)。
注意:
如果在clk的上升沿发生读或写操作,数据计数端口(data_count)将在相同的clk上升沿更新。这意味着在每个时钟周期结束时检查data_count的值,以确定FIFO的当前状态。
2 选择Native 接口采用Independent时钟Standard模式时(Built-in除外)
此时,需要配置Write Data Width 和Read Data Count。
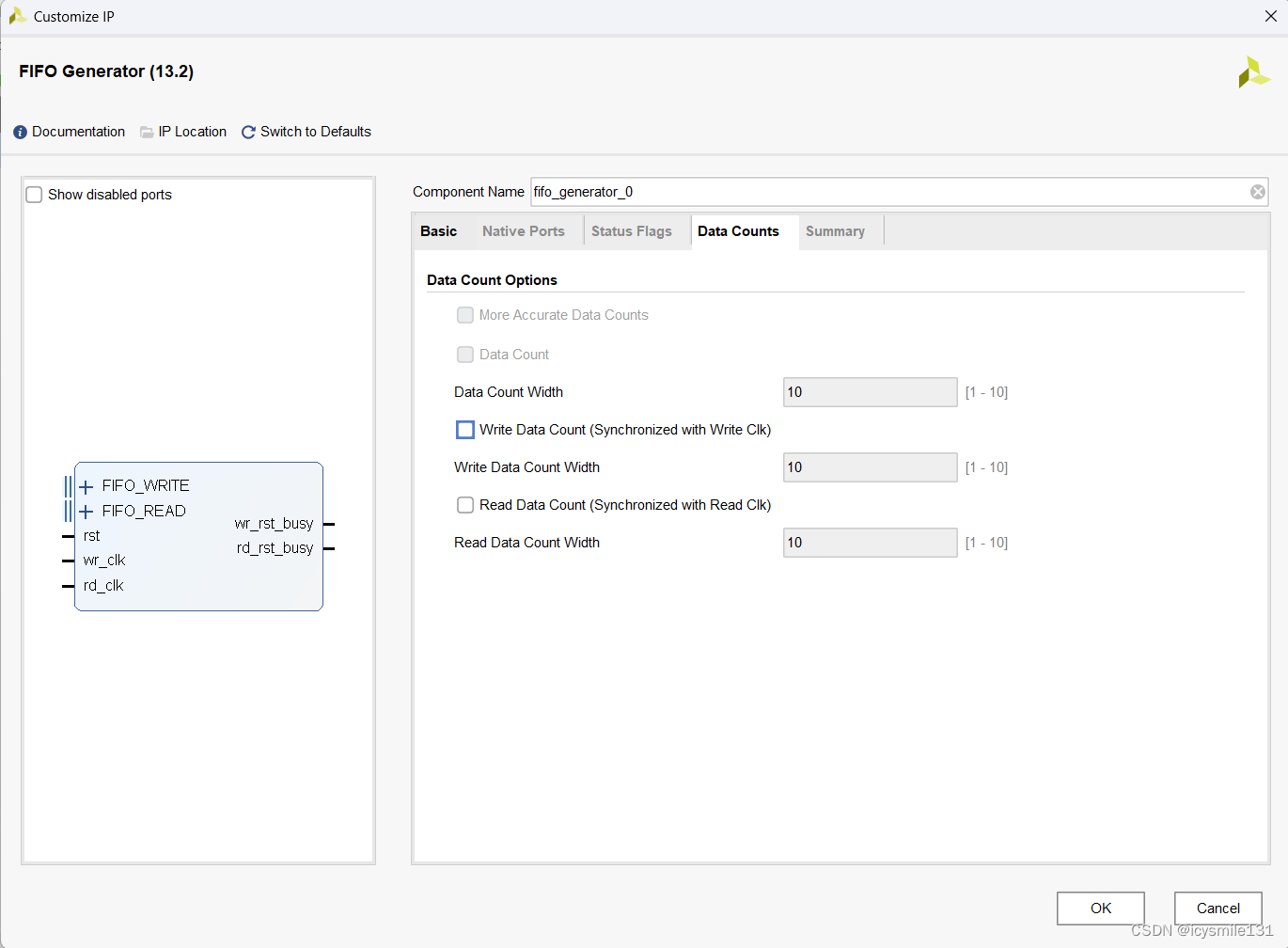
2.1 读数据计数(Read Data Count)
rd_data_count报告FIFO中可用于读取的数据字数量。它永远不会报告比实际可用的数据字更多的数量(尽管它可能会暂时报告更少的数量),以确保用户设计不会因读取过多数据而导致FIFO下溢。
宽度:可以指定读数据计数总线的宽度是最大宽度为log2(read depth),其中read depth是FIFO的读取深度(即最大可以读取的数据字数量)。如果指定的宽度小于最大允许宽度,那么总线的较低位将被截去。
注意:
如果在rd_clk/clk的上升沿发生读操作,这个读操作将在下一个rd_clk/clk的上升沿反映在rd_data_count信号上。
在wr_clk/clk时钟域上的写操作可能需要经过多个时钟周期才能在rd_data_count中反映出来,这取决于FIFO的实现和跨时钟域同步的机制。
因此,在设计跨时钟域FIFO时,需要特别注意读写数据计数的更新和同步问题,以确保数据的正确性和系统的稳定性。
2.2 Write Data Count(写数据计数)
wr_data_count报告已写入FIFO的数据字数量。它永远不会报告比实际已写入的数据字更少的数量(尽管它可能会暂时报告更多的数量),以确保你永远不会因写入过多数据而导致FIFO溢出。
宽度:可以指定写数据计数总线的宽度,最大宽度为log2(write depth),其中write depth是FIFO的写入深度(即最大可以写入的数据字数量)。如果指定的宽度小于最大允许宽度,那么总线的较低位将被截去。
注意:
如果在wr_clk/clk的上升沿发生写操作,这个写操作将在下一个wr_clk/clk的上升沿反映在wr_data_count信号上。
在rd_clk/clk时钟域上的读操作可能需要经过多个时钟周期才能在wr_data_count中反映出来,这取决于FIFO的实现和跨时钟域同步的机制。
因此,在设计跨时钟域FIFO时,需要特别注意读写数据计数的更新和同步问题,以确保数据的正确性和系统的稳定性。
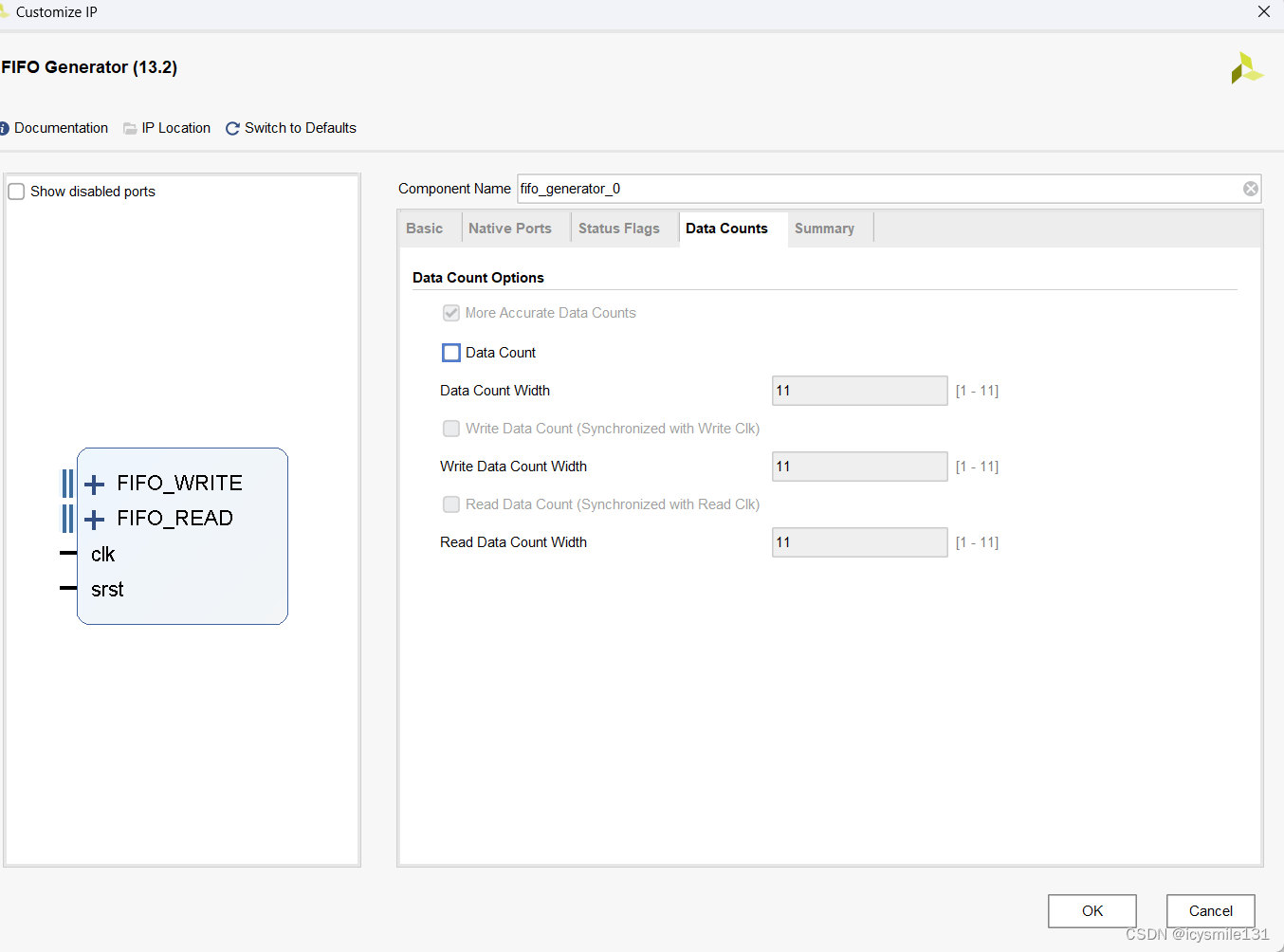
3 选择Native 接口采用First-Word Fall-Through模式时
当采用该模式时,除了上述的数据计数、读数据计数和写数据计数意外,当采用common时钟时More Accurate Data Counts为默认必选项,如下图。
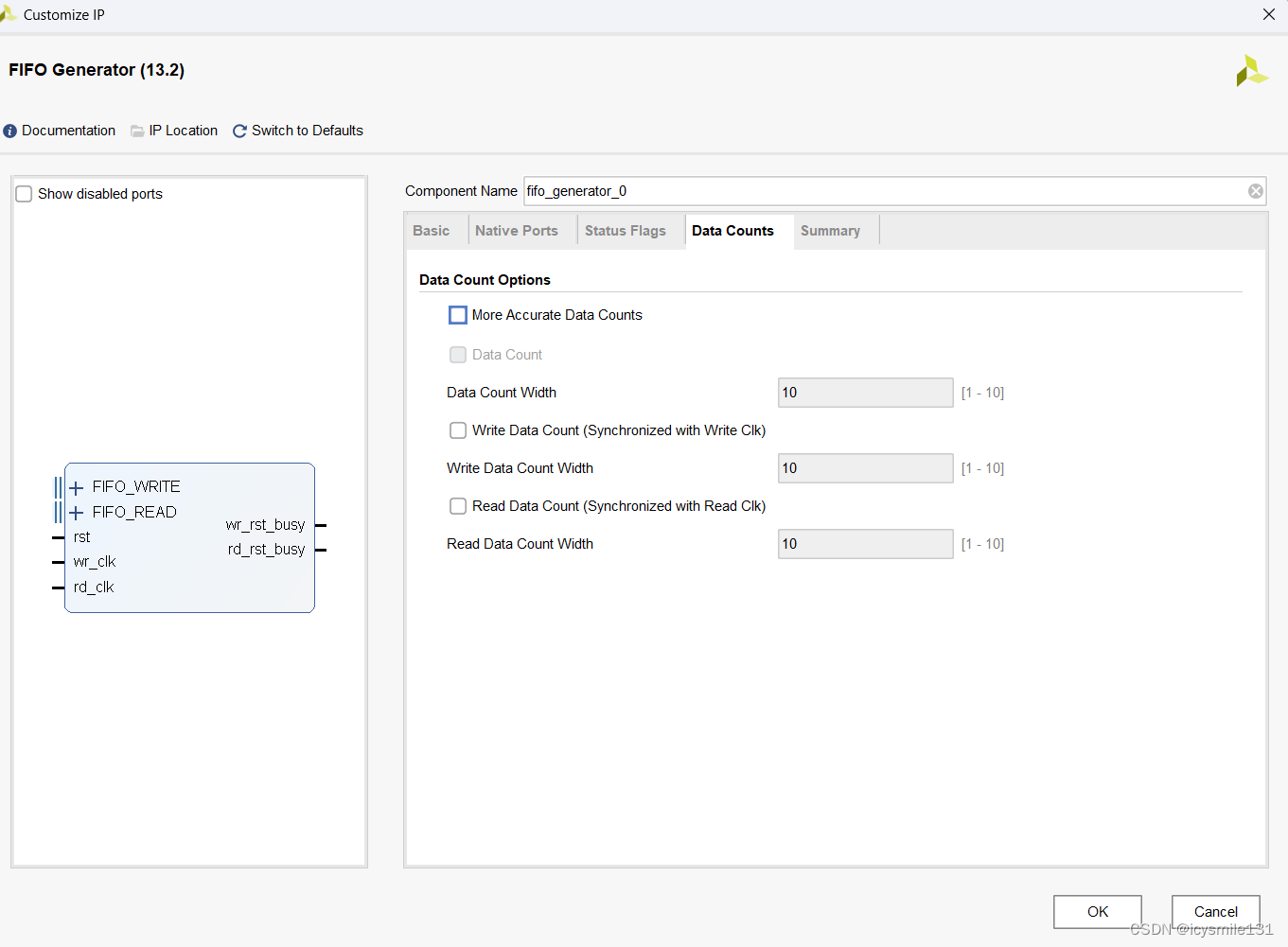
当选择Native 接口采用First-Word Fall-Through模式时,如果使用了Independent时钟,More Accurate Data Counts为可选项。
More Accurate Data Count(更精确的数据计数),目的是适应深度的增加并确保提供准确的数据计数。
当在Vivado IDE中选择“More Accurate Data Count ”选项时,wr_data_count(写入数据计数)、rd_data_count(读取数据计数)和data_count(数据计数)的宽度将分别增加,以容纳在First-Word Fall-Through情况下深度的增加。具体来说,它们的宽度分别为log2(write depth)+1、log2(read depth)+1和log2(depth)+1。
例如,对于一个深度为16的独立FIFO,具有对称的读写端口宽度,并选择了First-Word Fall-Through选项,实际的FIFO深度将从15增加到17(因为First-Word Fall-Through会占用一个额外的空间)。当使用准确的数据计数时,wr_data_count和rd_data_count的宽度将是5位,最大值为31(因为log2(17) = 4,但加1后变为5)。
当使用此选项时,不能使用wr_data_count、rd_data_count或data_count的任何一位来表示FIFO的状态,比如大约半满、四分之一满等。因为数据计数器的宽度增加了,直接使用传统的位表示方法(如最高位表示满或空)将不再准确。
对于上面的例子,如果想判断FIFO是否至少半满,你必须同时检查数据计数的最高位(MSB)和次高位(MSB-1)。这是因为数据计数器的范围从0(空)到31(对于5位计数器),而不是从0到16(对应于原始的FIFO深度)。因此,需要一个更复杂的条件来判断FIFO的状态。
这个选项允许更准确地跟踪FIFO中的元素数量,特别是在First-Word Fall-Through模式下,但它也引入了对FIFO状态判断的复杂性。因此,在使用此选项时,需要特别注意如何解释数据计数器的值。
2 选择Native 接口采用Built-in时钟
在选择Native接口时,如果使用了Built-in时钟,没有Data Counts选项页。
这篇关于FIFO Generate IP核使用——Data Counts页详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



