本文主要是介绍Deep Learning Part Seven基于RNN生成文本--24.5.2,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
不存在什么完美的文章,就好像没有完美的绝望。
——村上春树《且听风吟》
本章所学的内容
0.引子
本章主要利用LSTM实现几个有趣的应用:
先剧透一下:是AI聊天软件(现在做的ChatGPT(聊天神器,水论文高手等))和图像识别(可以应用于帮助盲人领域)

1.基于 RNN 的语言模型可以生成新的文本
文本生成叙述:

RnnlmGen 类的实现如下所示:
import sys
sys.path.append('..')
import numpy as np
from common.functions import softmax
from ch06.rnnlm import Rnnlm
from ch06.better_rnnlm import BetterRnnlmclass RnnlmGen(Rnnlm):def generate(self, start_id, skip_ids=None, sample_size=100):word_ids = [start_id]x = start_idwhile len(word_ids) < sample_size:x = np.array(x).reshape(1, 1)score = self.predict(x)p = softmax(score.flatten())sampled = np.random.choice(len(p), size=1, p=p)if (skip_ids is None) or (sampled not in skip_ids):x = sampledword_ids.append(int(x))return word_ids介绍了代码中的参数含义:

现在,使用这个 RnnlmGen 类进行文本生成。这里先在完全没有学习的状态(即权重参数是随机初始值的状态)下生成文本,代码如下所示:
import sys
sys.path.append('..')
from rnnlm_gen import RnnlmGen
from dataset import ptbcorpus, word_to_id, id_to_word = ptb.load_data('train')
vocab_size = len(word_to_id)
corpus_size = len(corpus)model = RnnlmGen()
# model.load_params('../ch06/Rnnlm.pkl')
# 设定start单词和skip单词
start_word = 'you'
start_id = word_to_id[start_word]
skip_words = ['N', '<unk>', '$']
skip_ids = [word_to_id[w] for w in skip_words]# 生成文本
word_ids = model.generate(start_id, skip_ids)
txt = ' '.join([id_to_word[i] for i in word_ids])
txt = txt.replace(' <eos>', '.\n')
print(txt)初次文本的生成:一句话就是:“真的烂!”

读入学习好的文本后,第二次进行文本生成:就是“勉强是个句子啦!”

第二次学习总结:(抽象为:机器逐步开始理解句子啦!)


改进后的文本生成结果:一句话就是:(行啊,学习的蛮好的,已经会使用语法啦!)

接着,我们使用更大的语料库,让机器加大学习的力度的结果:一句话是“虽然予以仍有些许问题,但是已经是一位合格的语言大师啦,这就是机器语言学习的魅力所在吧,像人类一样慢慢进步,但是就是这货学习不知道疲倦,而且学习速度极快,记忆力极好等”人工智能终究会比人类更加优秀;but 他不过是人类的工具而已,人类创造了他就是让他服务于人类,让人类过得更好!这才是人工智能的发明初衷吧!
不懂:
为何要让人和机器比较呢?二者根本没有任何可比性的,机器本身仅仅是一个工具罢了的,他可以永生不死,可以有好多优点,人类永远也无法超越,但是他必须始终为人类服务,人类最终应该与机器(人工智能)合作共赢,而不是互相残杀!这才是中国智慧的点点星光吧!

2.在进行文本生成时,重复“输入一个单词(字符),基于模型的输出(概率分布)进行采样”这一过程
语言模型的概率方案选择问题:
1.始终如一的选取概率最高的单词
2.概率性获得法,就是概率小的单词也有可能被选中的,(类比买彩票,概率再小也有机会中奖)

最终选取结果:
选择了后者
原因:我们想让每次生成的文本变得不一样的,这样更加有趣,更加灵活多变的。

确定性和概率性的理解:
确定性:就是只选取概率最高的那个,其他的一律不给机会(一成不变)
概率性:就是给概率高的那货的选取概率提高的,其他的也都有机会的(相对灵活多变)


啥是重复概率的输出和采样:
生成语句文本时,就是按照上述概率方法重复计算下一个单词的概率,最后生成一个优秀的句子。

3.通过组合两个 RNN,可以将一个时序数据转换为另一个时序数据(seq2seq)
seq2seq:简单来说,就相当于机器的翻译,让AI翻译软件帮你翻译英语阅读理解(核心:把一种语言通过两个RNN转化成另一种语言)(这里的语言就可以理解为时序数据的)

作者唠叨一下seq2seq的听着就困得原理概念

有意思的来啦,作者用翻译实例实战帮助读者理解seq2seq的核心(将一种事物转化为另一种事物)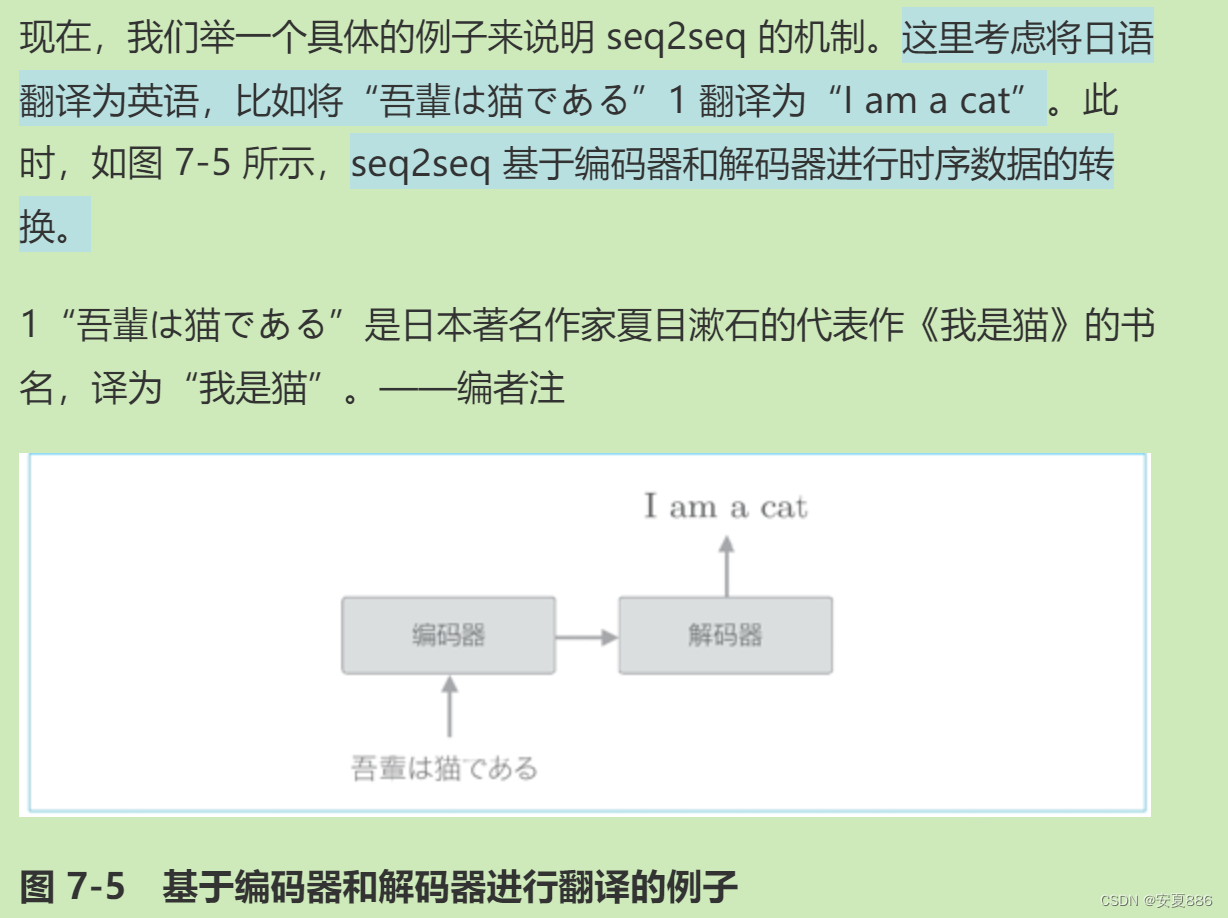
seq2seq的内部核心:两个RNN层
的讲解:
一个RNN的任务:编码
另一个RNN的任务:解码
简单理解:类似于:就是一个RNN将中文变成0和1的形式,然后呢,另一个RNN将这些0和1用英文的方式重新生成一个英文版

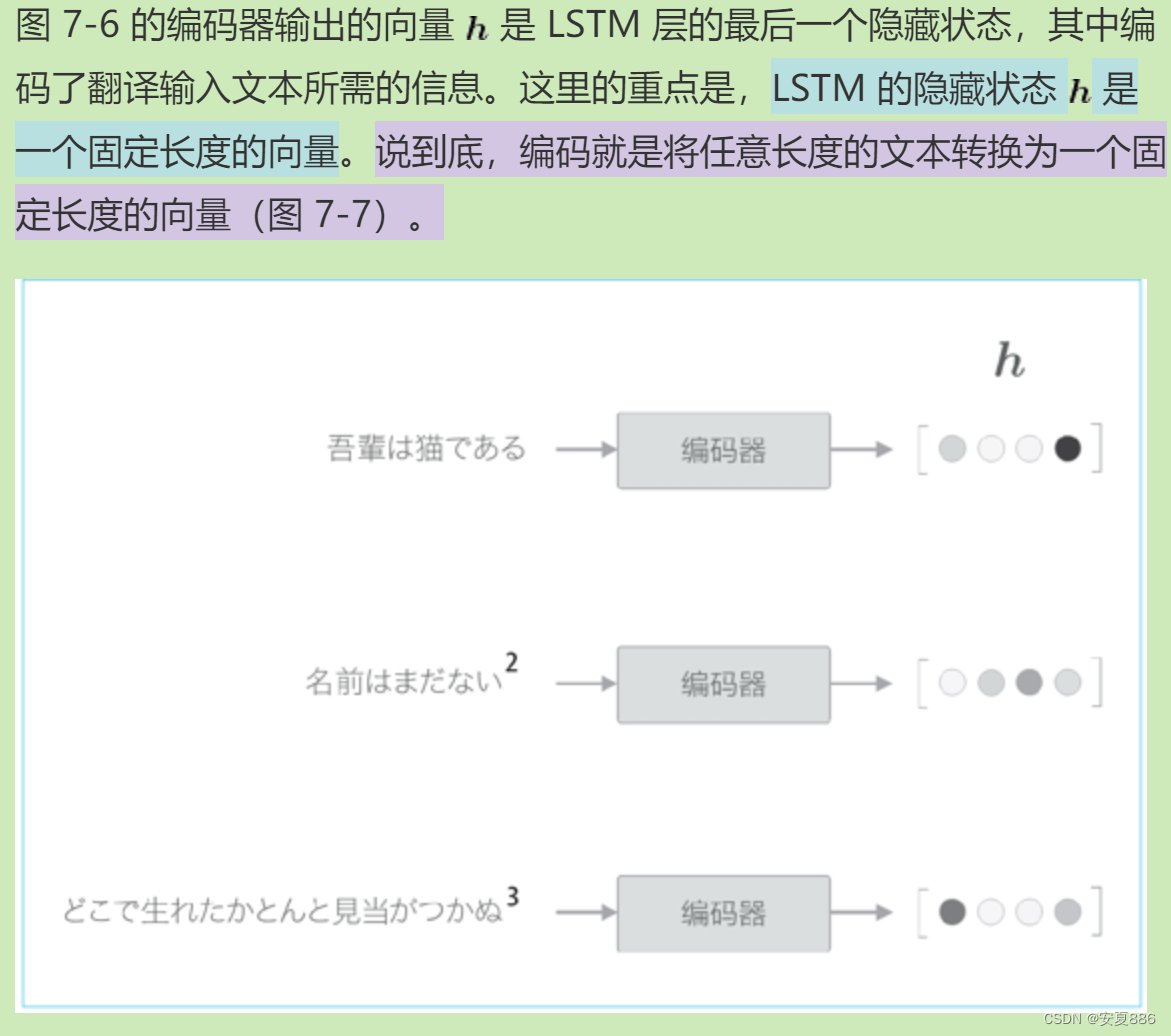


4.在 seq2seq 中,编码器对输入语句进行编码,解码器接收并解码这个编码信息,获得目标输出语句
好玩的来啦,这部分讲的是机器学习根据字符串计算公式的答案:
通过大量的学习,俗称记答案,来算题的,只能说牛皮!
但你别说,真的可以的!



利用填充法将位数补齐,避免报错。


5.反转输入语句(Reverse)和将编码信息分配给解码器的多个层(Peeky)可以有效提高seq2seq 的精度

seq2seq 的学习代码如下所示:
import sys
sys.path.append('..')
import numpy as np
import matplotlib.pyplot as plt
from dataset import sequence
from common.optimizer import Adam
from common.trainer import Trainer
from common.util import eval_seq2seq
from seq2seq import Seq2seq
from peeky_seq2seq import PeekySeq2seq# 读入数据集
(x_train, t_train), (x_test, t_test) = sequence.load_data('addition.txt')
char_to_id, id_to_char = sequence.get_vocab()# 设定超参数
vocab_size = len(char_to_id)
wordvec_size = 16
hidden_size = 128
batch_size = 128
max_epoch = 25
max_grad = 5.0# 生成模型/优化器/训练器
model = Seq2seq(vocab_size, wordvec_size, hidden_size)
optimizer = Adam()
trainer = Trainer(model, optimizer)acc_list = []
for epoch in range(max_epoch):trainer.fit(x_train, t_train, max_epoch=1,batch_size=batch_size, max_grad=max_grad)correct_num = 0for i in range(len(x_test)):question, correct = x_test[[i]], t_test[[i]]verbose = i < 10correct_num += eval_seq2seq(model, question, correct,id_to_char, verbose)acc = float(correct_num) / len(x_test)acc_list.append(acc)print('val acc %.3f%%' % (acc * 100))这里描述了:机器学习后,凭借记答案的本领看他能做对几道题,正确率如何。
初次记答案的正确率:惨不忍睹,但值得一提的是有做对的。
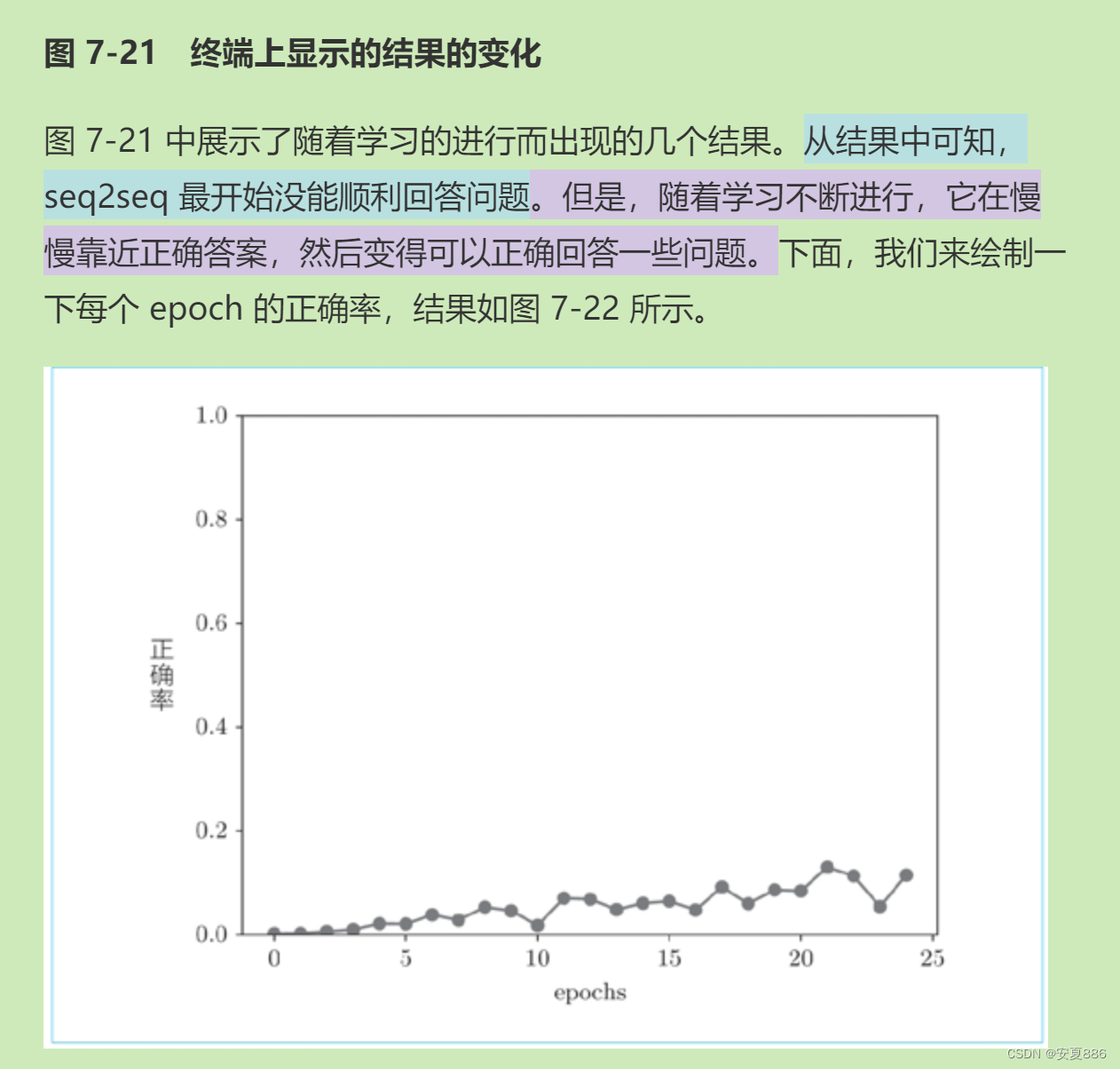
通过大牛改进,用反转输入法,记答案的本领再次提高。


从这里可以看出,记答案的正确率到了50%~60%,正确率显著提高。
# 读入数据集
(x_train, t_train), (x_test, t_test) = sequence.load_data('addition.txt')
...
x_train, x_test = x_train[:, ::-1], x_test[:, ::-1]
...

借助用偷窥大法来提高信息连锁反应,让信息共享,提高正确率。


PeekyDecoder 类的实现:
class PeekyDecoder:def __init__(self, vocab_size, wordvec_size, hidden_size):V, D, H = vocab_size, wordvec_size, hidden_sizern = np.random.randnembed_W = (rn(V, D) / 100).astype('f')lstm_Wx = (rn( H + D , 4 * H) / np.sqrt(H + D)).astype('f')lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')lstm_b = np.zeros(4 * H).astype('f')affine_W = (rn( H + H , V) / np.sqrt(H + H)).astype('f')affine_b = np.zeros(V).astype('f')self.embed = TimeEmbedding(embed_W)self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True)self.affine = TimeAffine(affine_W, affine_b)self.params, self.grads = [], []for layer in (self.embed, self.lstm, self.affine):self.params += layer.paramsself.grads += layer.gradsself.cache = Nonedef forward(self, xs, h):N, T = xs.shapeN, H = h.shapeself.lstm.set_state(h)out = self.embed.forward(xs)hs = np.repeat(h, T, axis=0).reshape(N, T, H)out = np.concatenate((hs, out), axis=2)out = self.lstm.forward(out)out = np.concatenate((hs, out), axis=2)score = self.affine.forward(out)self.cache = Hreturn score
咕哒,这里可以看到正确率达到了近100%,背答案也不是没有前途嘛。
感谢了偷窥大法和反转输入大法两位哥哥啦!
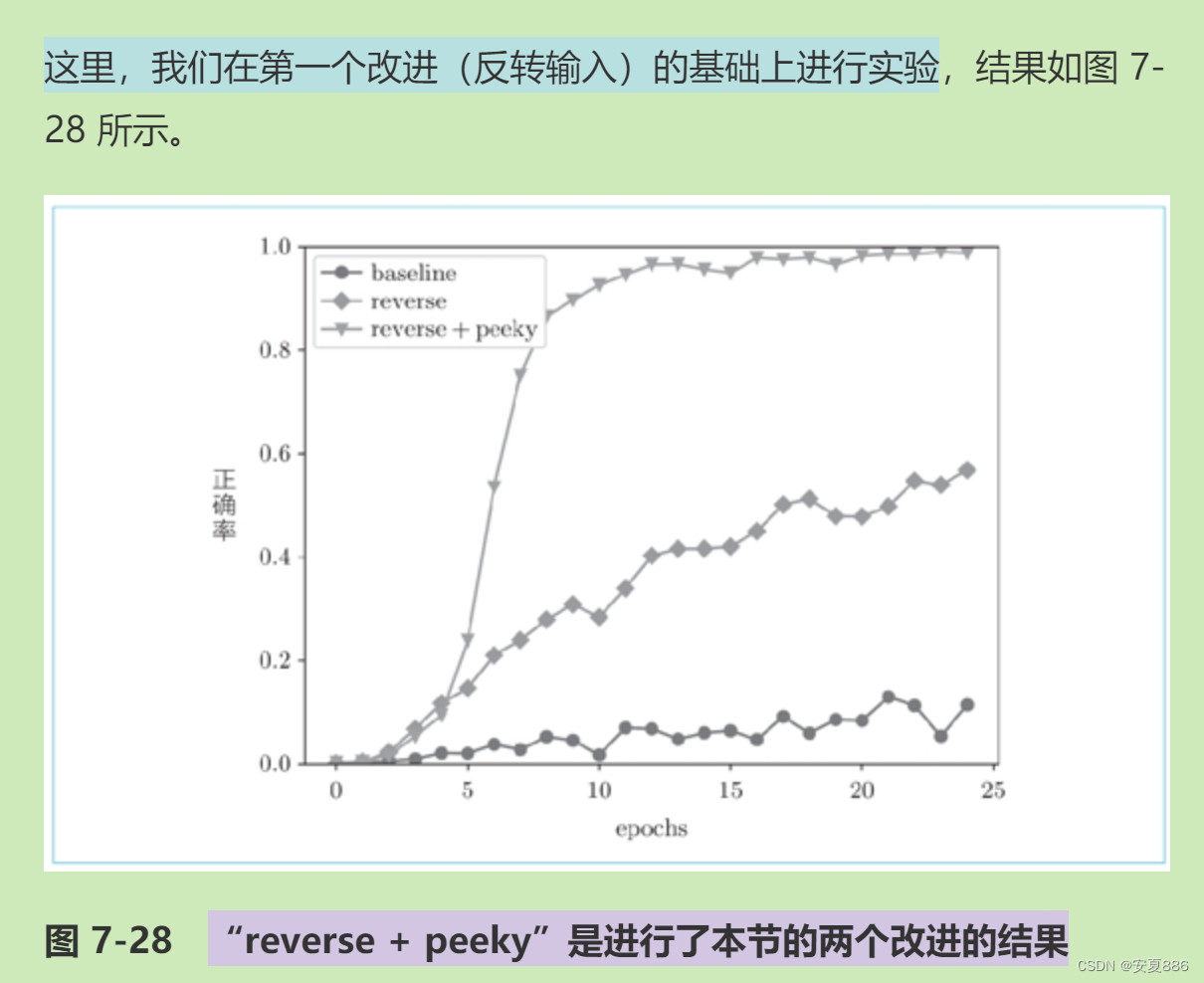

6.seq2seq 可以用在机器翻译、聊天机器人和自动图像描述等各种各样的应用中
现代前景:

聊天机器人:类似于现代婴儿版本的Chat GPT,牛!



相当于现代版的人脸识别等图像识别技术:六得嘞!




小结
本章我们探讨了基于 RNN 的文本生成。实际上,我们只是稍微改动了一下上一章的基于 RNN 的语言模型,增加了文本生成的功能。在本章后半部分,我们研究了 seq2seq,并使之成功学习了简单的加法。seq2seq 模型拼接了编码器和解码器,是组合了两个 RNN 的简单结构。但是,尽管 seq2seq 简单,却具有巨大的潜力,可以用于各种各样的应用。
另外,本章还介绍了改进 seq2seq 的两个方案—— Reverse 和 Peeky。我们对这两个方案进行了实现和评价,并确认了它们的效果。下一章我们将继续改进 seq2seq,届时深度学习中最重要的技巧之一 Attention 将会出现。我们将说明 Attention 的机制,然后基于它实现更强大的 seq2seq。
这篇关于Deep Learning Part Seven基于RNN生成文本--24.5.2的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




