本文主要是介绍golang学习笔记(内存逃逸分析),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
golang的内存逃逸
逃逸分析( Escape analysis) 是指由编译器决定内存分配的位置, 不需要程序员指定。 函数中申请一个新的对象。
- 如果分配在栈中, 则函数执行结束可自动将内存回收;
- 如果分配在堆中, 则函数执行结束可交给GC( 垃圾回收) 处理;
内存逃逸策略
每当函数中申请新的对象, 编译器会跟据该对象是否被函数外部引用来决定是否逃逸:
- 如果函数外部没有引用, 则优先放到栈中
- 如果函数外部存在引用, 则必定放到堆中;
注意, 对于函数外部没有引用的对象, 也有可能放到堆中, 比如内存过大超过栈的存储能力。
逃逸场景分析
指针逃逸
Go可以返回局部变量指针, 这其实是一个典型的变量逃逸案例, 示例代码如下:
package maintype Student struct {Name stringage int
}func NewStudent(name string, age int) *Student {stu := new(Student)stu.Name = namestu.age = agereturn stu
}
func main() {NewStudent("abcd", 24)
}
函数NewStudent()内部stu为局部变量, 其值通过函数返回值返回, stu本身为一指针, 其指向的内存地址不会是栈而是堆, 这就是典型的逃逸案例。
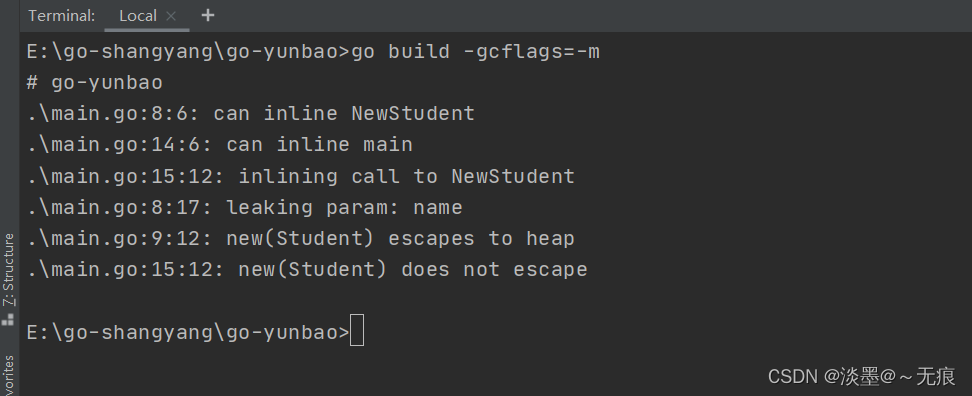
通过编译参数-gcflags=-m可以查年编译过程中的逃逸分析:
运行结果: 请注意运行结果中出现了escapes to heap,也就是发生了内存逃逸现象。
栈空间不足逃逸
分析一下下面代码会不会产生内存逃逸现象
package maintype Student struct {Name stringage int
}func Slice() {s := make([]int, 1000, 1000)for index, _ := range s {s[index] = index}
}
func main() {Slice()
}
上面代码Slice()函数中分配了一个1000个长度的切片, 是否逃逸取决于栈空间是否足够大。 直接查看编译提示, 如下可见并没有发生逃逸:
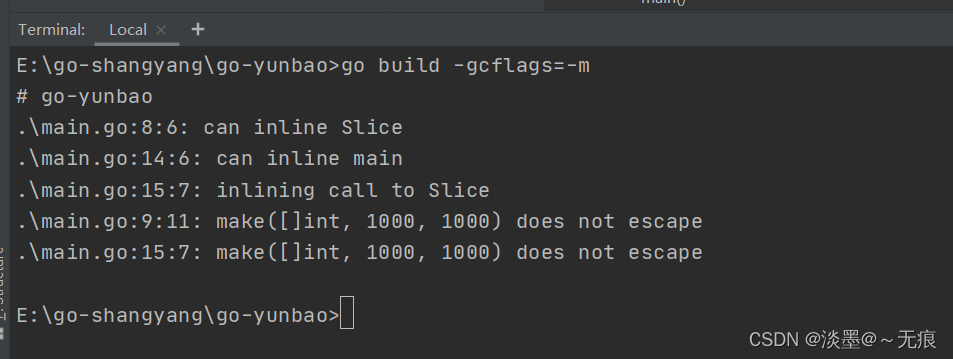
但是如果长度扩大10倍呢?那情况会怎么样?
package mainfunc Slice() {s := make([]int, 10000, 10000)for index, _ := range s {s[index] = index}
}
func main() {Slice()
}
结果:

我们发现当切片长度扩大到10000时就会逃逸。实际上当栈空间不足以存放当前对象时或无法判断当前切片长度时会将对象分配到堆中
动态类型逃逸
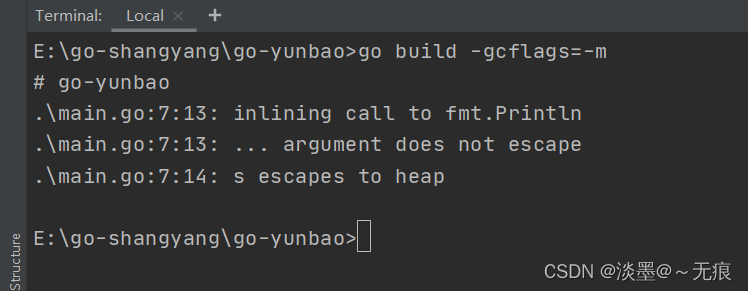
很多函数参数为interface类型, 比如fmt.Println(a …interface{}), 编译期间很难确定其参数的具体类型,也人产生逃逸。 如下代码所示:
package mainimport "fmt"func main() {s := "abcd"fmt.Println(s)
}
结果:上述代码s变量只是一个string类型变量, 调用fmt.Println()时会产生逃逸。
闭包引用对象逃逸
相信刷题的同学对这代码是十分的熟悉:
package mainimport "fmt"func Fibonacci() func() int {a, b := 0, 1return func() int {a, b = b, a + breturn a}
}
func main() {res := Fibonacci()for i := 0; i < 10; i++ {fmt.Printf("Print Result is %d\n" , res())}
}
这段代码的运行结果如下:
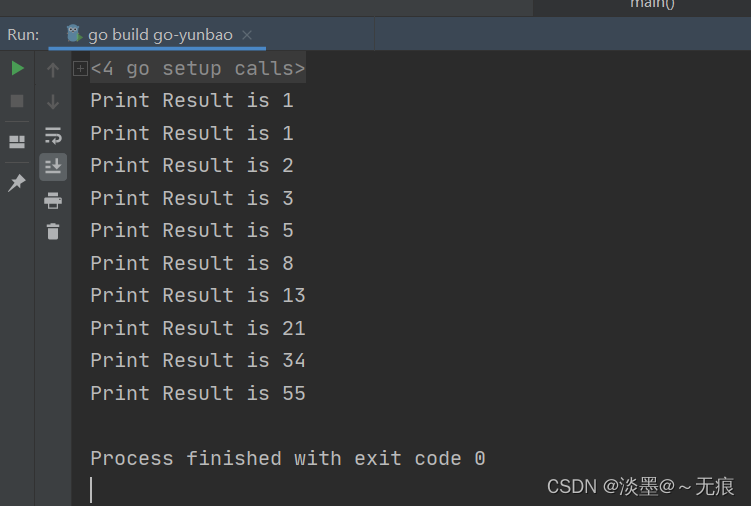
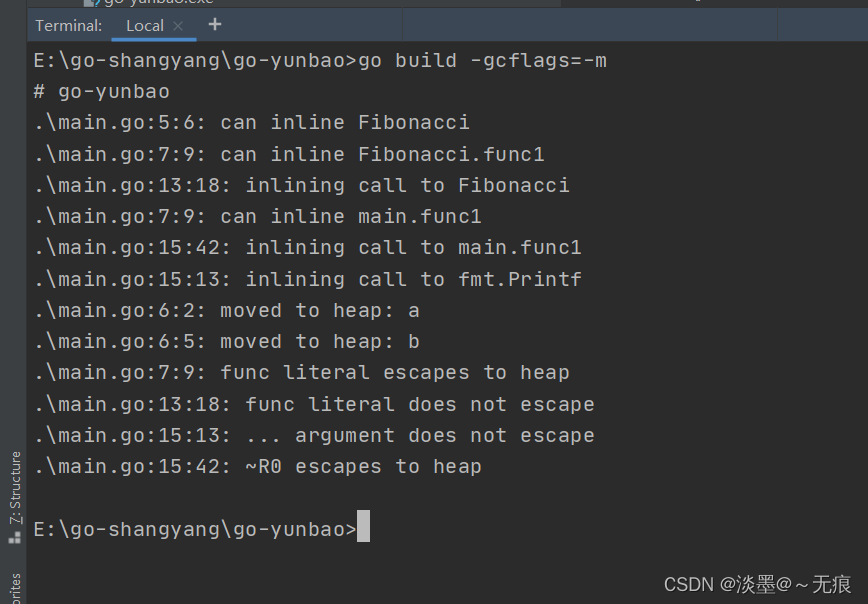
但是Fibonacci()函数中原本属于局部变量的a和b由于闭包的引用, 不得不将二者放到堆上, 以致产生逃逸:
总结
- 栈上分配内存比在堆中分配内存有更高的效率
- 栈上分配的内存不需要GC处理
- 堆上分配的内存使用完毕会交给GC处理
- 逃逸分析目的是决定内分配地址是栈还是堆
- 逃逸分析在编译阶段完成
这篇关于golang学习笔记(内存逃逸分析)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





