本文主要是介绍The Role of Subgroup Separability in Group-Fair Medical Image Classification,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- The Role of Subgroup Separability in Group-Fair Medical Image Classification
- 摘要
- 方法
- 实验结果
The Role of Subgroup Separability in Group-Fair Medical Image Classification
摘要
研究人员调查了深度分类器在性能上的差异。他们发现,分类器将个体分成子群的能力在医学影像模态和受保护特征之间存在显著差异;关键的是,他们表明这一特性能够预测算法偏差。通过理论分析和广泛的实证评估(代码可在 https://github.com/biomedia-mira/subgroup-separability 获取),他们发现子群可分性、子群差异和性能降级之间存在关系,尤其是在模型训练数据具有系统偏差(如欠诊断)的情况下。这些发现为模型如何产生偏见提供了新的视角,为公平医学影像人工智能的发展提供了重要见解。
方法
考虑一个二元疾病分类问题,对于每个图像 x ∈ X x \in X x∈X,我们希望预测一个类别标签 y ∈ Y : { y + , y − } y \in Y : \{y^+, y^-\} y∈Y:{y+,y−}。我们将 P : [ Y ∣ X ] → [ 0 , 1 ] P : [Y|X] \rightarrow [0, 1] P:[Y∣X]→[0,1] 表示图像和类别标签之间的基础映射。假设我们可以访问一个(有偏差的)训练数据集,其中 ( P_{\text{tr}} ) 是训练图像和训练标签之间的条件分布;如果 P tr ! = P P_{\text{tr}} != P Ptr!=P,我们称这样的数据集是有偏的。我们关注群体公平性,其中每个个体属于一个子群 a ∈ A a \in A a∈A,并且旨在学习一个公平模型,当部署在从 P P P 绘制的无偏测试数据集上时,该模型可以在所有群体上实现最佳性能。我们假设群体在两个数据集中保持一致。在这项工作中,我们考虑的偏差是欠诊断,这是一种标签噪音,其中一些真正的阳性个体 x + x^+ x+ 被误标为阴性。我们特别关注由于历史上医疗保健供给不平等或歧视性诊断政策而导致的欠诊断在特定子群中表现出来的情况。形式上,如果群体 A = a ∗ A = a^* A=a∗ 满足式 (1),则称该群体为欠诊断:
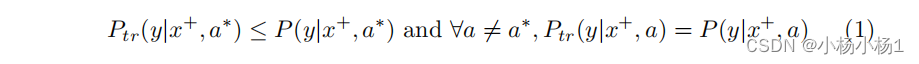
现在可以使用总概率法则,根据方程(2)中的子群映射来表达从图像到标签的整体映射。结合方程(1),这意味着方程(3)——在有偏训练数据集中,将真正的阳性个体分配为阳性标签的概率低于无偏测试集。
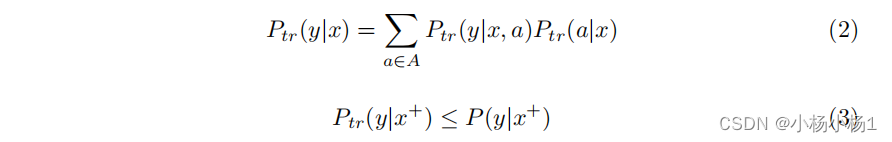
在训练过程中,使用经验风险最小化的监督学习旨在获得一个模型 (\hat{p}),将图像映射到预测的标签 y ^ = argmax y ∈ Y p ^ ( y ∣ x ) \hat{y} = \text{argmax}_{y \in Y} \hat{p}(y|x) y^=argmaxy∈Yp^(y∣x),使得对所有 ( x , y ) (x, y) (x,y) ,近似于 P tr ( y ∣ x ) P_{\text{tr}}(y|x) Ptr(y∣x)。由于该模型反映了有偏的训练分布,我们预期在无偏测试集上评估时,来自训练数据的欠诊断将在学习到的模型中体现出来。然而,学得模型的错误分布取决于子群可分性。根据方程(2),个体预测是每个子群映射的线性组合,权重是每个个体属于每个群体的概率。当子群可分性较高时,由于敏感信息的存在,模型会学习到每个子群的不同映射,如方程(4)和(5)所示。因此,该模型在保留其他群体的无偏映射的同时,会对群体 A = a ∗ A = a^* A=a∗ 进行欠诊断。
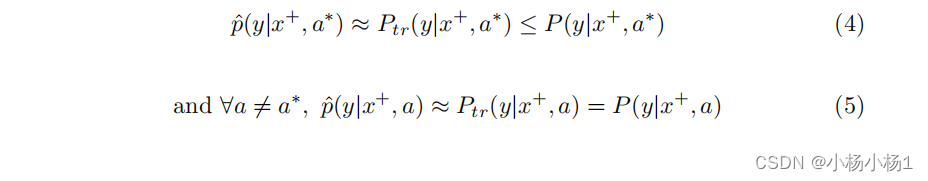
Equation (4) 和 (5) 显示,在测试时,我们的模型在欠诊断的子群中将表现出比其他子群更差的性能。实际上,考虑真正率(True Positive Rate,TPR)作为性能指标。无偏模型的群体真正率 TPR ( a u ) \text{TPR}(a_u) TPR(au) 在方程 (6) 中表示。
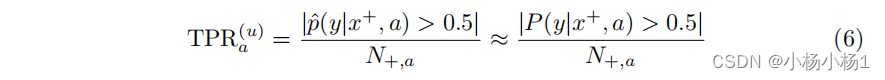
这里, N + , a N_{+,a} N+,a 表示测试集中属于群体 ( a ) 的阳性样本数。请记住,在实践中,我们必须在有偏的训练分布 P tr P_{\text{tr}} Ptr上训练我们的模型。因此,我们从方程 (4) 和 (5) 推导出这样一个模型的测试时真正率 TPR b a \text{TPR}_b^a TPRba,得到方程 (7) 和 (8)。
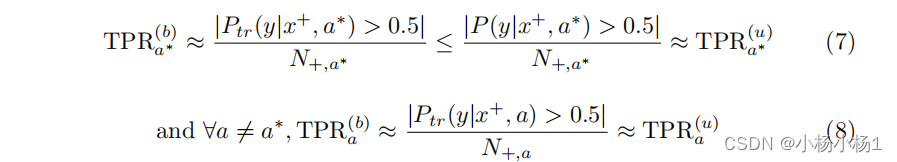
在高子群可分性的情况下,方程 (7) 和 (8) 表明欠诊断群的真正率直接受到训练集中的偏差影响,而其他群体主要不受影响。鉴于各群体之间的差异,一个合适选择的群体公平度量可能能够识别出偏差,有时甚至不需要访问无偏测试集。另一方面,当子群可分性较低时,这个性质并不成立。对于不可分离的群体(即 P ( a ∣ x ) ≈ 1 ∣ A ∣ P(a|x) \approx \frac{1}{|A|} P(a∣x)≈∣A∣1 ,对于所有 a ∈ A a \in A a∈A),训练模型将无法学习到不同的子群映射,如方程 (9) 所示。
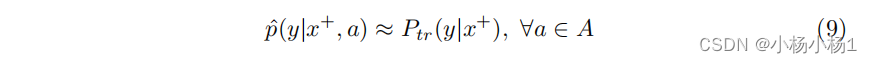
方程 (3) 和 (9) 暗示训练模型的性能对所有群体都会下降。回到真正率 (TPR) 的例子,当可分性较差时,方程 (10) 表示所有群体的性能下降。在这种情况下,我们期望性能下降在各个群体之间是均匀的,因此不会被群体公平性指标检测到。性能下降的严重程度取决于欠诊断子群中受损标签的比例以及数据集中欠诊断子群的大小。
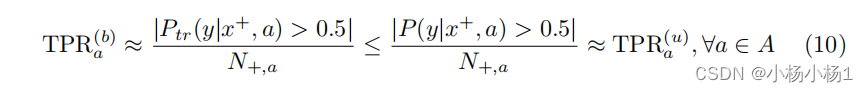
我们已经推导出了欠诊断偏差对分类器性能的影响,针对高和低子群可分性这两种极端情况。在实践中,真实数据集的子群可分性可能在这些极端之间连续变化。在第 4 节中,我们通过实证研究探讨了以下几个方面:(i) 在真实环境中子群可分性如何变化,(ii) 当向数据集中添加欠诊断偏差时,可分性如何影响每个群体的性能,(iii) 模型如何在其表示中编码敏感信息。
实验结果
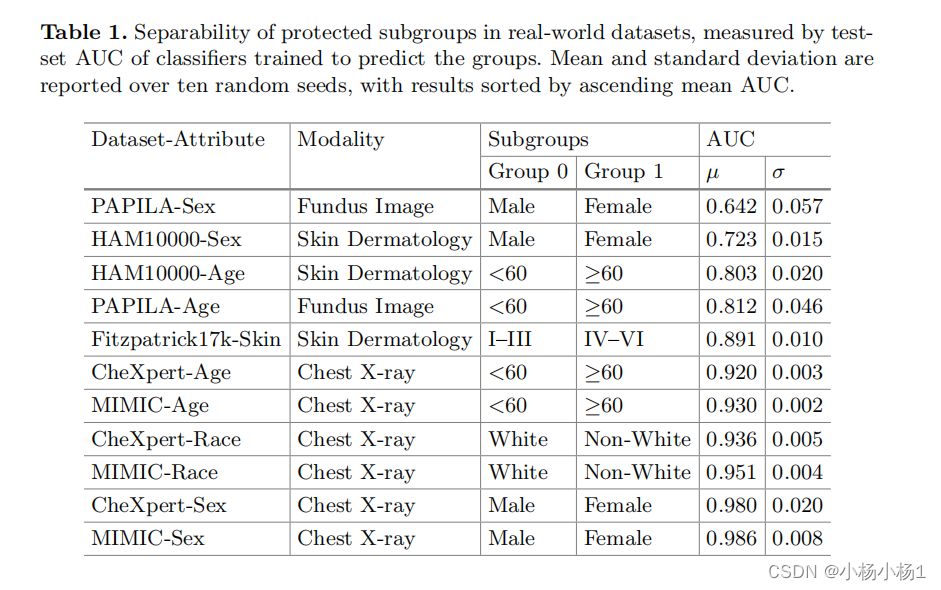
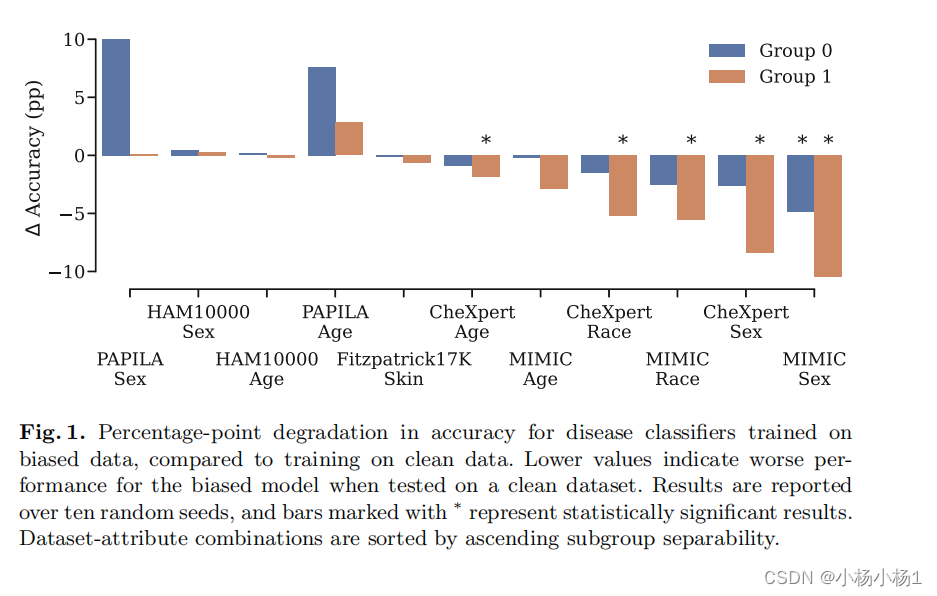
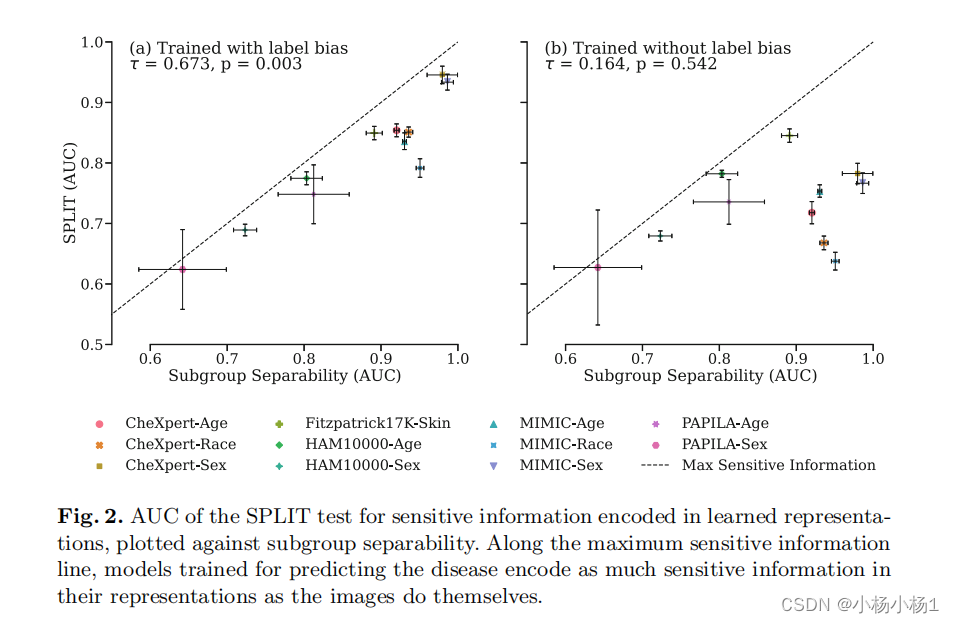
这篇关于The Role of Subgroup Separability in Group-Fair Medical Image Classification的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!