本文主要是介绍【R语言数据分析】基本运算与数据导入速查,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
R语言中命名可以包含英文字母,下划线,数字,点,下划线和数字不能作为名字的开头,点可以开头,但是点开头后面不能跟数字。一般的命名就是只使用英文和下划线就够了。
四则运算
R语言的除法是即使给的两个数都是整数,结果也可以是小数。
取整符号是%/%,取余符号是%%,向上取整使用函数ceiling,比如ceiling(7.2)表示取一个不低于7.2的最小整数,结果为8,向下取整使用函数floor(),比如floor(7.2)表示取一个不高于7.2的最大整数,结果为7
幂次运算
R语言可以直接使用5^2,5^3这样的表达式来计算5的平方,5的三次方这样的幂次运算,无序调用函数。
开平方运算
开平方要使用函数sqrt,比如sqrt(64)结果为8
三角函数运算
R语言可以直接使用sin,cos,tan这样的三角函数来计算三角函数的值,但是主要这些函数需要的参数是弧度而非角度,弧度与角度的换算关系为180度等于π弧度,换句话说1度就是π/180弧度,在R语言中使用pi来表示π,也就是说我们在求某个角度的三角函数值的时候一般可以写成sin(pi/180*x),其中x为要求的角度。
对数函数运算
求对数使用函数log,比如log(x,base=y)表示以y为底,x的对数,举个例子,log(100,base=10)表示以10为底,100的对数也就是2,其中base参数可以省略,此时默认底数为e,相当于求ln(x)
指数函数运算
使用exp(x)求e的x次方。
统计学运算
求平均值:mean(x)
求标准差:sd(x)
求方差:var(x)
求范围:range(x)
求中位数:median(x)
求四分位数:quantile(x)
求最大值:max(x)
求最小值:min(x)
其中x是一个数据集,一般是向量。
绝对值运算
使用函数abs(x)求x的绝对值
保留小数
round(x,y)表示对x保留到y位小数,比如round(pi,2)结果为3.14
逻辑运算符
与(且):&
或:|
非:!
导入txt格式的文件使用的函数是read.table(路径).R语言不能识别\,只能识别\\或者/。在复制windows中文件的路径的时候可能会出现\,我们要注意修改。
如果导入的文件第一行是列名而非数据,需要引入参数header=T,否则读取到的数据是这样的

在引入参数header=T之后,得到的数据是这样的
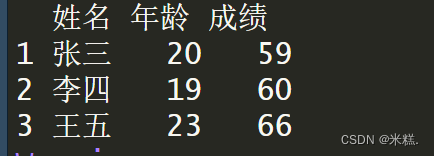
使用函数read.table得到的是一个数据框。
导入excel表格数据
比如有这样一个表格数据
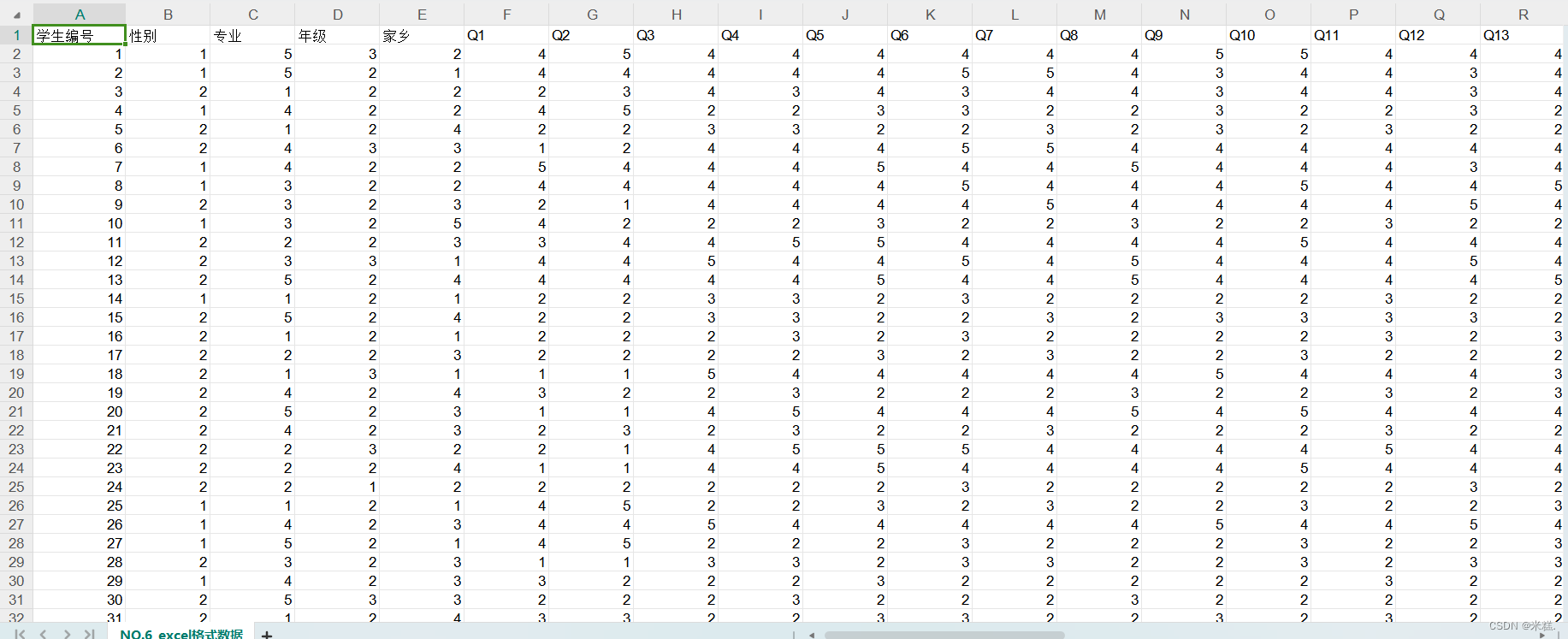
这是一份来自于调查问卷的数据,只不过可能是用1和2这样的数字代表了不同的含义比如选择了A,B这样的选项。可以点击Rstudio自带的import按键导入R
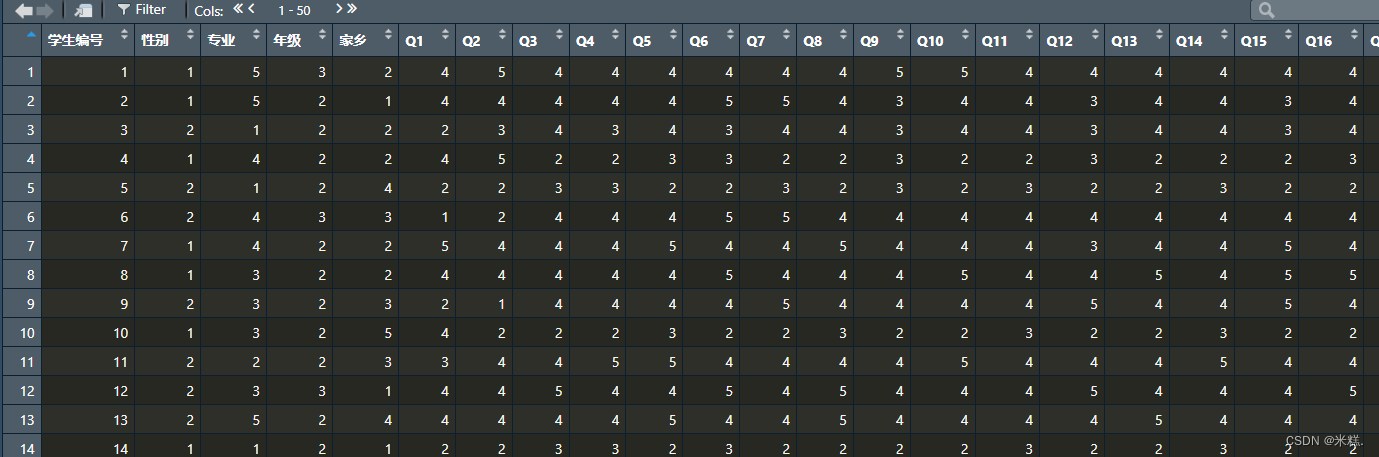
执行代码

首先第一句是因为导入的文件名字有点长,所以把他赋给了mydata变量,便于后面书写,然后是把数据集里面的性别这一列的数据1,2代表的含义转换成男,女,效果如图,转换成因子的写法好处是能够把这里的性别转换成一个分类变量。

实际上不转换成因子仍然可以修改数据框内容,比如

表示如果性别是1就改成男,否则就改成女,效果如图

有时候还需要导入csv格式的数据,对于这种格式数据的导入只能使用代码,无法通过点击,导入csv格式的数据使用的函数是read.csv
这篇关于【R语言数据分析】基本运算与数据导入速查的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






