本文主要是介绍某米社区请求data类型multipart_form-data分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
-
随笔记录
之前未曾遇到请求的Content-Type:multipart/form-data; boundary=----WebKitFormBoundary9Fxpi3Dvlnhm3MKq,今天就简单是根据目标网站进行分析下,目标站点是:aHR0cHM6Ly93ZWIudmlwLm1pdWkuY29tL3BhZ2UvaW5mby9taW8vbWlvL3BjU2VhcmNoP2Zyb21QYXRobmFtZT1taW9Cb2FyZExpdmUmYXBwX3ZlcnNpb249ZGV2LjIwMDUx
-
抓包分析
通过抓包查看,请求data类型为multipart/form-data; boundary=----WebKitFormBoundary9Fxpi3Dvlnhm3MKq
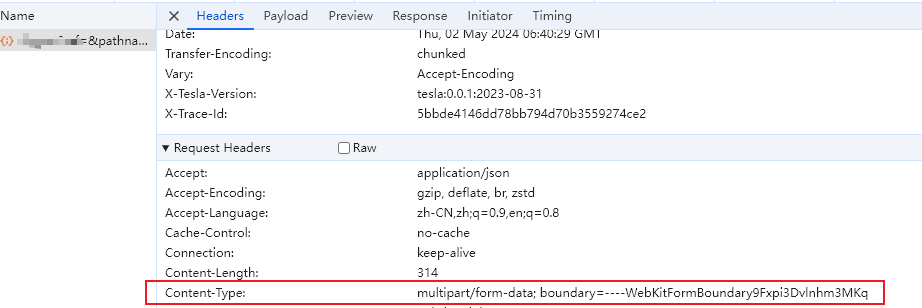
查看表单数据
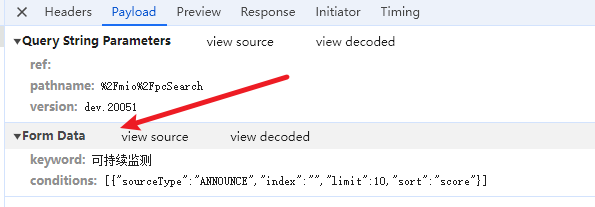
点击view source就会展示出以【------WebKitFormBoundary9Fxpi3Dvlnhm3MKq】 进行分割的参数
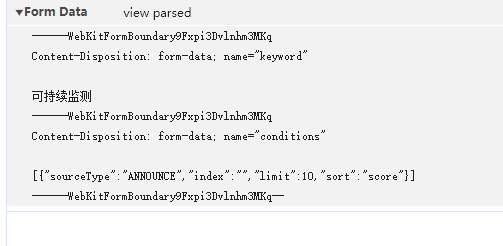
响应无特殊格式,为正常的json数据

-
python模拟请求
这篇关于某米社区请求data类型multipart_form-data分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






