本文主要是介绍Flink WaterMark 详解及结合 WaterMark 处理延迟数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在 3.1 节中讲解了 Flink 中的三种 Time 和其对应的使用场景,然后在 3.2 节中深入的讲解了 Flink 中窗口的机制以及 Flink 中自带的 Window 的实现原理和使用方法。如果在进行 Window 计算操作的时候,如果使用的时间是 Processing Time,那么在 Flink 消费数据的时候,它完全不需要关心的数据本身的时间,意思也就是说不需要关心数据到底是延迟数据还是乱序数据。因为 Processing Time 只是代表数据在 Flink 被处理时的时间,这个时间是顺序的。但是如果你使用的是 Event Time 的话,那么你就不得不面临着这么个问题:事件乱序 & 事件延迟。
下图表示选择 Event Time 与 Process Time 的实际效果图:
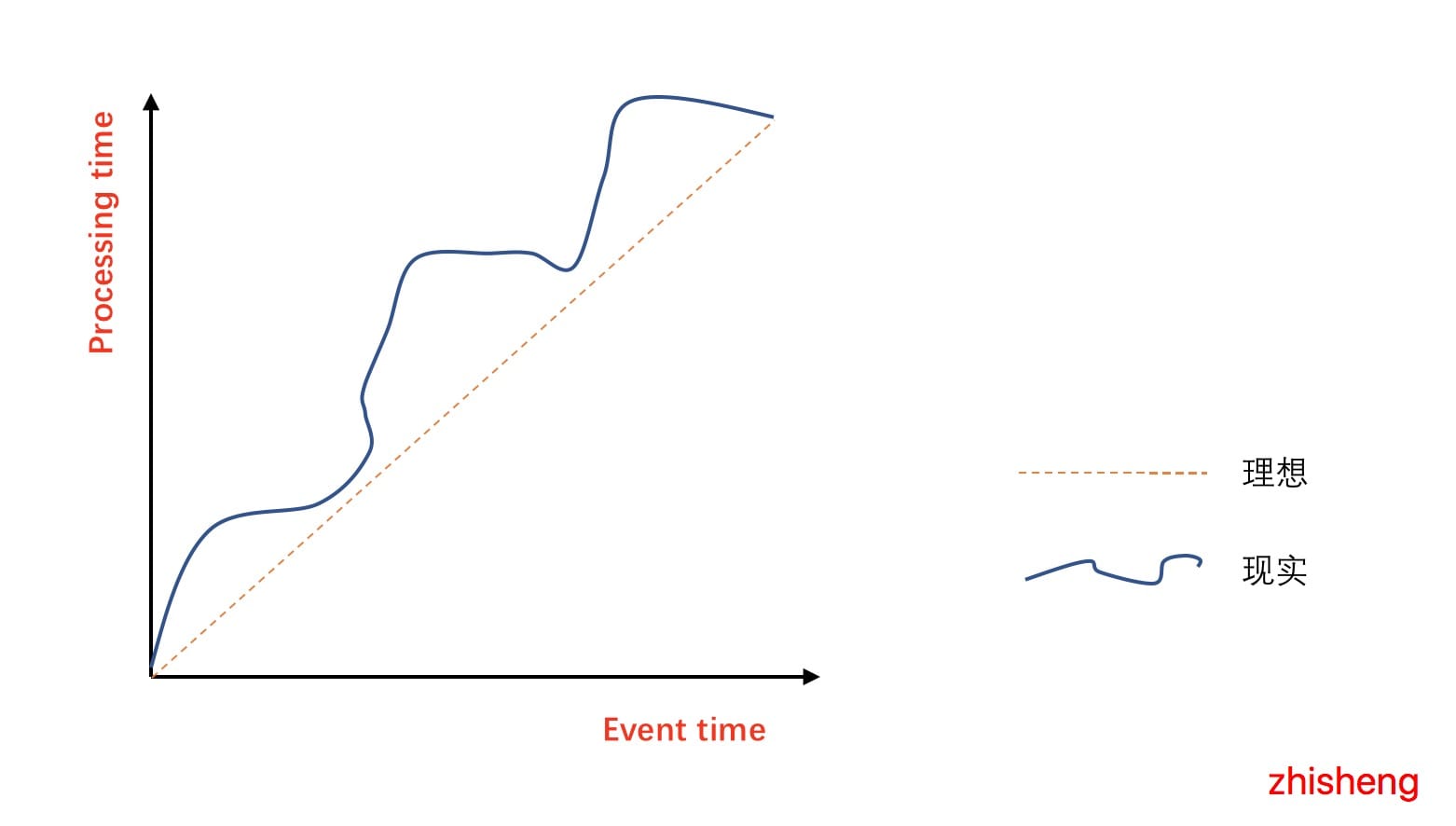
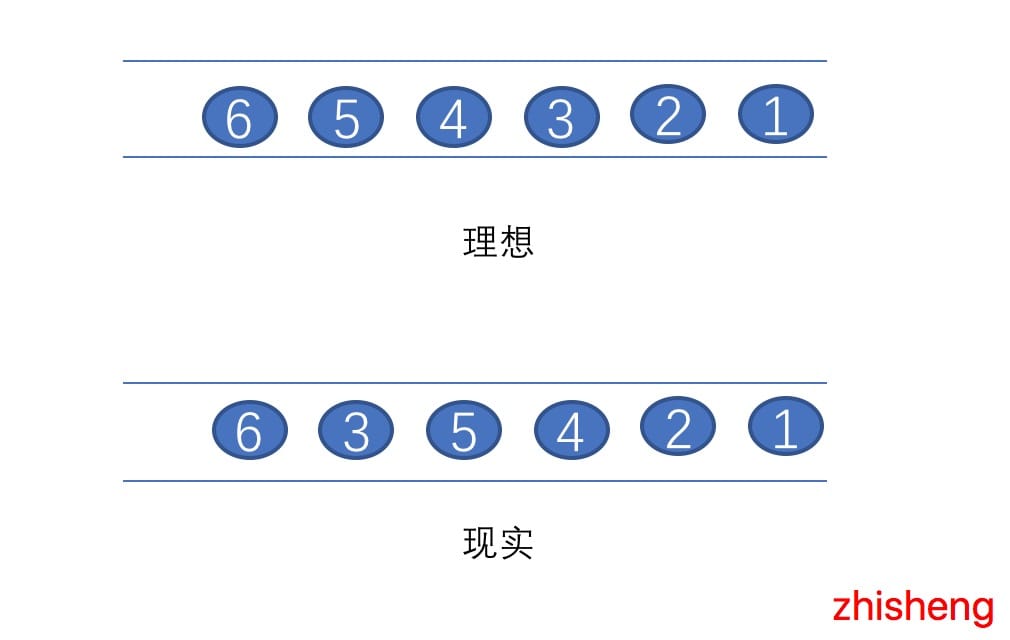
在理想的情况下,Event Time 和 Process Time 是相等的,数据发生的时间与数据处理的时间没有延迟,但是现实却仍然这么骨感,会因为各种各样的问题(网络的抖动、设备的故障、应用的异常等原因)从而导致如图中曲线一样,Process Time 总是会与 Event Time 有一些延迟。所谓乱序,其实是指 Flink 接收到的事件的先后顺序并不是严格的按照事件的 Event Time 顺序排列的。比如下图:
然而在有些场景下,其实是特别依赖于事件时间而不是处理时间,比如:
- 错误日
这篇关于Flink WaterMark 详解及结合 WaterMark 处理延迟数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



