本文主要是介绍Flink性能调优小小总结,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 配置内存
操作场景
Flink是依赖内存计算,计算过程中内存不够对Flink的执行效率影响很大。可以通过监控GC(Garbage Collection),评估内存使用及剩余情况来判断内存是否变成性能瓶颈,并根据情况优化。
监控节点进程的YARN的Container GC日志,如果频繁出现Full GC,需要优化GC。
GC的配置:在客户端的"conf/flink-conf.yaml"配置文件中,在“env.java.opts”配置项中添加参数:
-Xloggc:<LOG_DIR>/gc.log
-XX:+PrintGCDetails
-XX:-OmitStackTraceInFastThrow
-XX:+PrintGCTimeStamps
-XX:+PrintGCDateStamps
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=20
-XX:GCLogFileSize=20M此处默认已经添加GC日志。
操作步骤
优化GC
调整老年代和新生代的比值。在客户端的“conf/flink-conf.yaml”配置文件中,在“env.java.opts”配置项中添加参数:“-XX:NewRatio”。如“ -XX:NewRatio=2”,则表示老年代与新生代的比值为2:1,新生代占整个堆空间的1/3,老年代占2/3。
开发Flink应用程序时,优化DataStream的数据分区或分组操作。
当分区导致数据倾斜时,需要考虑优化分区。避免非并行度操作,有些对DataStream的操作会导致无法并行,例如WindowAll。keyBy尽量不要使用String。
2 设置并行度
操作场景
并行度控制任务的数量,影响操作后数据被切分成的块数。调整并行度让任务的数量和每个任务处理的数据与机器的处理能力达到最优。查看CPU使用情况和内存占用情况,当任务和数据不是平均分布在各节点,而是集中在个别节点时,可以增大并行度使任务和数据更均匀的分布在各个节点。增加任务的并行度,充分利用集群机器的计算能力,一般并行度设置为集群CPU核数总和的2-3倍。
操作步骤
任务的并行度可以通过以下四种层次(按优先级从高到低排列)指定,用户可以根据实际的内存、CPU、数据以及应用程序逻辑的情况调整并行度参数。
算子层次
一个算子、数据源和sink的并行度可以通过调用setParallelism()方法来指定,例如
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> text = [...]
DataStream<Tuple2<String, Integer>> wordCounts = text.flatMap(new LineSplitter()).keyBy(0).timeWindow(Time.seconds(5)).sum(1).setParallelism(5);
wordCounts.print();
env.execute("Word Count Example");执行环境层次
Flink程序运行在执行环境中。执行环境为所有执行的算子、数据源、data sink定义了一个默认的并行度。
执行环境的默认并行度可以通过调用setParallelism()方法指定。例如:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(3);DataStream<String> text = [...]DataStream<Tuple2<String, Integer>> wordCounts = [...]wordCounts.print();env.execute("Word Count Example");客户端层次
并行度可以在客户端将job提交到Flink时设定。对于CLI客户端,可以通过“-p”参数指定并行度。例如:./bin/flink run -p 10 ../examples/WordCount-java.jar
系统层次
在系统级可以通过修改Flink客户端conf目录下的“flink-conf.yaml”文件中的“parallelism.default”配置选项来指定所有执行环境的默认并行度。
3.配置进程参数
操作场景
Flink on YARN模式下,有JobManager和TaskManager两种进程。在任务调度和运行的过程中,JobManager和TaskManager承担了很大的责任。
因而JobManager和TaskManager的参数配置对Flink应用的执行有着很大的影响意义。用户可通过如下操作对Flink集群性能做优化。
操作步骤
1.配置JobManager内存
JobManager负责任务的调度,以及TaskManager、RM之间的消息通信。当任务数变多,任务平行度增大时,JobManager内存都需要相应增大。您可以根据实际任务数量的多少,为JobManager设置一个合适的内存。
在使用yarn-session命令时,添加“-jm MEM”参数设置内存。
在使用yarn-cluster命令时,添加“-yjm MEM”参数设置内存。
2.配置TaskManager个数
每个TaskManager每个核同时能跑一个task,所以增加了TaskManager的个数相当于增大了任务的并发度。在资源充足的情况下,可以相应增加TaskManager的个数,以提高运行效率。
在使用yarn-session命令时,添加“-n NUM”参数设置TaskManager个数。
在使用yarn-cluster命令时,添加“-yn NUM”参数设置TaskManager个数。
3.配置TaskManager Slot数
每个TaskManager多个核同时能跑多个task,相当于增大了任务的并发度。但是由于所有核共用TaskManager的内存,所以要在内存和核数之间做好平衡。
在使用yarn-session命令时,添加“-s NUM”参数设置SLOT数。
在使用yarn-cluster命令时,添加“-ys NUM”参数设置SLOT数。
4.配置TaskManager内存
TaskManager的内存主要用于任务执行、通信等。当一个任务很大的时候,可能需要较多资源,因而内存也可以做相应的增加。
将在使用yarn-sesion命令时,添加“-tm MEM”参数设置内存。
将在使用yarn-cluster命令时,添加“-ytm MEM”参数设置内存。
设计分区方法
操作场景
合理的设计分区依据,可以优化task的切分。在程序编写过程中要尽量分区均匀,这样可以实现每个task数据不倾斜,防止由于某个task的执行时间过长导致整个任务执行缓慢。
操作步骤
以下是几种分区方法
随机分区:将元素随机地进行分区。dataStream.shuffle();
Rebalancing (Round-robin partitioning):基于round-robin对元素进行分区,使得每个分区负责均衡。对于存在数据倾斜的性能优化是很有用的。dataStream.rebalance();
Rescaling:以round-robin的形式将元素分区到下游操作的子集中。如果你想要将数据从一个源的每个并行实例中散发到一些mappers的子集中,用来分散负载,但是又不想要完全rebalance 介入(引入rebalance()),这会非常有用。dataStream.rescale();
广播:广播每个元素到所有分区。dataStream.broadcast();
自定义分区:使用一个用户自定义的Partitioner对每一个元素选择目标task,由于用户对自己的数据更加熟悉,可以按照某个特征进行分区,从而优化任务执行。简单示例如下所示:
// fromElements构造简单的Tuple2流
DataStream<Tuple2<String, Integer>> dataStream = env.fromElements(Tuple2.of("hello",1), Tuple2.of("test",2), Tuple2.of("world",100));
// 定义用于分区的key值,返回即属于哪个partition的,该值加1就是对应的子任务的id号
Partitioner<Tuple2<String, Integer>> strPartitioner = new Partitioner<Tuple2<String, Integer>>() {@Overridepublic int partition(Tuple2<String, Integer> key, int numPartitions) {return (key.f0.length() + key.f1) % numPartitions;}
};
// 使用Tuple2进行分区的key值
dataStream.partitionCustom(strPartitioner, new KeySelector<Tuple2<String, Integer>, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> getKey(Tuple2<String, Integer> value) throws Exception {return value;}
}).print();配置netty网络通信
操作场景
Flink通信主要依赖netty网络,所以在Flink应用执行过程中,netty的设置尤为重要,网络通信的好坏直接决定着数据交换的速度以及任务执行的效率。
操作步骤
以下配置均可在客户端的“conf/flink-conf.yaml”配置文件中进行修改适配,默认已经是相对较优解,请谨慎修改,防止性能下降。
•“taskmanager.network.netty.num-arenas”:默认是“taskmanager.numberOfTaskSlots”,表示netty的域的数量。
•“taskmanager.network.netty.server.numThreads”和“taskmanager.network.netty.client.numThreads”:默认是“taskmanager.numberOfTaskSlots”,表示netty的客户端和服务端的线程数目设置。
•“taskmanager.network.netty.client.connectTimeoutSec”:默认是120s,表示taskmanager的客户端连接超时的时间。
“taskmanager.network.netty.sendReceiveBufferSize”:默认是系统缓冲区大小(cat /proc/sys/net/ipv4/tcp _ [rw]mem) ,一般为4MB,表示netty的发送和接收的缓冲区大小。
“taskmanager.network.netty.transport”:默认为“nio”方式,表示netty的传输方式,有“nio”和“epoll”两种方式。
解决数据倾斜
当数据发生倾斜(某一部分数据量特别大),虽然没有GC(Gabage Collection,垃圾回收),但是task执行时间严重不一致。
需要重新设计key,以更小粒度的key使得task大小合理化。
修改并行度。
调用rebalance操作,使数据分区均匀。
缓冲区超时设置
由于task在执行过程中存在数据通过网络进行交换,数据在不同服务器之间传递的缓冲区超时时间可以通过setBufferTimeout进行设置。
当设置“setBufferTimeout(-1)”,会等待缓冲区满之后才会刷新,使其达到最大吞吐量;当设置“setBufferTimeout(0)”时,可以最小化延迟,数据一旦接收到就会刷新;当设置“setBufferTimeout”大于0时,缓冲区会在该时间之后超时,然后进行缓冲区的刷新。示例可以参考如下:env.setBufferTimeout(timeoutMillis); env.generateSequence(1,10).map(new MyMapper()).setBufferTimeout(timeoutMillis);
Checkpoint 调优
1.什么是 checkpoint 简单地说就是 Flink 为了达到容错和 exactly-once 语义的功能,定期把 state 持久化下来,而这一持久化的过程就叫做 checkpoint ,它是 Flink Job 在某一时刻全局状态的快照。
当我们要对分布式系统实现一个全局状态保留的功能时,传统方案会引入一个统一时钟,通过分布式系统中的 master 节点广播出去给每一个 slaves 节点,当节点接收到这个统一时钟时,它们就记录下自己当前的状态即可。
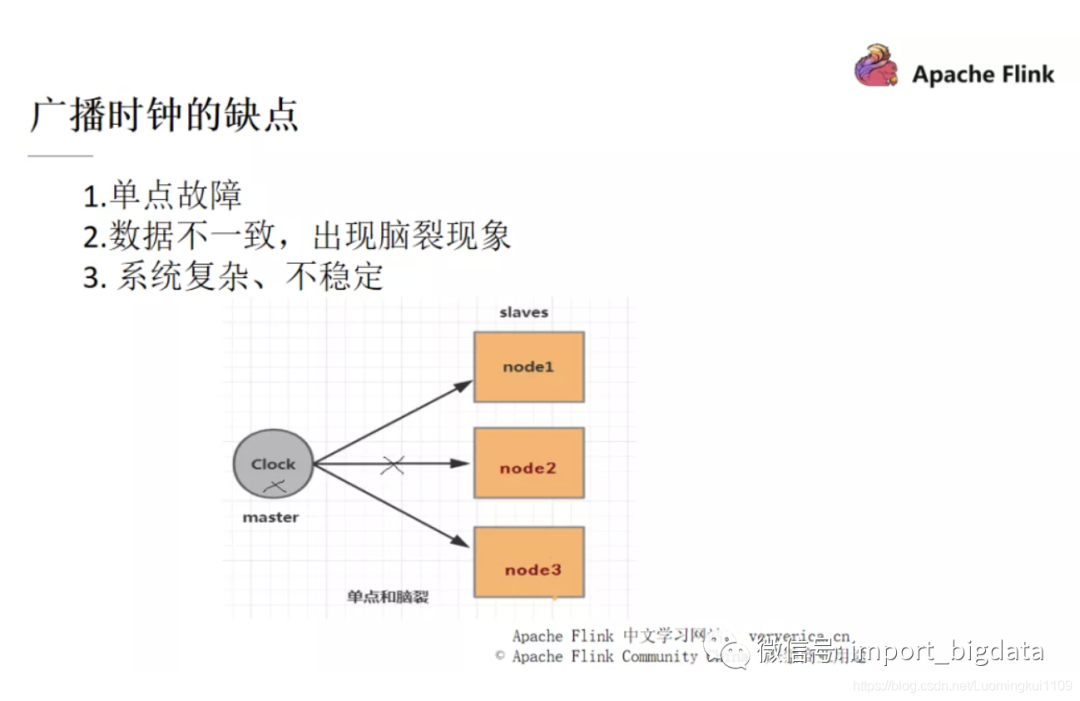
但是统一时钟的方式也存在一定的问题,某一个 node 进行的 GC 时间比较长,或者 master 与 slaves 的网络在当时存在波动而造成时钟的发送延迟或者发送失败,都会造成此 slave 和其它的机器出现数据不一致而最终导致脑裂的情况。如果我们想要解决这个问题,就需要对 master 和 slaves 做一个 HA(High Availability)。但是,一个系统越是复杂,就越不稳定且维护成本越高。
Flink 是将 checkpoint 都放进了一个名为 Barrier 的流。
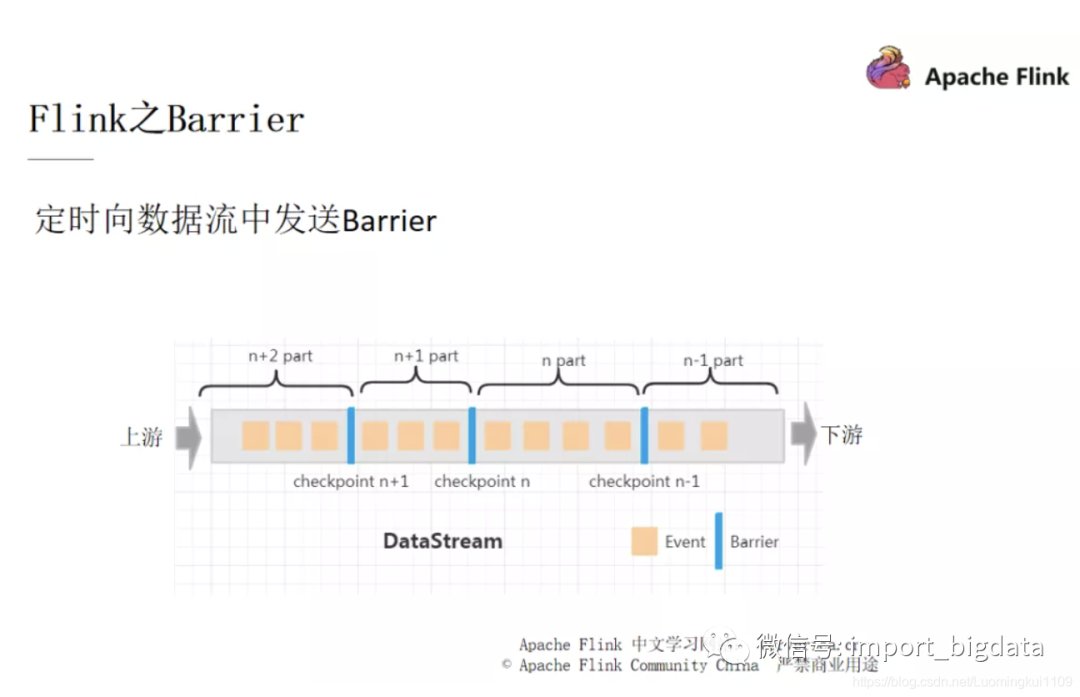
上图中就是一个 Barrier 的例子,从上游的第一个 Task 到下游的最后一个 Task,每次当 Task 经过图中蓝色的栅栏时,就会触发 save snapshot(快照)的功能。我们用一个例子来简单说明。
2.实例分析
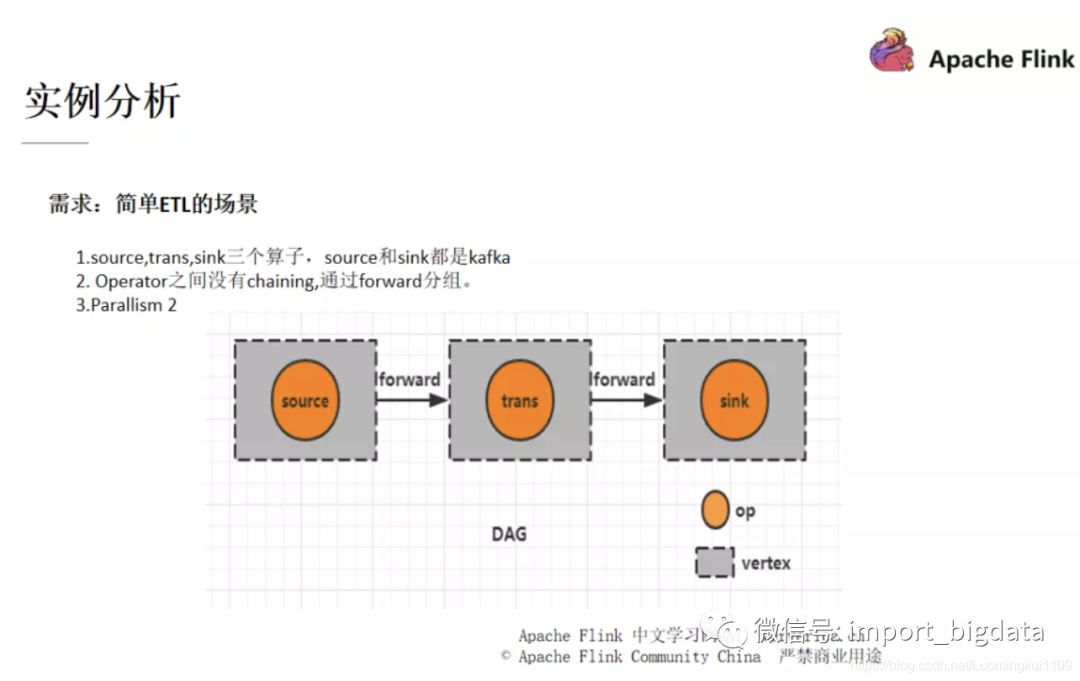
这是一个简单的 ETL 过程,首先我们把数据从 Kafka 中拿过来进行一个 trans 的转换操作,然后再发送到一个下游的 Kafka。
此时这个例子中没有进行 chaining 的调优。所以此时采用的是 forward strategy ,也就是 “一个 task 的输出只发送给一个 task 作为输入”,这样的方式,这样做也有一个好处就是如果两个 task 都在一个 JVM 中的话,那么就可以避免不必要的网络开销。
设置 Parallism 为 2,此时的 DAG 图如下:
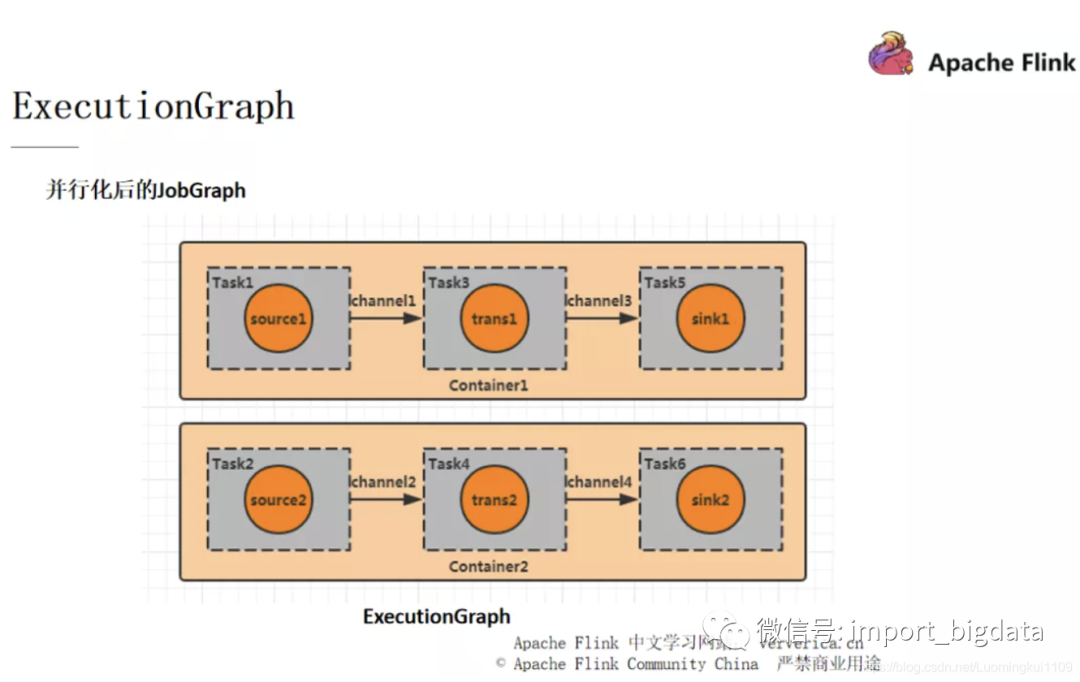
■ CK的分析过程
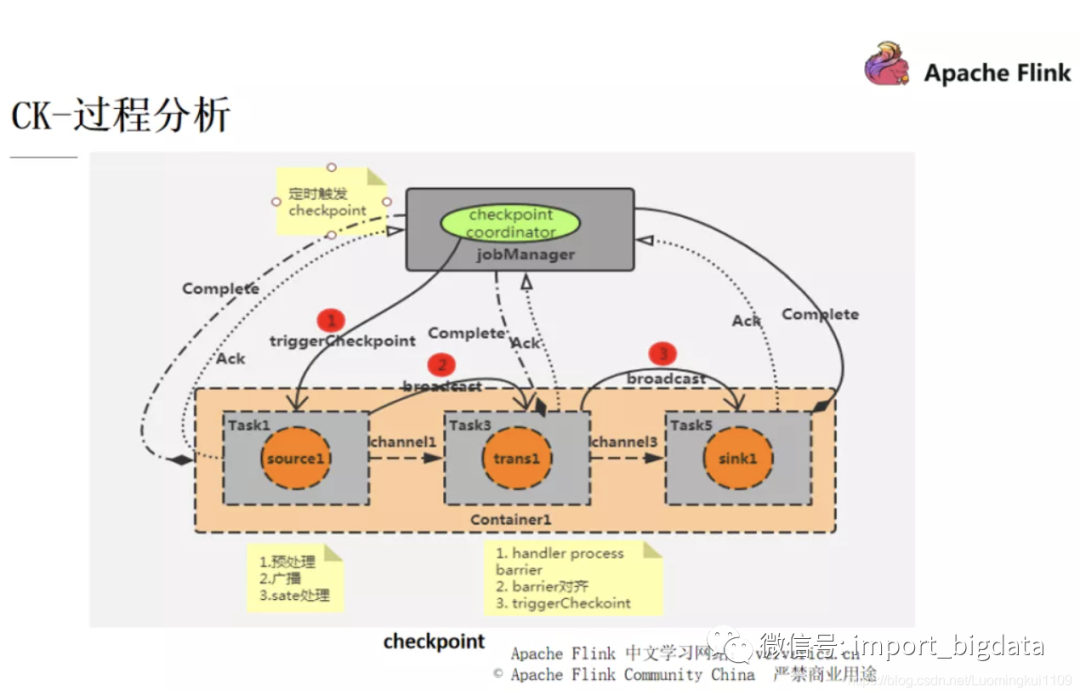
5 CK 的分析过程

每一个 Flink 作业都会有一个 JobManager ,JobManager 里面又会有一个 checkpoint coordinator 来管理整个 checkpoint 的过程,我们可以设置一个时间间隔让 checkpoint coordinator 将一个 checkpoint 的事件发送给每一个 Container 中的 source task,也就是第一个任务(对应并行图中的 task1,task2)。
当某个 Source 算子收到一个 Barrier 时,它会暂停自身的数据处理,然后将自己的当前 state 制作成 snapshot(快照),并保存到指定的持久化存储中,最后向 CheckpointCoordinator 异步发送一个 ack(Acknowledge character --- 确认字符),同时向自身所有下游算子广播该 Barrier 后恢复自身的数据处理。
每个算子按照上面不断制作 snapshot 并向下游广播,直到最后 Barrier 传递到 sink 算子,此时快照便制作完成。这时候需要注意的是,上游算子可能是多个数据源,对应多个 Barrier 需要全部到齐才一次性触发 checkpoint ,所以在遇到 checkpoint 时间较长的情况时,有可能是因为数据对齐需要耗费的时间比较长所造成的。
■ Snapshot & Recover
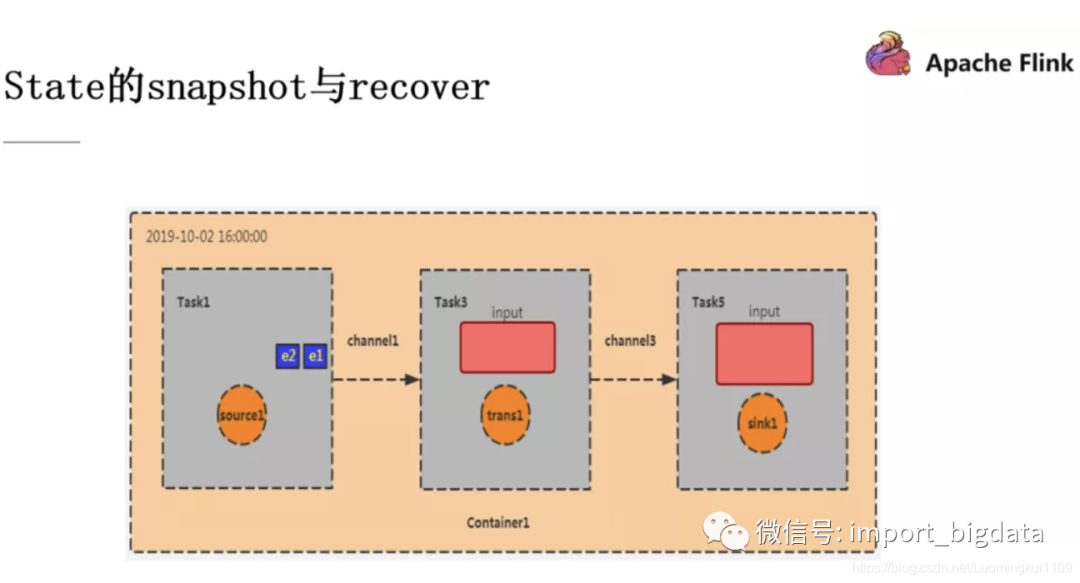
如图,这是我们的Container容器初始化的阶段,e1 和 e2 是刚从 Kafka 消费过来的数据,与此同时,CheckpointCoordinator 也往它发送了 Barrier。
此时 Task1 完成了它的 checkpoint 过程,效果就是记录下 offset 为2(e1,e2),然后把 Barrier 往下游的算子广播,Task3 的输入为 Task1 的输出,现在假设我的这个程序的功能是统计数据的条数,此时 Task3 的 checkpoint 效果就是就记录数据数为2(因为从 Task1 过来的数据就是 e1 和 e2 两条),之后再将 Barrier 往下广播,当此 Barrier 传递到 sink 算子,snapshot 就算是制作完成了。
此时 source 中还会源源不断的产生数据,并产生新的 checkpoint ,但是此时如果 Container 宕机重启就需要进行数据的恢复了。刚刚完成的 checkpoint 中 offset为2,count为2,那我们就按照这个 state 进行恢复。此时 Task1 会从 e3 开始消费,这就是 Recover 操作。
■ checkpoint 的注意事项

下面列举的3个注意要点都会影响到系统的吞吐,在实际开发过程中需要注意:
一下内容为Flink中文社区的总结,供大家参考:
Flink 作业的问题定位
1.问题定位口诀
“一压二查三指标,延迟吞吐是核心。时刻关注资源量 , 排查首先看GC。”
一压是指背压,遇到问题先看背压的情况,二查就是指 checkpoint ,对齐数据的时间是否很长,state 是否很大,这些都是和系统吞吐密切相关的,三指标就是指 Flink UI 那块的一些展示,我们的主要关注点其实就是延迟和吞吐,系统资源,还有就是 GC logs。
看反压 :通常最后一个被压高的 subTask 的下游就是 job 的瓶颈之一。
看 Checkpoint 时长 :Checkpoint 时长能在一定程度影响 job 的整体吞吐。
看核心指标 :指标是对一个任务性能精准判断的依据,延迟指标和吞吐则是其中最为关键的指标。
资源的使用率:提高资源的利用率是最终的目的。
■ 常见的性能问题

简单解释一下:
在关注背压的时候大家往往忽略了数据的序列化和反序列化,过程所造成的性能问题。
一些数据结构 ,比如 HashMap 和 HashSet 这种 key 需要经过 hash 计算的数据结构,在数据量大的时候使用 keyby 进行操作, 造成的性能影响是非常大的。
数据倾斜 是我们的经典问题,后面再进行展开。
如果我们的下游是 MySQL,HBase这种,我们都会进行一个批处理的操作,就是让数据存储到一个 buffer 里面,在达到某些条件的时候再进行发送,这样做的目的就是减少和外部5. 系统的交互,降低 网络开销 的成本。
频繁GC ,无论是 CMS 也好,G1也好,在进行 GC 的时候,都会停止整个作业的运行,GC 时间较长还会导致 JobManager 和 TaskManager 没有办法准时发送心跳,此时 JobManager 就会认为此 TaskManager 失联,它就会另外开启一个新的 TaskManager
窗口是一种可以把无限数据切割为有限数据块的手段。比如我们知道,使用滑动窗口的时候数据的重叠问题,size = 5min 虽然不属于大窗口的范畴,可是 step = 1s 代表1秒就要进行一次数据的处理,这样就会造成数据的重叠很高,数据量很大的问题。
2.Flink 作业调优

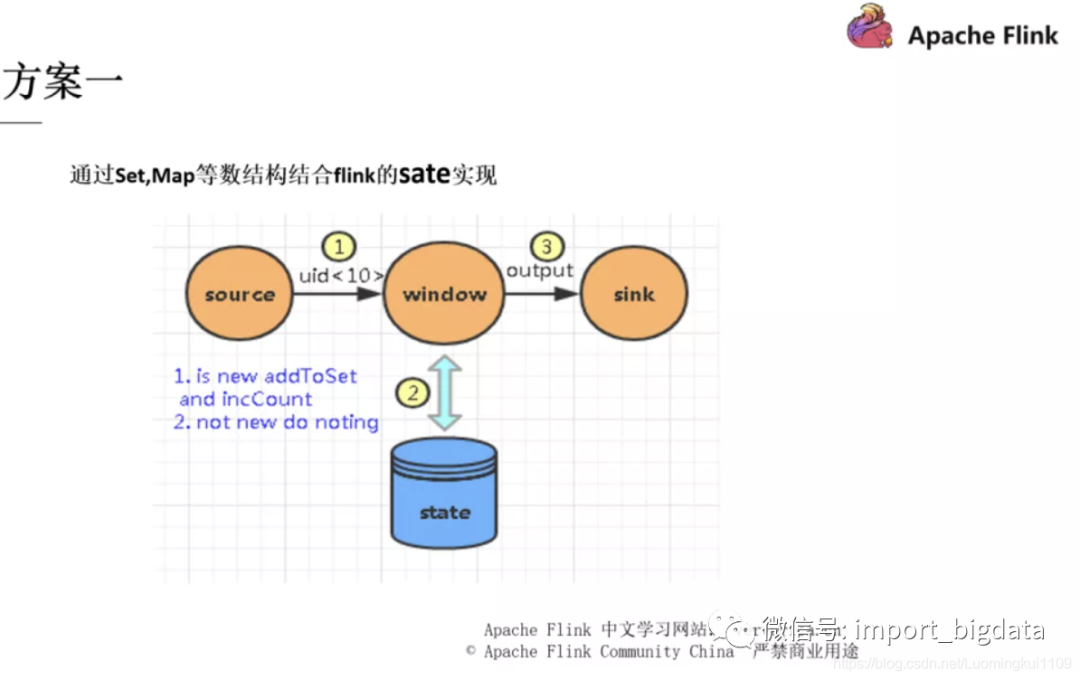
我们可以通过一些数据结构,比如 Set 或者 Map 来结合 Flink state 进行去重。但是这些去重方案会随着数据量不断增大,从而导致性能的急剧下降,比如刚刚我们分析过的 hash 冲突带来的写入性能问题,内存过大导致的 GC 问题,TaskManger 的失联问题。
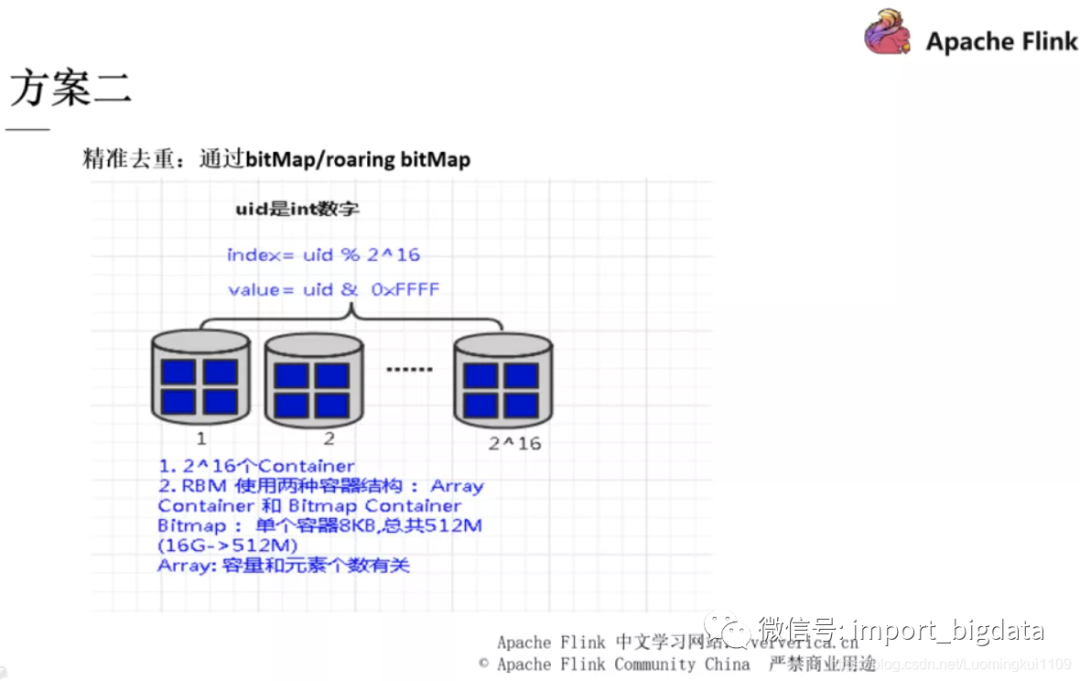
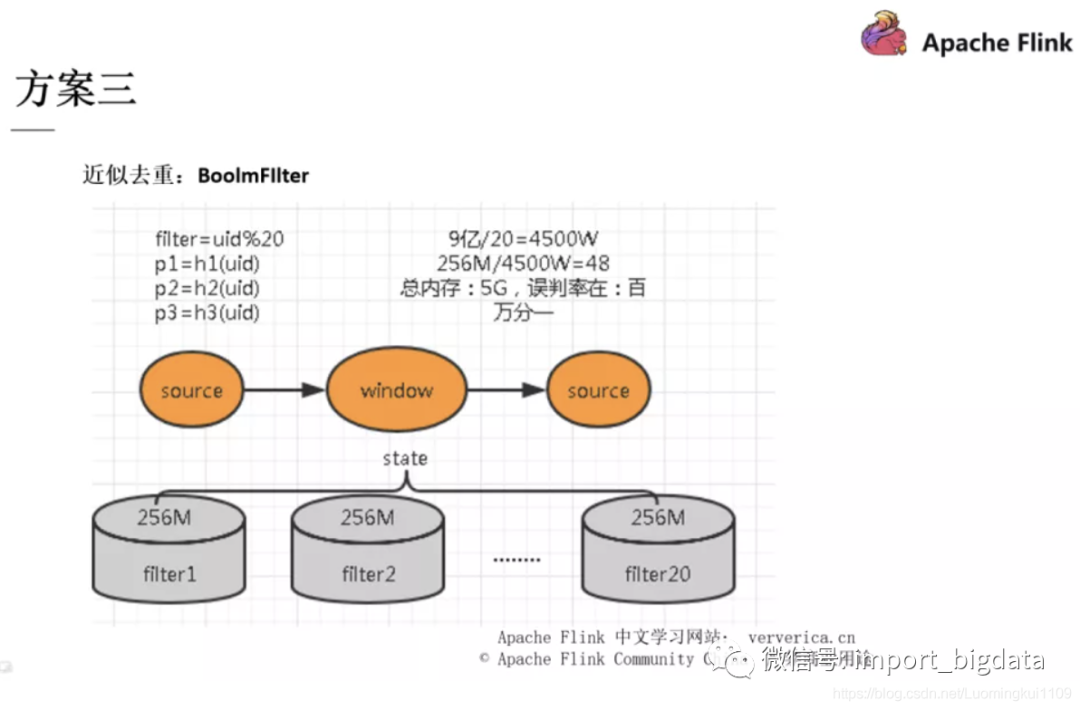


方案二和方案三也都是通过一些数据结构的手段去进行去重,有兴趣的同学可以自行下去了解,在这里不再展开。
■ 数据倾斜
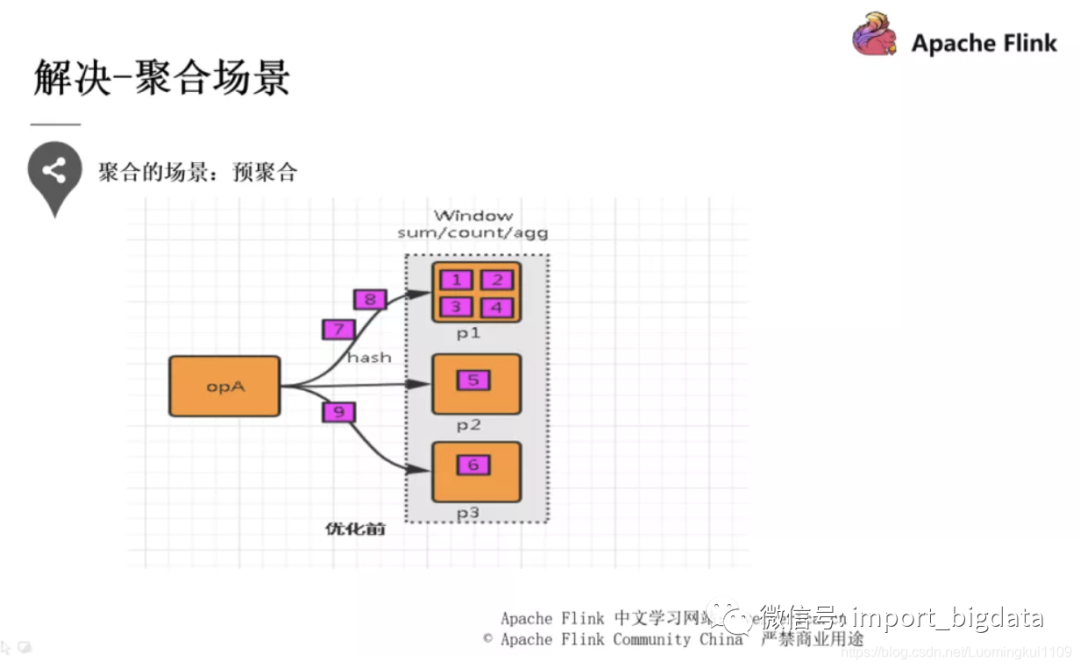
数据倾斜是大家都会遇到的高频问题,解决的方案也不少。
第一种场景是当我们的并发度设置的比分区数要低时,就会造成上面所说的消费不均匀的情况。

第二种提到的就是 key 分布不均匀的情况,可以通过添加随机前缀打散它们的分布,使得数据不会集中在几个 Task 中。
在每个节点本地对相同的 key 进行一次聚合操作,类似于 MapReduce 中的本地 combiner。map-side 预聚合之后,每个节点本地就只会有一条相同的 key,因为多条相同的 key 都被聚合起来了。其他节点在拉取所有节点上的相同 key 时,就会大大减少需要拉取的数据数量,从而也就减少了磁盘 IO 以及网络传输开销。
■ 内存调优

Flink 的内存结构刚刚我们已经提及到了,所以我们清楚,调优的方面主要是针对 非堆内存 Network buffer ,manager pool 和堆内存的调优,这些基本都是通过参数来进行控制的。
这些参数我们都需要结合自身的情况去进行调整,这里只给出一些建议。而且对于 ManagerBuffer 来说,Flink 的流式作业现在并没有过多使用到这部分的内存,所以我们都会设置得比较小,不超过0.3。
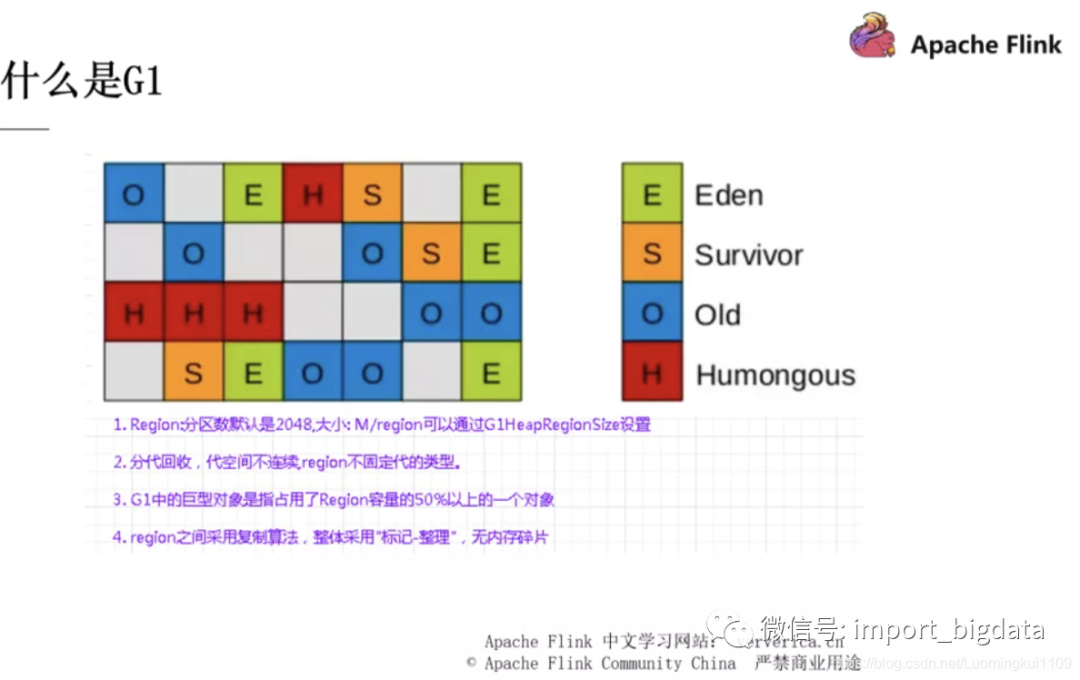
堆内存的调优是关于 JVM 方面的,主要就是将默认使用的垃圾回收器改为 G1 ,因为默认使用的 Parallel Scavenge 对于老年代的 GC 存在一个串行化的问题,它的 Full GC 耗时较长,下面是关于 G1 的一些介绍,网上资料也非常多,这里就不展开说明了。



end
Flink 从入门到精通 系列文章
基于 Apache Flink 的实时监控告警系统关于数据中台的深度思考与总结(干干货)日志收集Agent,阴暗潮湿的地底世界

公众号(zhisheng)里回复 面经、ClickHouse、ES、Flink、 Spring、Java、Kafka、监控 等关键字可以查看更多关键字对应的文章。点个赞+在看,少个 bug ????
这篇关于Flink性能调优小小总结的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






