本文主要是介绍微软如何打造数字零售力航母系列科普05 - Azure中计算机视觉的视觉指南,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Azure中计算机视觉的视觉指南
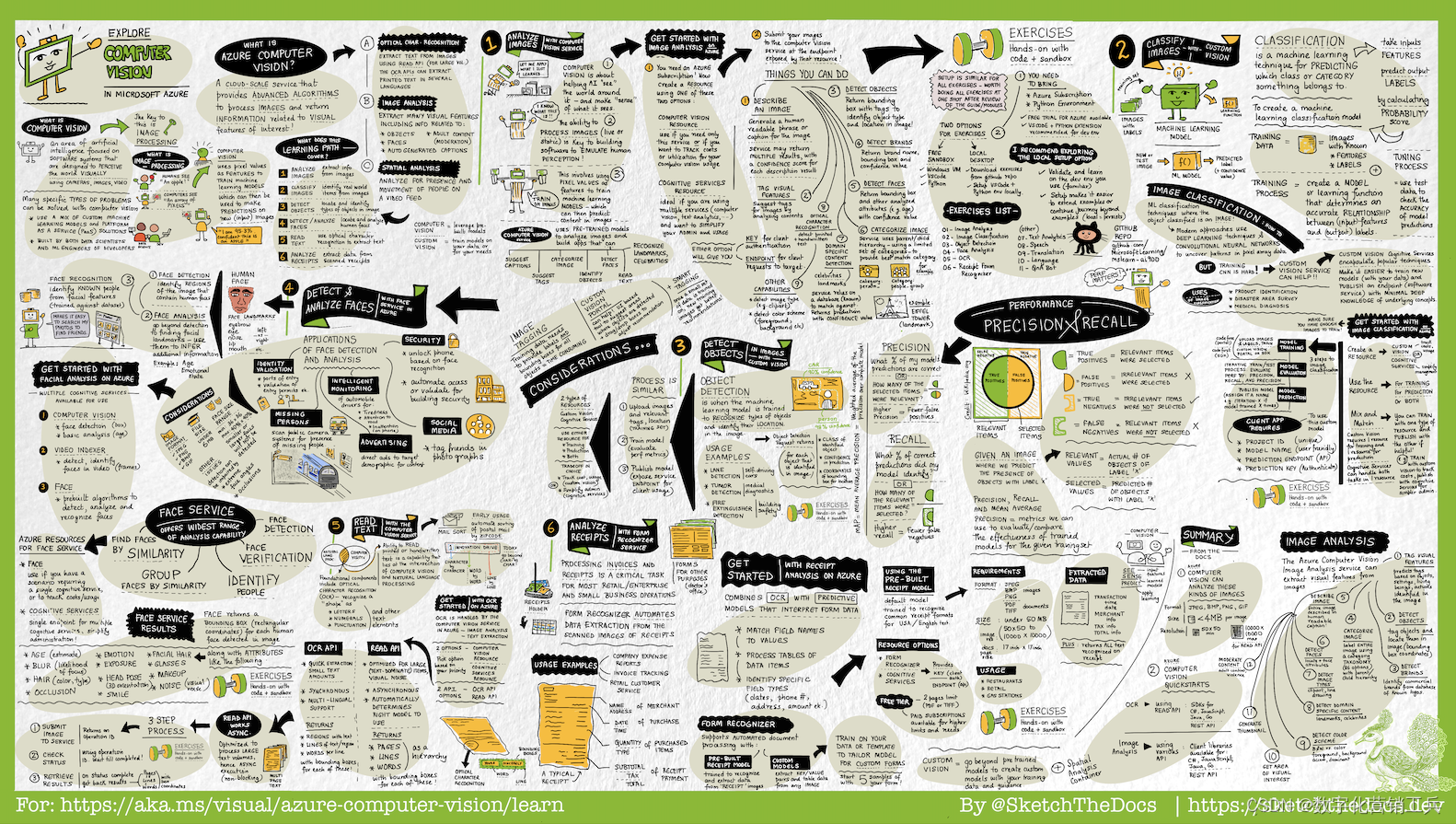
什么是计算机视觉?如何使用Microsoft Azure将计算机视觉功能集成到应用程序和工作流中?
作者:Nitya Narasimhan
编辑:数字化营销工兵
•11分钟阅读
什么是计算机视觉?如何使用Microsoft Azure将计算机视觉功能集成到应用程序和工作流中?在这篇文章中,我们将用一种专为视觉学习者设计的方法来解释这一点以及更多内容。
之前,我在ACG博客上分享了Azure基础知识的可视化介绍和Azure数据工厂的可视化指南。今天,我们将分解Microsoft Azure中的计算机视觉。
一、关于视觉指南
65%的人具有视觉学习能力,这意味着我们可以更快地从图像中吸收信息,从而可以更长时间地保留和回忆信息。视觉指南是高分辨率(海报大小)图像,使用文本和插图的组合来总结主题或内容资源。你可以把它们想象成草图(视觉笔记),在学习之旅开始时提供主题的“全局”视图,帮助你建立联系并确定模式,以提高你对所学知识的理解、回忆和保留。
想要发现其他视觉指南或收到新指南的通知吗?在Twitter上关注@SketchTheDocs。
二、什么是Microsoft Azure中的计算机视觉?
Azure中计算机视觉的视觉指南利用了两个主要资源:同名的Microsoft学习模块和认知服务下的计算机视觉的Microsoft文档页面。(高清原图下载地点)https://cloud-skills.dev/gallery/Azure-004-ComputerVisionInAzure.png![]() https://cloud-skills.dev/gallery/Azure-004-ComputerVisionInAzure.png本指南最适合用于预订您的学习旅程。在深入到用代码强化概念的实践练习之前,将其用作预读(用相关术语和工作流程引导你的头脑)。然后,将其用作审查后的资源,以测试您的回忆,并确定覆盖范围或理解方面的差距。或者把它打印出来挂在墙上——或者用作桌面壁纸。把它当作一个方便、可查阅的参考资料,可以补充你从其他来源学到的东西。现在让我们深入了解技术!
https://cloud-skills.dev/gallery/Azure-004-ComputerVisionInAzure.png本指南最适合用于预订您的学习旅程。在深入到用代码强化概念的实践练习之前,将其用作预读(用相关术语和工作流程引导你的头脑)。然后,将其用作审查后的资源,以测试您的回忆,并确定覆盖范围或理解方面的差距。或者把它打印出来挂在墙上——或者用作桌面壁纸。把它当作一个方便、可查阅的参考资料,可以补充你从其他来源学到的东西。现在让我们深入了解技术!
三、计算机视觉和Azure认知服务
1. 计算机视觉 (Computer Vision)
机器视觉是人工智能的一个领域,软件系统被设计成使用相机、图像和视频来视觉感知世界。
这里的挑战是,当人类和计算机看着同一个物体时,他们看到的东西是不同的。在人看到苹果(物体)的地方,机器看到一组像素值(图像颜色数据)。为了让机器更深入地了解图像数据所代表的内容,我们使用像素值作为数字特征来训练机器学习模型。
该模型的行为类似于模式检测功能,以概率的方式将计算机友好的特征(像素值)映射为人类友好的标签(对象、属性)。当我们将输入图像输入到该模型时,它现在可以预测具有相关置信度值的相关标签。从某种意义上说,我们已经教会了计算机像人类一样“看到”图像。
2. Azure Cognitive Service认知服务
是Azure基于云的服务的伞式产品类别,可帮助您将此类智能构建到应用程序或产品中。服务有客户端库SDK(用于Java和JavaScript等流行语言)和RESTAPI(用于其他语言),它们分为五个区域:视觉、语音、语言、决策和搜索。我们的重点是Vision,目前有三项服务:
1)Azure计算机视觉 – 使用预先存在的高级图像分析算法。
2)Azure 订制化视觉(Azure Custom Vision) - 可构建、改进和部署客户自己的图像分类器。
3)人脸 - 使用预先存在的高级人脸算法来检测和识别人脸。
3. Azure Computer Vision计算机视觉
是一种云级服务,提供对一组高级图像处理算法的访问。给定输入图像,服务可以返回与感兴趣的各种视觉特征相关的信息。根据您的主要目标,您可以通过以下功能探索此服务:
1)光学字符识别(OCR): 从图像中的打印或手写文本中提取信息。
2)图像分析(image analysis): 可以提取图像中的视觉特征,如标签、颜色、人脸、对象、徽标等。
3)空间分析(Space analysis): 从视频中了解人们在空间中的存在或运动。
四、Azure应用人工智能服务
快速浏览一下视觉指南,就会发现第六个应用场景——使用Form Recognizer分析收据。但Azure认知服务下没有列出此类服务。那么,它在Azure机器学习服务生态系统中的位置呢?
答案在于2021年5月在微软Build发布的一个新产品类别:应用人工智能服务。目标是通过构建Azure认知服务,同时将技术与特定任务的人工智能或针对特定用例定制的业务逻辑相结合,加快人工智能采用的价值实现时间。其结果是一个开箱即用的人工智能解决方案,可以解决常见的业务挑战,而不需要开发人员每次都以编程方式连接这些挑战。然而,由于他们构建在Azure认知服务上,开发人员总是可以选择从头开始创建类似的自定义解决方案。
目前,有六种应用人工智能服务选项,包括:
1. 表单识别器(Form Recognizer)-自动从图像和文档中提取和输入结构化数据。
2. 矩阵顾问(Metrics Advisor)– 在时间序列数据中执行数据自动化和异常检测。
3. 认知搜索(Cognitive Search)——具有内置人工智能功能的云级搜索,可搜索所有类型的内容。
4. 沉浸式读者(Immersive Reader)——包容性设计的工具,旨在提高所有学习者的阅读理解能力。
5. Bot服务(Bot Service)–使用预构建的组件快速创建可定制的对话体验。
6. 视频分析器(Video Analyzer) –构建由视频智能提供支持的自动化应用程序。
五、在Microsoft Azure中使用计算机视觉
视觉指南的结构与学习路径提供的六个示例(模块)相匹配。在本节中,我们将简要探讨每个应用程序,并为深入实践练习奠定基础。
1.使用计算机视觉服务分析图像
本模块主要关注计算机视觉服务的核心价值主张——图像分析。使用此服务端点,您的应用程序(客户端)提交一个图像,并获取其中各种视觉功能(和属性)的详细信息。客户端还可以执行一系列与图像处理相关的任务。你可以做的事情包括:
1)生成字幕(Generate caption):获取图像的人性化描述(对alt文本有用)
2)标记视觉特征(Tag visual feature):获取可以作为图像元数据的属性
3)检测对象(Detect objects):考虑标记,但带有已识别对象的位置(边界框坐标)
4)检测品牌(Detect brands):思考商业标识的专门对象检测(参考数据库)
5)检测人脸(Detect faces):考虑人脸的专门对象检测(预测年龄,识别名人)
6)对图像分类(Categorize images):使用父子层次结构对图像进行分类(有限的类别选项集)
7)检测特定于域的内容(Detect domain-specific content):支持的域模型包括地标和名人
8)光学字符识别(Optical Character Recognition):读取图像中打印或手写内容区域的文本
请注意,这是用于人脸的基本图像分析服务。对于高级人脸算法,您可以直接使用Azure认知服务的人脸服务端点,执行更复杂的任务,如检测情绪、头部姿势或口罩的存在。
作为开发人员,首先要创建相关的资源——您有两种选择。如果您计划仅使用图像分析功能或希望单独跟踪每个认知服务的成本和利用率,请使用Azure计算机视觉资源(目标)。如果您计划使用许多认知服务功能,并希望能够方便地将它们一起管理,请使用Azure认知服务(广泛)资源。有关图像分析使用的动手代码教程,请从这里开始
【数字化营销工兵:这是微软的免费培训和考核资源,有兴趣的读者可以自行学习,每次学习时间一般都在45分钟以内,可以参加考试和拿到相关证书 】Exercise - Analyze images in Vision Studio - Training | Microsoft LearnExercise - Analyze images in Vision Studio![]() https://learn.microsoft.com/en-us/training/modules/analyze-images-computer-vision/4-exercise?WT.mc_id=mobile-30244-ninarasi
https://learn.microsoft.com/en-us/training/modules/analyze-images-computer-vision/4-exercise?WT.mc_id=mobile-30244-ninarasi
2.使用自定义视觉服务对图像进行分类
本模块重点介绍自定义视觉服务的核心价值主张——图像分类。这是一种学习技术,您可以向机器提供训练数据(图像和相关类),并训练它检测和揭示将数字特征(像素数据)与人类概念(类标签)联系起来的模式。可以发布经过训练的模型以向客户端公开服务端点。使用这项服务,客户端和发布一张图片,并返回一个预测的类(带有相关的置信度分数)。
使用自定义视觉服务,您可以通过以下两种方式之一上传训练数据来训练图像分类器:使用门户(基于无代码UI的工作流)或使用SDK或REST API(代码优先方法)。使用包括两个步骤:训练(创建模型)和预测(发布模型)。和以前一样,您可以将专用的自定义视觉服务资源或通用的Azure认知服务资源用于其中一个阶段,也可以同时用于这两个阶段。您甚至可以根据需要混合搭配它们。有关图像分类使用的动手代码教程,请从这里开始。
【数字化营销工兵:这是微软的免费培训和考核资源,有兴趣的读者可以自行学习,每次学习时间一般都在45分钟以内,可以参加考试和拿到相关证书】Classify images with Azure AI Custom Vision - Training | Microsoft LearnExplore Azure AI Custom Vision's classification capabilities.![]() https://learn.microsoft.com/en-us/training/modules/classify-images-custom-vision/?WT.mc_id=mobile-30244-ninarasi
https://learn.microsoft.com/en-us/training/modules/classify-images-custom-vision/?WT.mc_id=mobile-30244-ninarasi
3.使用自定义视觉服务检测对象
本模块的重点是创建用于对象检测的自定义模型。通常,这需要深度学习技术的高级知识和大型训练数据集,但使用自定义视觉服务可以让我们在没有数据科学专业知识的情况下用更少的图像实现这一点。与上面前面的自定义视觉服务示例中所采取的步骤类似,这包括准备训练图像集,将数据上传到Azure(通过门户或使用SDK),训练和验证模型,然后将其发布到服务端点供客户端使用。
关键的区别在于,对象检测涉及识别图像中对象的位置及其分类。这意味着需要准备训练集(图像)来识别对象的边界框(坐标),这可能很耗时。使用Custom Vision,您可以将图像上传到门户网站,并获得检测到物体的区域的建议;只需拖动或调整边界框区域即可提高精度。一旦你训练了一套初始设置,就可以使用Azure计算机视觉服务尝试智能标记方法,为其他设置建议标记和边界框。有关对象检测使用的动手代码教程,请从这里开始。
【数字化营销工兵:这是微软的免费培训和考核资源,有兴趣的读者可以自行学习,每次学习时间一般都在45分钟以内,可以参加考试和拿到相关证书。 】Detect objects in images with Azure AI Custom Vision - Training | Microsoft LearnLearn how to use Azure AI Custom Vision to create an object detection solution using the Custom Vision studio.![]() https://learn.microsoft.com/en-us/training/modules/detect-objects-images-custom-vision/?WT.mc_id=mobile-30244-ninarasi
https://learn.microsoft.com/en-us/training/modules/detect-objects-images-custom-vision/?WT.mc_id=mobile-30244-ninarasi
4.使用人脸服务检测和分析人脸
本模块侧重于使用高级算法进行面部分析,这些算法超出了Azure计算机视觉中获得的基本属性。这就像物体检测的特殊情况,感兴趣的物体是人脸。使用人脸算法,您可以执行人脸检测(返回包含人脸的图像区域)、人脸分析(返回面部标志,如鼻子、眼睛、眉毛、嘴唇等的位置)和人脸识别(例如基于人脸的身份验证应用程序)。
Azure认知服务为检测和分析人脸提供了不同的选项——用于基本分析(年龄)的计算机视觉、用于视频内容中人脸分析的视频索引器,以及用于最广泛人脸分析功能的人脸。
人脸服务可以检测、识别和验证人脸。它可以找到其他相似的人脸,或者根据相似性对人脸进行分组。人脸服务分析返回属性,包括年龄、情绪、面部毛发、眼镜、头发、头部姿势、化妆、遮挡以及检测到的人脸的图像模糊和曝光。有关面部分析使用的动手代码教程,请从这里开始。
【数字化营销工兵:这是微软的免费培训和考核资源,有兴趣的读者可以自行学习,每次学习时间一般都在45分钟以内,可以参加考试和拿到相关证书。https://learn.microsoft.com/en-us/training/modules/detect-analyze-faces/4-exercise?WT.mc_id=mobile-30244-ninarasi ![]() https://learn.microsoft.com/en-us/training/modules/detect-analyze-faces/4-exercise?WT.mc_id=mobile-30244-ninarasi%20%E3%80%91
https://learn.microsoft.com/en-us/training/modules/detect-analyze-faces/4-exercise?WT.mc_id=mobile-30244-ninarasi%20%E3%80%91
5.使用计算机视觉服务阅读文本
本模块侧重于Azure计算机视觉服务的光学字符识别功能,以读取图像中的打印和手写文本。根据所涉及的文本量,可以使用两种API:OCR API和Read API。
【数字化营销工兵:更多资源,请参考: OCR - Optical Character Recognition - Azure AI services | Microsoft LearnLearn how the optical character recognition (OCR) services extract print and handwritten text from images and documents in global languages.![]() https://learn.microsoft.com/en-us/azure/ai-services/computer-vision/overview-ocr?WT.mc_id=mobile-30244-ninarasi
https://learn.microsoft.com/en-us/azure/ai-services/computer-vision/overview-ocr?WT.mc_id=mobile-30244-ninarasi
6.使用表单识别器服务分析收据
该模块侧重于一种更具应用性的人工智能解决方案,该解决方案将OCR文本读取功能与特定领域的预测模型相结合,用于解释表单数据,实现智能表单处理和收据和发票等文档的自动化工作流程。
表单识别器提供预构建的收据模型和对自定义模型的支持。预构建的模型经过训练,可以识别在美国地区流行的常见的基于英语的收据格式。它提取并返回交易的时间/日期、商户信息、税款和支付总额等属性。相比之下,自定义模型识别并提取分析文档中的键/值对和表数据。它可以使用您自己的数据进行训练,定制返回的属性以匹配表单的结构和上下文,基本训练至少需要5个表单样本。有关收据分析使用的动手代码教程,请从这里开始.
【数字化营销工兵:更多资源,请参考】Exercise - Extract from data in Document Intelligence Studio - Training | Microsoft LearnExercise - Extract from data in Document Intelligence Studio![]() https://learn.microsoft.com/en-us/training/modules/analyze-receipts-form-recognizer/4-exercise?WT.mc_id=mobile-30244-ninarasi
https://learn.microsoft.com/en-us/training/modules/analyze-receipts-form-recognizer/4-exercise?WT.mc_id=mobile-30244-ninarasi
六、总结和下一步行动
这是对六个模块的学习路径和可下载的视觉指南的快速回顾,该指南提供了一个“全局”快速参考,以补充您在Azure中进入计算机视觉的学习之旅中的实践练习。想继续前进吗?以下是可以提供帮助的资源:
1. Microsoft Learn: 相关文档、学习路径和模块的不断发展的集合。
2. Microsoft Doc: 认知服务、计算机视觉、自定义视觉、人脸|应用人工智能
3. 视觉指南: 访问@SketchTheDocs了解新闻,访问Cloud-Skills.dev和SketchTheDocs了解内容。
此外,请查看以下ACG课程和实践实验室:
1. 课程:Azure AI组件和服务A Cloud Guru - Get Cloud CertifiedAdvance your career with A Cloud Guru. Courses, certifications, training, and real hands on labs in AWS, Azure, Google Cloud, and beyond.![]() https://www.pluralsight.com/cloud-guru 2. 课程:Azure机器学习工作室入门 Getting Started with Azure Machine Learning Studio
https://www.pluralsight.com/cloud-guru 2. 课程:Azure机器学习工作室入门 Getting Started with Azure Machine Learning Studio![]() https://www.pluralsight.com/cloud-guru/courses/getting-started-with-azure-machine-learning-studio3. 实践实验室:使用Azure门户创建认知服务资源Creating a Cognitive Services Resource Using the Azure Portal
https://www.pluralsight.com/cloud-guru/courses/getting-started-with-azure-machine-learning-studio3. 实践实验室:使用Azure门户创建认知服务资源Creating a Cognitive Services Resource Using the Azure Portal![]() https://www.pluralsight.com/cloud-guru/labs/azure/creating-a-cognitive-services-resource-using-the-azure-portal
https://www.pluralsight.com/cloud-guru/labs/azure/creating-a-cognitive-services-resource-using-the-azure-portal
七、关于作者
Nitya Narasimhan是计算机工程博士,拥有20多年的软件研发经验,涵盖分布式和泛在计算、移动和web应用程序开发。她目前是微软开发者关系团队的云倡导者,在那里她将时间花在移动和跨平台开发(Azure和Microsoft Surface Duo)、视觉故事讲述以及支持我们令人惊叹的开发者社区上。她是ACG的21位Azure建设者之一。
八、推荐阅读
数字零售力航母-看微软如何重塑媒体-CSDN博客文章浏览阅读935次,点赞29次,收藏25次。数字零售力航母-看微软如何重塑媒体?从2024全美广播协会展会看微软如何整合营销媒体AI技术和AI平台公司。 微软打造的“数据+技术+云”平台将为各个参与者(stakeholder)提供各种合作的机会和可能,互联网会产生更多的合作模式和技术组合。再次巩固数字化营销工兵的认知–任何一个人,一个组织,必须成为某个细分领域的专家,就像数据的颗粒度那样,越细,越能反映事物的独一特征(unique feature)https://blog.csdn.net/weixin_45278215/article/details/137907809?spm=1001.2014.3001.5502
这篇关于微软如何打造数字零售力航母系列科普05 - Azure中计算机视觉的视觉指南的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




