本文主要是介绍CSAPP Cache实验,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
程序A
#include <sys/time.h>
#include <unistd.h>
#include <stdio.h>
main(int argc,char *argv[])
{
float *a,*b,*c, temp;
long int i, j, k, size, m;
struct timeval time1,time2;
if(argc<2) {
printf("\n\tUsage:%s <Row of squarematrix>\n",argv[0]);
exit(-1);
} //if
size = atoi(argv[1]);
m = size*size;
a = (float*)malloc(sizeof(float)*m);
b = (float*)malloc(sizeof(float)*m);
c = (float*)malloc(sizeof(float)*m);
for(i=0;i<size;i++)
for(j=0;j<size;j++){
a[i*size+j] = (float)(rand()%1000/100.0);
b[i*size+j] = (float)(rand()%1000/100.0);
}
gettimeofday(&time1,NULL);
for(i=0;i<size;i++)
for(j=0;j<size;j++)
{
c[i*size+j] = 0;
for (k=0;k<size;k++)
c[i*size+j] += a[i*size+k]*b[k*size+j];
}
gettimeofday(&time2,NULL);
time2.tv_sec-=time1.tv_sec;
time2.tv_usec-=time1.tv_usec;
if (time2.tv_usec<0L){
time2.tv_usec+=1000000L;
time2.tv_sec-=1;
}
printf("Executiontime=%ld.%6ldseconds\n",time2.tv_sec,time2.tv_usec);
} //for
return(0);
}//main
#include <sys/time.h>
#include <unistd.h>
#include <stdio.h>
main (int argc,char *argv[])
{
float *a,*b,*c,temp;
long int i,j,k,size,m;
struct timeval time1,time2;
if (argc<2)
{
printf("\n\tUsage:%s <Row of squarematrix>\n",argv[0]);
exit(-1);
}
size=atoi(argv[1]);
m=size*size;
a=(float*)malloc(sizeof(float)*m);
b=(float*)malloc(sizeof(float)*m);
c=(float*)malloc(sizeof(float)*m);
for(i=0;i<size;i++)
for(j=0;j<size;j++)
{
a[i*size+j]=(float)(rand()%1000/100.0);
c[i*size+j]=(float)(rand()%1000/100.0);
}
gettimeofday(&time1,NULL);
for (i=0;i<size;i++)
for (j=0;j<size;j++)
{
b[i*size+j] =c[j*size+i];
for(i=0;i<size;i++)
for(j=0;j<size;j++)
{
c[i*size+j]= 0;
for(k=0;k<size;k++)
c[i*size+j]+= a[i*size+k] * b[j*size+k];
} //for
gettimeofday(&time2,NULL);
time2.tv_sec-=time1.tv_sec;
time2.tv_usec-=time1.tv_usec;
if(time2.tv_usec<0L)
{
time2.tv_usec+=1000000L;
time2.tv_sec-=1;
}
printf("Executiontime=%ld.%6ldseconds\n",time2.tv_sec,time2.tv_usec);
}//for
return(0);
}
四、实验结果及分析
1、 用C语言实现矩阵(方阵)乘积一般算法(程序A),填写下表:
| 矩阵大小 | 100 | 500 | 1000 | 1500 | 2000 | 2500 | 3000 |
| 一般算法执行时间 | 0. 4761 | 0.545355 | 4.501892 | 37.527864 | 81.996566 | 167.274540 | 302.754285 |
分析:
1) 由图下图1可得到上表的结果,程序的主要代码如下黄色背景,对二维数组b是跳跃的,类似下图2的访问顺序,这样导致了程序的空间局部性很差:
for(j=0;j<size;j++)
{
c[i*size+j] = 0;
for(k=0;k<size;k++)
c[i*size+j] +=a[i*size+k]*b[k*size+j];
}
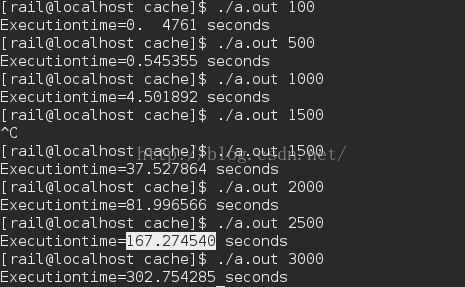
图1
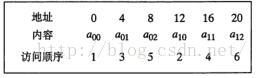
图2
2) 以下图3说明为什么空间局部性差:
图3
2、 程序B是基于Cache的矩阵(方阵)乘积优化算法,填写下表:
| 矩阵大小 | 100 | 500 | 1000 | 1500 | 2000 | 2500 | 3000 |
| 优化算法执行时间 | 0.4831 | 0.512749 | 4.61557 | 13.537300 | 33.366774 | 63.980002 | 112.299316 |
分析:
1) 由下图4可以得到上表的数据,由标黄的主要代码可知,优化后的代码访问数组b的顺序类似下图5,这样相对程序A对cache的命中率大大得到了提高:
for(j=0;j<size;j++)
{
c[i*size+j] = 0;
for (k=0;k<size;k++)
c[i*size+j] += a[i*size+k] *b[j*size+k];
} //for
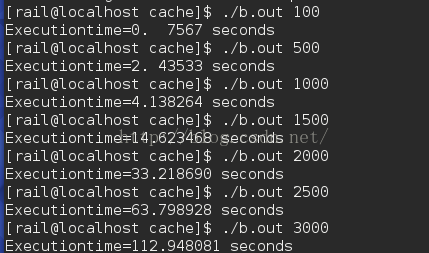
图4

图5
2) 同样由图6说明为什么程序B的空间局部性好:
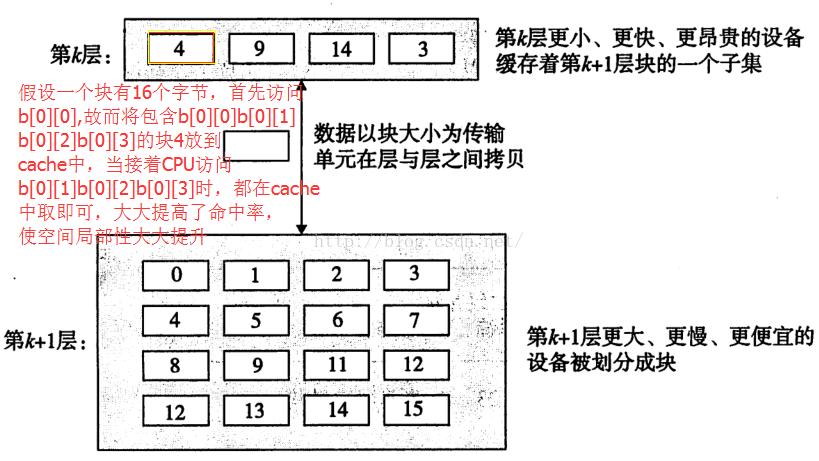
图6
3) 图7为程序A和程序B的性能对比,可以看出,当size越来越大时,cache的对性能的影响越明显:

图7
3、 优化后的加速比(speedup)
| 矩阵大小 | 100 | 500 | 1000 | 1500 | 2000 | 2500 | 3000 | |
| 加速比 |
| 1.063591 | 0.975371 | 2.772182 | 2.457432 | 2.614482 | 2.695958 |
加速比定义:加速比=优化前系统耗时/优化后系统耗时;
所谓加速比,就是优化前的耗时与优化后耗时的比值。加速比越高,表明优化效果越明显。
分析:由下图8知,总体上来说,当size越大时,对程序B的优化效果越好,即命中率更高,局部空间性更好。
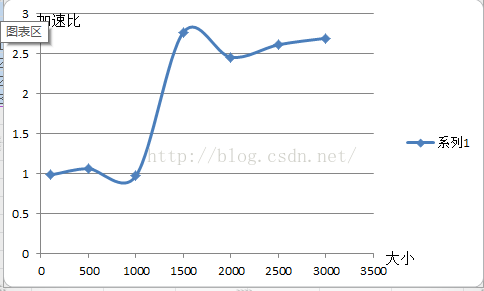
图8
五、实验总结与体会
1、通过该实验,对cache的原理有了感性上的一点认识,即因为cpu和主存的速度上的差距,故而在CPU和主存之间设计了一级或多级的cache,cache为SRAM(静态随机存储器),因为cache时钟周期明显高于主存,故而加快了计算机的速度;
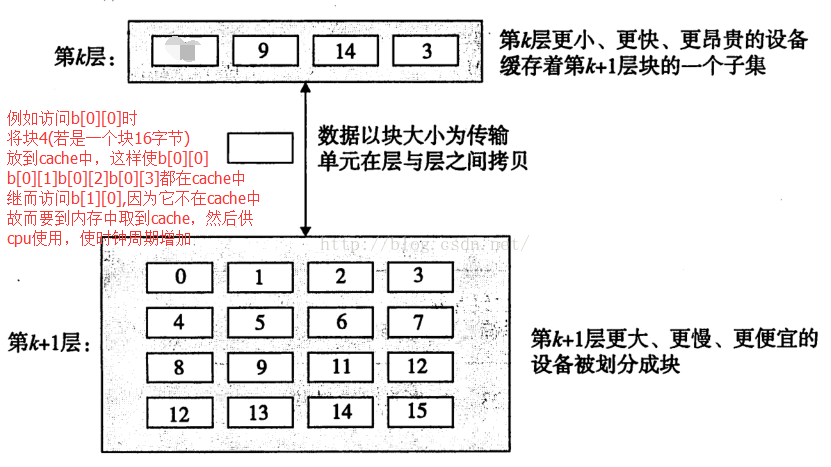
2、Cache和主存或cache和cache之间的数据传输是以块为最小单位,块里面保存着多个相邻地址的数据。例如:程序中存在一个数组int型b[4][4],块的大小为16字节,当第一次使用该数组时,例如使用了b[0][0],会将主存中b[0][0]所在块放到cache中,因为块保存着主存相邻的数据,故而它里面很可能包含着b[0][1]、b[0][2]、b[0][3],如果按b[0][1]、b[0][2]、b[0][3]顺序调用数组,这样就提高了cache的命中率,减少了时钟周期。如果按照b[1][0]、b[2][0]、b[3][0]的顺序访问,则因为cache的空间有限,当引入b[1][0]、b[2][0]、b[3][0]所在块时,可能将b[0][0]所在的块替换了,此时CPU再使用b[0][1]时,则需要重新从主存中拷贝b[0][1]所在块,这使cache的命中率下降了,增加了时间周期;
3、我们以后写程序时,要考虑到cache的原理,这样我们的写的程序执行起来才更高效。
这篇关于CSAPP Cache实验的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









