本文主要是介绍MOT论文笔记《Towards Real-Time Multi-Object Tracking》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

论文地址:https://arxiv.org/pdf/1909.12605v1.pdf
代码地址:https://github.com/Zhongdao/Towards-Realtime-MOT
Abstract
当前的多目标跟踪(MOT)系统通常遵循 “tracking-by-detection”的方式,主要由两部分组成(1)检测模型----用于目标定位(2)appearance embedding模型----用于数据关联。分别执行两个模型会降低时间效率。现有的关于实时MOT的研究工作通常集中在关联步骤上,因此它们本质上是实时关联方法,而不是实时MOT系统。这篇论文提出了一种MOT系统,将appearance embedding 模型合并到单个检测器中,以便该模型可以同时输出检测结果和相应的embedding。这样,该系统被表述为一个多任务学习问题:存在多个任务,即锚点分类,边界框回归和嵌入学习; 并自动对单个损失进行加权。这项工作报告了第一个(近)实时MOT系统,其运行速度取决于输入分辨率,可以达到18.8至24.1 FPS。同时,其跟踪准确性可与采用独立检测和嵌入(SDE)学习的最新跟踪器相媲美(64.4% MOTA v.s. 66.1% MOTA on MOT-16 challenge).
Introduction
(Milan et al. 2016; Yu et al. 2016; Choi 2015)将MOT分解为两个步骤:1)检测步骤,目标在单个视频帧已本地化; 2)关联步骤,在其中分配检测到的目标并将其连接到现有轨迹。 这意味着系统至少需要两个计算密集型组件:a detector and an embedding (re-ID) model。为了方便起见,我们将这些方法称为“分离的检测和嵌入”方法(Separate Detection and Embedding (SDE)。因此,总推理时间大致是两个分量的总和,并且将随着目标数量的增加而增加。
为了节省计算,一个可行的想法是将检测器和嵌入模型集成到单个网络中。因此,这两个任务可以共享同一组低级特征,并且避免了重新计算。联合检测器和嵌入学习的一种选择是采用Faster R-CNN,具体来说,第一阶段使用RPN网络,与Faster R-CNN保持相同,并输出检测到的边界框。 第二阶段,Fast R-CNN 通过用度量学习监督取代分类监督来转化为嵌入学习模型(Xiao et al. 2017;Voigtlaender et al. 2019)。尽管节省了一些计算,但由于采用了两阶段设计,因此该方法的速度仍然受到限制,并且通常以不到10FPS的速度运行,这远远超出了实时要求。此外,第二阶段的运行时间也像SDE方法一样随着目标数量的增加而增加。
本文致力于提高MOT系统的效率。 我们介绍了一种在单个深度网络中联合学习检测器和嵌入模型(JDE)的早期尝试。换句话说,提出的JDE使用单个网络来同时输出检测结果和检测框的相应外观嵌入。相比之下,SDE方法和两阶段方法分别以重新采样的像素(边界框)和特征图为特征。边界框和特征图都被馈入单独的re-ID模型中以提取外观特征。

图1简要说明了SDE方法,两阶段方法和的JDE之间的区别。我们的方法几乎是实时的,但几乎与SDE方法一样准确。 例如,在MOT-16测试上的MOTA = 64.4%,我们获得了18.8 FPS的运行时间。相比之下,在MOT-16测试上,Faster R-CNN + QAN 方法仅以<6 FPS进行,MOTA = 66.1%。
为了构建高效,准确的联合学习框架,我们探索并设计以下基本方面:训练数据,网络体系结构,学习目标,优化策略和验证指标。
首先,我们收集了六个关于行人检测和人员搜索的公开可用数据集,以形成统一的大规模多标签数据集。在这个统一的数据集中,所有行人边界框都被标记,一部分行人身份ID被标记。
其次,我们选择特征金字塔网络(FPN)(Lin et al.2017)作为我们的基本架构,并讨论网络使用哪种损失函数可以达到最佳嵌入。然后,我们将训练过程建模为具有锚分类,框回归和嵌入学习的多任务学习问题。为了平衡每个任务的重要性,我们采用了( task-dependent uncertainty)任务相关的不确定性(Kendall, Gal, and Cipolla 2018)来动态加权异构损失。
最后,我们采用以下评估指标。 平均精度(AP)用于评估检测器的性能。采用FAR)和(TAR)来评估嵌入的质量。总体MOT准确性由CLEAR指标(Bernardin和Stiefel-hagen 2008)评估,最重要的是MOTA指标。 本文还为联合学习检测和嵌入任务提供了一系列新的设置和基线,我们认为这将有助于对实时MOT的研究。
Joint Learning of Detection and Embedding Problem Settings
JDE的目的是在单次前向传播中同时输出目标的位置和外观嵌入。假定有一个数据集{I,B,Y},I表示图像帧,B表示此帧中k个目标的边界框注释,y表示部分身份标签标注,其中-1表示目标没有身份标签。 JDE的目的是输出预测的边界框B和外观嵌入F,其中F中的D表示嵌入的维度。应满足以下两个目标。

第一个目标要求模型能够准确检测目标。
第二个目标是要求外观嵌入具有以下特性。连续帧中相同身份的检测框之间的距离应小于不同身份之间的距离。距离度量d(·)可以是欧式距离或余弦距离。 从技术上讲,如果两个目标都得到满足,那么即使是简单的关联策略,例如匈牙利算法,也会产生良好的跟踪结果。
Architecture Overview
我们采用特征金字塔网络(FPN)的体系结构(Lin et al.2017)。FPN从多个尺度进行预测,从而在目标尺度变化很大的行人检测中带来了改进。 图2简要显示了JDE中使用的神经体系结构。

输入视频帧首先经过骨干网络分别获得三个尺度的特征图(1/32、1/16、 1/8的下采样率),然后,通过 skip connection 对具有最小大小(也是语义上最强的特征)的特征图进行上采样并与第二小的比例尺上的特征图相融合,其他比例尺也是如此。最后,将预测头添加到所有三个比例的融合特征图上。预测头由几个堆叠的卷积层组成,并输出一个大小为(6A + D)×H×W的密集预测图,其中A是分配给该比例的锚模板的数量,D是嵌入的维度 。
密集预测图分为三个部分(任务):
1.检测框的分类结果:2A×H×W
2.检测框的回归系数:4A×H×W
3.密集嵌入图:D×H×W
Learning to Detect
检测分支类似于标准RPN,这里做出了两个修改。首先,我们根据数量,比例和长宽比重新设计锚,以适应目标,即本例中的行人。根据共同的先验,所有锚点的长宽比均设置为1:3。锚点模板的数量设置为12,使得每个尺度的A = 4,锚点的尺度(宽度)范围为11-512。其次,我们注意到为用于前景/背景分配的双重阈值选择适当的值很重要。通过可视化,我们确定IOU> 0.5 w.r.t. ground truth 大致确保了前景,这与通用对象检测中的通用设置一致。另一方面,IOU <0.4 w.r.t.的框 在我们的案例中,ground truth 应被视为背景,而不是一般情况下的0.3。我们的初步实验表明,这些阈值可有效抑制虚假误报,这种警报通常发生在重度遮挡下。
检测的学习目标具有两个损失函数,即前景/背景分类损失Lα和边界框回归损失Lβ。 Lα被公式化为交叉熵损失,Lβ被公式化为平滑L1损失。 回归目标的编码方式与(Ren et al.2015)相同。
Learning Appearance Embeddings
第二个目标是度量学习问题,即学习一个嵌入空间,其中相同身份的实例彼此靠近,而不同身份的实例相距甚远。为了实现这一目标,有效的解决方案是使用triplet loss (Schroff, Kalenichenko, and Philbin 2015),在以前的MOT工作中也使用了triplet loss(Voigtlaender等人2019)。我们使用triplet loss
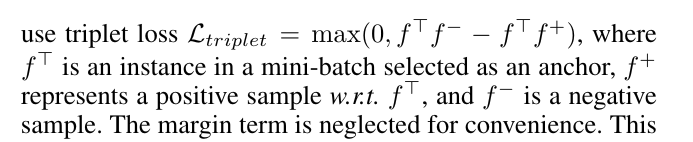
第二个挑战是triplet loss的训练可能不稳定,收敛速度可能很慢。为了稳定训练过程并加快融合,(Sohn 2016)提出了在triplet loss的平滑上限上进行优化的建议,

根据以上分析,我们推测在我们的情况下这三个损失的表现应该是LCE> Lupper> Ltriplet。 实验部分的实验结果证实了这一点。这样,我们选择交叉熵损失作为嵌入学习的目标(以下称为Lγ)。
具体来说,如果将定位框标记为前景,从密集嵌入图中提取相应的嵌入向量。将提取的嵌入内容馈送到共享的全连接层中,以输出类Logit,然后将交叉熵损失应用于Logit。以这种方式,来自多个尺度的嵌入共享相同的空间,并且跨尺度的关联是可行的。在计算嵌入损失时,将忽略带有标签-1的嵌入,即带有框注释但没有身份注释的前景。
Automatic Loss Balancing
JDE中每个预测头的学习目标可以建模为多任务学习问题。联合目标可以表示为每个尺度和每个组成部分的加权线性损失总和
我们采用(Kendall,Gal和Cipolla 2018)提出的针对任务权重的自动学习方案,采用了任务无关的不确定性概念。 形式上,具有自动损失平衡的学习目标写为

Online Association
在这里我们介绍一种简单快速的在线关联策略,以与JDE结合使用。
对于给定的视频,JDE模型处理每个帧并输出边框和相应的外观嵌入。 因此,我们计算观测值的嵌入与之前存在的轨迹池中的嵌入之间的关联矩阵。 使用匈牙利算法将观测分配给轨迹。 卡尔曼滤波器用于平滑轨迹并预测先前轨迹在当前帧中的位置。如果所分配的观测值在空间上与预测位置相距太远,则该分配将被拒绝。然后,对一个跟踪器的嵌入进行如下更新,如果没有任何观察值分配给Tracklet,则将该Tracklet标记为丢失;如果丢失的时间大于给定的阈值,则标记为已丢失的跟踪,将从当前的跟踪池中删除;或者将在分配步骤中重新找到。
Experiments
Datasets and Evaluation Metrics
在小型数据集上进行实验可能会导致有偏差的结果,并且在将相同算法应用于大规模数据集时可能无法得出结论。因此,我们通过将六个关于行人检测,MOT和人员搜索的公开可用数据集组合在一起,构建了大规模的训练集。这些数据集可以分为两种类型:仅包含边界框注释的数据集,以及同时具有边界框和身份注释的数据集。
第一类包括ETH数据集和CityPersons(CP)数据集。第二类包括CalTech(CT)数据集,MOT-16(M16)数据集,CUHK-SYSU(CS)数据集和PRW数据集 。收集所有这些数据集的训练子集以形成联合训练集,并排除ETH数据集中与MOT-16测试集重叠的视频以进行公平评估。 表1显示了联合训练集的统计数据。

为了进行验证/评估,需要评估性能的三个方面:检测准确性,嵌入的判别能力以及整个MOT系统的跟踪性能。 为了评估检测精度,我们在Caltech验证集上以0.5的IOU阈值计算平均精度(AP)。为了评估外观嵌入,我们在Caltech数据集的验证集上提取所有ground truth框的嵌入,CUHK-SYSU数据集和PRW数据集在这些实例中应用1:N检索,并以错误接受率0.1(TPR@FAR=0.1)报告真实的阳性率。为了评估整个MOT系统的跟踪精度,我们采用CLEAR度量(Bernardin和Stiefelhagen 2008),特别是最适合人类感知的MOTA度量。 在验证中,我们将MOT-15训练集使用重复的序列,并将训练集删除。在测试过程中,我们使用MOT-16测试仪与现有方法进行比较。
Implementation Details
我们使用DarkNet-53(Redmon和Farhadi 2018)作为JDE中的backbone network。 该网络使用标准SGD训练了30个epoch。 学习率初始化为10-2,并在第15和第23个时期降低0.1。几种数据增强技术(例如随机旋转,随机缩放和颜色抖动)可用于减少过度拟合。 最后,将增强图像调整为固定分辨率。 如果未指定,则输入分辨率为1088×608。
Experimental Results
Comparison of the three loss functions for appearance embedding learning

Comparison with SDE methods

在图4中,我们针对上述检测器和re-id模型的SDE组合的运行时间(每幅图像)绘制了MOTA度量。
所有模型的运行时都在单个Nvidia Titan xp GPU上进行了测试。 图4(a)显示了在MOT-15训练集上的比较,其中行人密度较低。 相反,图4(b)显示了包含高密度人群的视频序列的比较(来自CVPR19 MOT挑战数据的CVPR19-01)。 可以得出几个观察结果。
Comparison with the state-of-the-art MOT systems.

提出的JDE的运行速度也比现有方法至少快2到3倍,在接近1088×608的图像分辨率下达到接近实时的速度,即18.8 FPS。当我们对输入帧进行下采样以降低分辨率为864×408时,仅需一个JDE的运行时间就可以进一步加速到24.1 FPS。轻微的性能下降(∆ = -2.6%MOTA)。
这篇关于MOT论文笔记《Towards Real-Time Multi-Object Tracking》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


