本文主要是介绍深度学习中的变形金刚——transformer,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
很荣幸能和这些大牛共处一个时代。网络结构名字可以是一个卡通形象——变形金刚,论文名字可以来源于一首歌——披头士乐队的歌曲《All You Need Is Love》。
transformer在NeurIPS2017诞生,用于英语-德语,英语-法语的翻译,在BLEU(bilingual evaluation understudy)指标上得到了很好的表现。由自然语言生成代码也是一种翻译,文生图也是一种转换,事实上chatgpt,bert都是基于tranformer的。
RNN的问题:
为了将前文的信息传递到后面,让后面的字符利用前文信息,其实已经有RNN了:
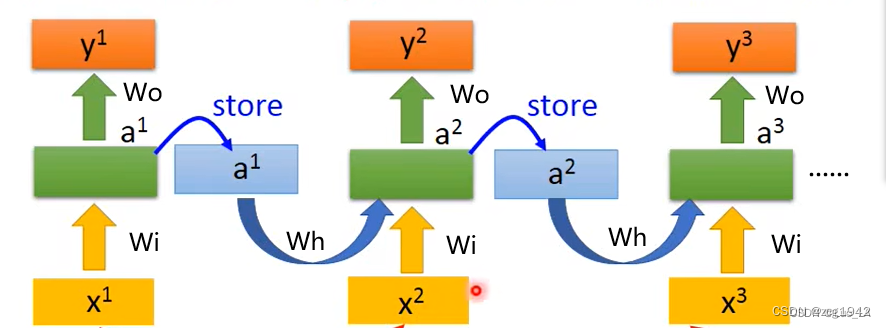
问题是前面的信息,越往后权重会低,是一个指数衰减的过程。
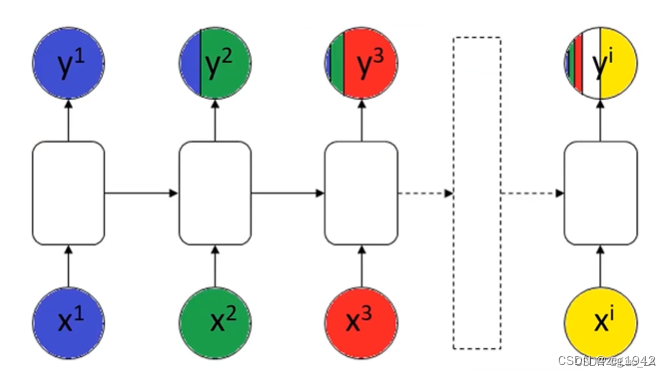
还有一个问题是权重反复利用,也是指数的关系,这样权重的细微抖动,就会造成很大的差异。

LSTM解决了一些RNN的问题
长短期记忆网络LSTM,但这项技术只能按照顺序处理句子,无法有效利用文章后面可能出现的线索。
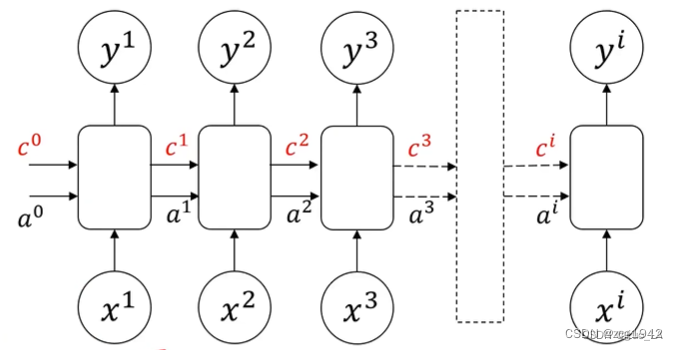
使用了三个门:输入门,忘记门,输出门,每一个门由一个信号和激活函数控制。
transformer
来看transformer的结构
RNN是处理语言的主流方法,但其信息处理速度缓慢,就像老式的磁带播放器,必须逐字逐句地播放。而Transformer模型则像是一位高效的DJ,能够同时操控多个音轨,迅速捕捉到关键信息。
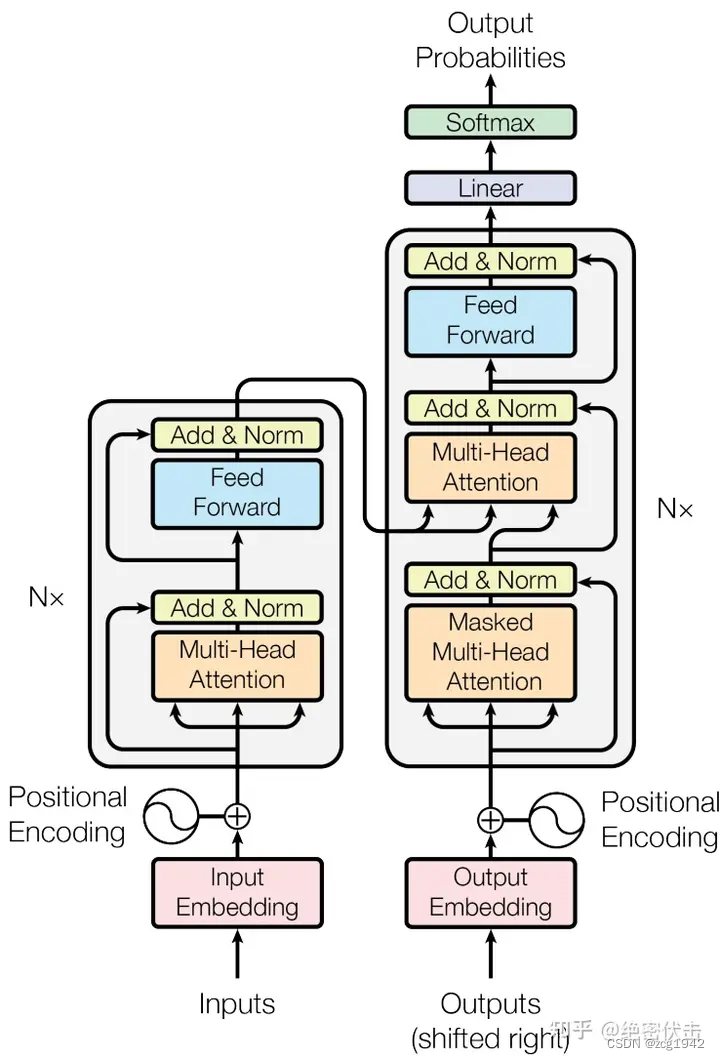 我们由粗到细地看,首先可以看到结构分为左右两部分,分别是Encoder和Decoder。其中有两种主要的结构,橘黄色的Multi-head Attention和蓝色的Feed forward,每个结构会连接一个Add&Norm,表示残差和层归一化。左边Encoder是1*Attention+1*Feed,右边是2*Attention+1*Feed。
我们由粗到细地看,首先可以看到结构分为左右两部分,分别是Encoder和Decoder。其中有两种主要的结构,橘黄色的Multi-head Attention和蓝色的Feed forward,每个结构会连接一个Add&Norm,表示残差和层归一化。左边Encoder是1*Attention+1*Feed,右边是2*Attention+1*Feed。
multi-head attention又是由多个Self-Attention组成的。多个Self-Attention得到多个输出矩阵,concat到一起,就是multi-head attention。
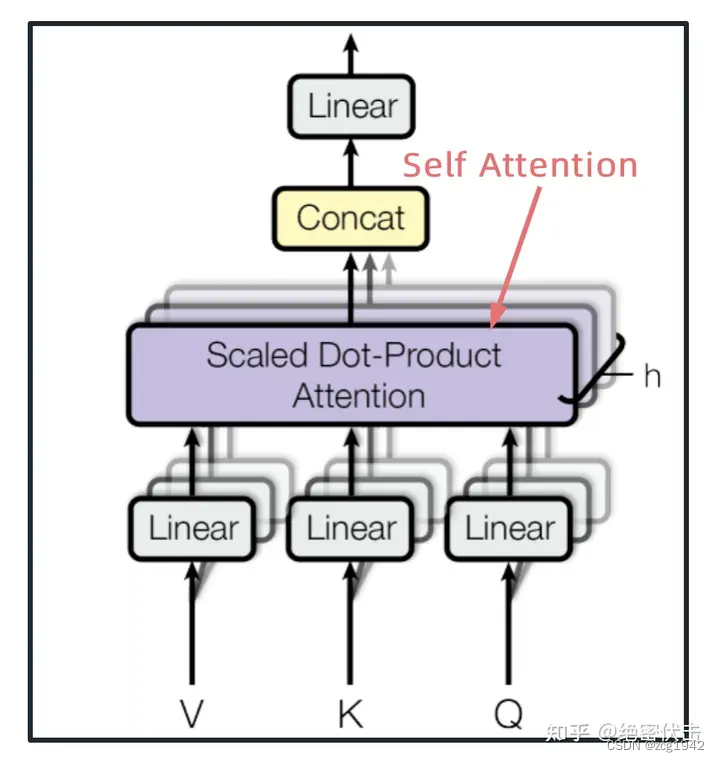
Self-Attention
Self-Attention就涉及到了著名的QKV三元素。
QKV也是三个矩阵,分别是查询,键值,值。他们都来源于Embedding,经过不同的权重矩阵得到。self-attention的结构和输出:
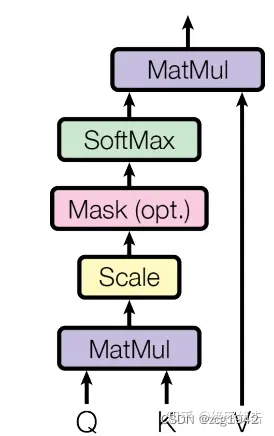
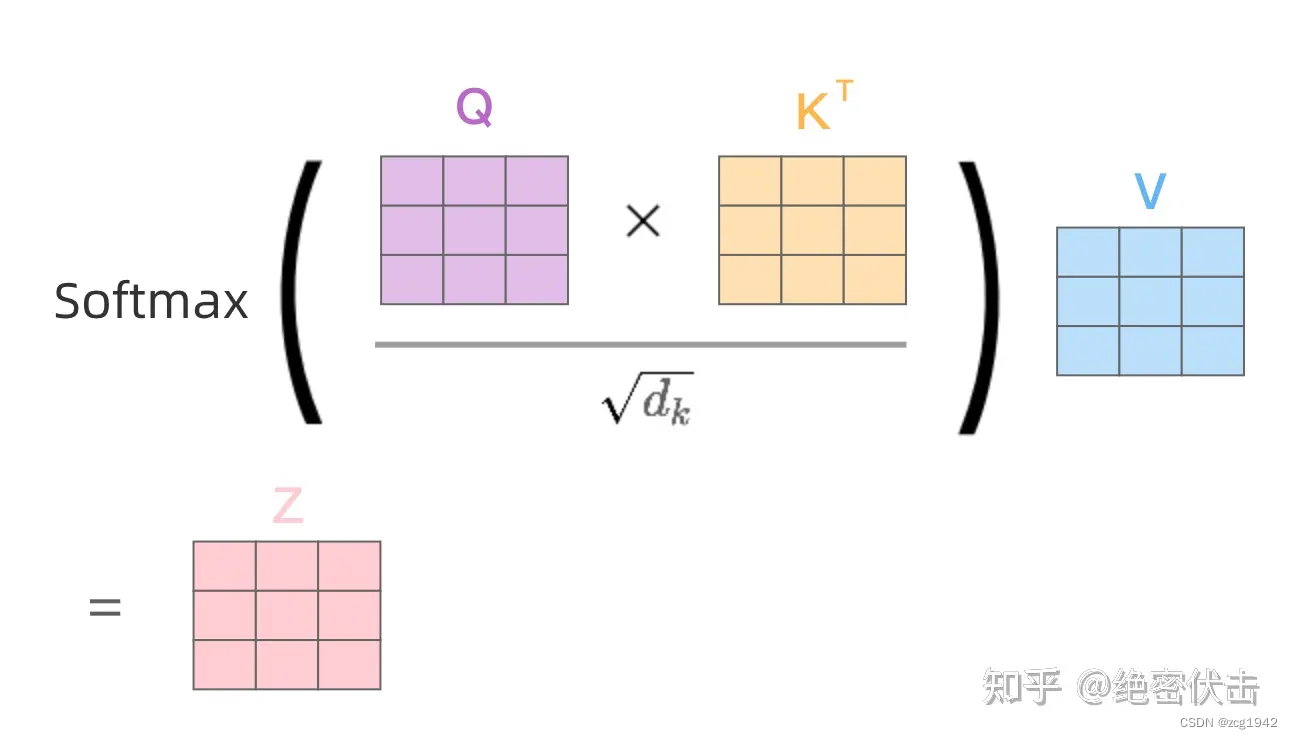
QKV的目的是在数据库中查询。特点是查询的query是数据库本身的一部分,目的是要得到query在整个句子中的分量。QK的部分实现的是不同Q之间的组合,组合的过程和顺序无关,主要是相关性。比如翻译中名词会有一些定语,这部分期望权重的绝对值应该比较大,而根据修饰的正面和负面,权重可以是正负,所以不同Q之间甚至是可以抵消的。
Q和V一起起到了信息搬运的效果,他俩合在一起才是真正的Q。从数学意义上讲,两个向量积是 相似度,所以QV得到了相似度mask矩阵。softmax则起到了归一化的作用。
而V,顾名思义就是value,是要查询的数据库。它也是由最原始的输入映射得到的。它直接决定了“苹果”是食物还是公司。
Embedding
self-attention的输入是Embedding,Embedding就是原始语料特征映射的结果。一般使用Word2Vec等词嵌入方法,所以也叫嵌入向量。不管是什么单词,嵌入后统一为长度512的向量。
但是这样的向量是没有位置信息的。“我爱你”和“你爱我”中的“我”映射的是相同的向量。位置信息完全隐藏在嵌入向量的相对顺序中。而如果后面有池化操作,位置信息就会完全丢失。
所以除了词嵌入,还需要位置嵌入,然后把二者加起来:
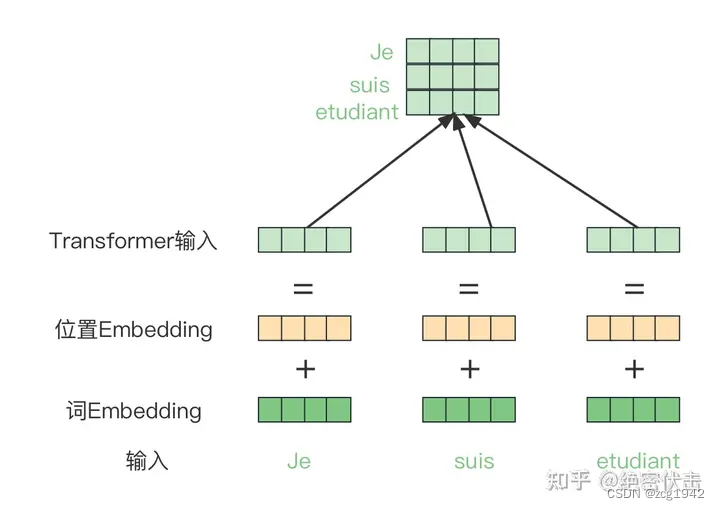 这就需要位置嵌入结果也是固定长度的,比如512,便于和词嵌入结果相加。
这就需要位置嵌入结果也是固定长度的,比如512,便于和词嵌入结果相加。
transformer使用的编码是基于正弦-余弦的:
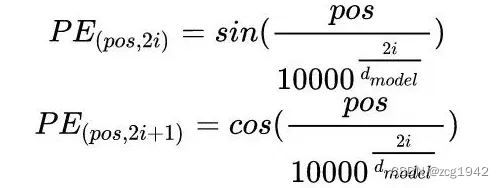
本来一个数字pos就可以表明位置,但是为了达到规定的长度,构建了正余弦交替的基本向量,当编码长度是4时,那就是4个基向量,然后把pos分别代入4个基向量中:

可以看到,固定位置pos时,分量交替使用正弦余弦,两两一组,每一组使用相同的值。
为什么使用正余弦作基?
1. 更有利于表示相对位置。由三角函数的特性,一个位置加减一个偏移量,新的位置向量可以由原来的位置向量线性组合得到。
2.相比于直接把pos转换成二进制,即便长度正好满足,每个比特位的变化频率明显不同(高比特位的变化频率更低),而基于正余弦的方法明显各个分量的更新都是同步的。
参考链接:
黄仁勋集齐Transformer论文七大作者,对话一小时,干货满满_凤凰网
【深度学习】RNN循环神经网络和LSTM深度学习模型_最新深度学习分类模型-CSDN博客
OpenAI公关跳起来捂他嘴:Transformer作者公开承认参与Q* |八位作者最新专访_澎湃号·湃客_澎湃新闻-The Paper
深度学习attention机制中的Q,K,V分别是从哪来的? - 知乎
http://jalammar.github.io/illustrated-transformer/
详解Transformer (Attention Is All You Need) - 知乎
Transformer系列:快速通俗理解Transformer的位置编码 - 简书
这篇关于深度学习中的变形金刚——transformer的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



