本文主要是介绍Python urllib 爬虫入门(2),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文为Python urllib类库爬虫更入门的一些操作和爬虫实例及源码。
目录
模拟浏览器请求
简单模拟
设置随机user-agent
请求超时
HTTP请求类型
Get请求
Post请求
抓取网页动态请求
封装ajax请求
调用
循环调用
抓取小说
封装请求函数
把html写入本地分析
调用
正则匹配
网页内容
正则匹配设置
总结
模拟浏览器请求
简单模拟
通过f12查看相应请求的请求头信息,进行简单的模拟请求。
示例如下:
import urllib.requesturl = 'http://www.baidu.com'
# 模拟请求头
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:125.0) Gecko/20100101 Firefox/125.0",
}# 设置请求实体
req = urllib.request.Request(url, headers=headers)# 发起请求
response = urllib.request.urlopen(req)
data = response.read().decode('utf-8')
print(data)设置随机user-agent
示例如下:
import random
import urllib.requesturl = 'http://www.baidu.com'
# 随机请求头
agentsList = ["Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:125.0) Gecko/20100101 Firefox/125.0","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
]
agentStr = random.choice(agentsList)
req = urllib.request.Request(url)
# 向请求体中添加随机User-Agent
req.add_header("User-Agent", agentStr)
response = urllib.request.urlopen(req)
data = response.read().decode('utf-8')
print(data)请求超时
如果网页长时间未响应,设置超时时间,不在爬取。
通过timeout参数来设置,单位为秒。
示例如下:
import urllib.requestfor i in range(1, 10):try:req = urllib.request.urlopen('http://www.baidu.com', timeout=1)print(req.read().decode('utf-8'))except:print('已经超时,继续爬取下一个!')HTTP请求类型
使用场景:进行客户端与服务端之间的消息传递时使用
GET:通过URL网址传递信息,可以直接在URL网址上添加要传递的信息
POST:可以向服务器提交数据,是一种比较流行的比较安全的数据传递方式
PUT:请求服务器存储一个资源,通常要指定存储的位置
DELETE:请求服务器删除一个资源BAD:请求获取对应的HTTP报头信息
OPTIONS:可以获取当前UTL所支持的请求类型
Get请求
特点:参数可直接在url中传输
优点:速度快,操作简单,主要用于接收数据。
缺点:不安全,并且传输的数据有限。
示例如下:
import urllib.requesturl = 'http://www.baidu.com'
req = urllib.request.urlopen(url)
data = req.read().decode('utf-8')
print(data)
print(type(data))
Post请求
特点:把参数进行打包,单独传输
优点:可承载数据量大,并且安全(当对服务器数据进行修改时建议使用post)
缺点:速度慢
示例如下:
import urllib.requesturl = 'http://localhost/2404/2.php'
# 将要发送的数据合成一个字典
data = {'username': '张三', 'pwd': '123456'}
# 对要发送的数据进行打包
postData = urllib.parse.urlencode(data).encode('utf-8')
# 请求体
req = urllib.request.Request(url, postData)
# 请求
req.add_header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:125.0) Gecko/20100101 Firefox/125.0")
response = urllib.request.urlopen(req)
print(response.read().decode('utf-8'))抓取网页动态请求
封装ajax请求
把抓取网页动态ajax请求处理封装为函数。
示例如下:
import json
import urllib.request
import ssldef ajaxRequest(page, pageSize):url = 'https://pre-api.tuishujun.com/api/listBookRank?rank_type=finish&first_type_id=1&second_type_id=7&page=' + str(page) + '&pageSize=' + str(pageSize)# 设置请求头headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:125.0) Gecko/20100101 Firefox/125.0","Accept": "application/json, text/plain, */*","Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2","Cookie": "HWWAFSESTIME=1714019095289; HWWAFSESID=b1ddc79c3c2d6f806c"}req = urllib.request.Request(url, headers=headers)# 使用ssl创建未验证的上下文context = ssl._create_unverified_context()response = urllib.request.urlopen(req, context=context)jstr = response.read().decode('utf-8')data = json.loads(jstr)# print(data)# print(type(data))return data调用
print(ajaxRequest(1, 10))执行结果:

循环调用
加入到循环中,模拟请求10次。
示例如下:
# 循环调用
data = {}
for i in range(1, 10):data[i] = ajaxRequest(i, 10)print(data)
抓取小说
在爬虫获取网页内容后使用正则匹配获取相应内容。
本实例将请求一个小说网站首页的最热小说。
封装请求函数
示例如下:
import urllib.requestdef bookReptiles(url):# 设置请求头headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:125.0) Gecko/20100101 Firefox/125.0","Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8","Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",}req = urllib.request.Request(url, headers=headers)response = urllib.request.urlopen(req)data = response.read().decode('utf-8')return data把html写入本地分析
可在封装函数中最后返回前调用,写入本地文件中分析网页内容用于设置正则匹配规则。
示例如下:
def writeLocal(content):# 写入本地 分析结构path = './xiaoshuo.html'with open(path, 'w', encoding='utf-8') as f:f.write(content)调用
设置好请求地址,并把请求地址传递给封装的函数即可。
示例如下:
url = '小说网站路径'
data = bookReptiles(url)正则匹配
通过查看通过上文写入本地的网页内容,设置获取小说名字和描述的正则规则。
网页内容
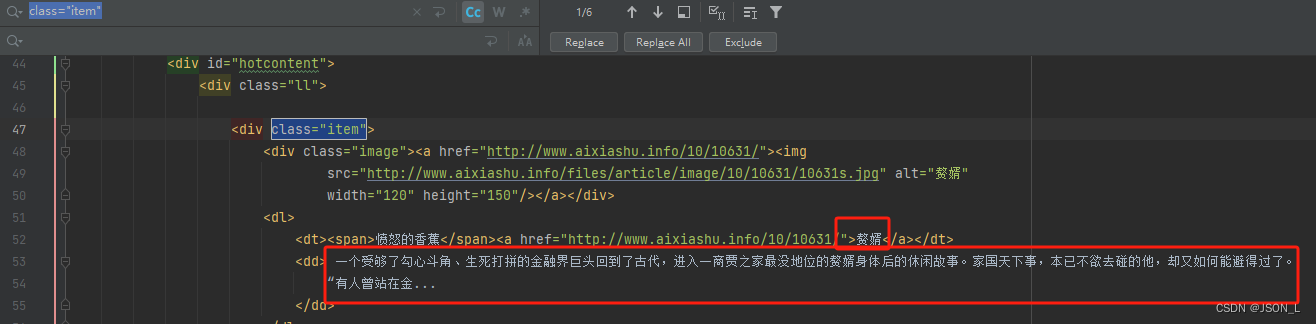
正则匹配设置
经过多次验证后最终正则规则设置如下。
示例如下:
# 正则匹配
import re
reg = re.compile('<div class="item">(.*?)</dl>', re.S)
div_data = reg.findall(data)
dic = {}
for div in div_data:# 标题title_reg = re.compile('<dt><span>.*?</span><a href=".*?">(.*?)</a>', re.S)titles = title_reg.search(div)title = titles.group(1)# 描述desc_reg = re.compile('<dd>(.*?)<\/dd>', re.S)descs = desc_reg.search(div)desc = descs.group(1)dic[title] = descfor d2 in dic:print(d2, '=> ', dic[d2])执行结果:

总结
本文为Python urllib类库爬虫更入门的一些操作和爬虫实例及源码。
这篇关于Python urllib 爬虫入门(2)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





