urllib专题

urllib与requests爬虫简介
urllib与requests爬虫简介 – 潘登同学的爬虫笔记 文章目录 urllib与requests爬虫简介 -- 潘登同学的爬虫笔记第一个爬虫程序 urllib的基本使用Request对象的使用urllib发送get请求实战-喜马拉雅网站 urllib发送post请求 动态页面获取数据请求 SSL证书验证伪装自己的爬虫-请求头 urllib的底层原理伪装自己的爬虫-设置代理爬虫coo

009.Python爬虫系列_urllib模块案例
我 的 个 人 主 页:👉👉 失心疯的个人主页 👈👈 入 门 教 程 推 荐 :👉👉 Python零基础入门教程合集 👈👈 虚 拟 环 境 搭 建 :👉👉 Python项目虚拟环境(超详细讲解) 👈👈 PyQt5 系 列 教 程:👉👉 Python GUI(PyQt5)文章合集 👈👈 Oracle数据库教程:👉👉 Oracle数据库文章合集 👈👈 优

urllib使用补充(二)
除一提到之外,urllib中还有一些常见的用法 如果希望返回与当前环境有关的信息,我们可以用info()返回,格式为“爬取的网页.info()”,爬取的网页赋值为file file.info() 如果希望获取当前爬取网页的状态码,我们可以使用getcode(),格式为“爬取的网页.getcode()”,爬取的网页赋值为file file.getcode() 如果想要获得当前爬取的url地
Urllib的使用(一)
1,使用urllib爬取网页首先需要导入对应的模块 import urllib.request 2,在导入模块后,我们需要使用urllib.request.urlopen打开并爬取一个网页。(以百度网址http://www.baidu.com为例) file=urllib.request.urlopean("http://www.baidu.com") 3,读取网页内容 data=fil

urllib与urllib2的学习总结(python2.7.X)
先啰嗦一句,我使用的版本是python2.7,没有使用3.X的原因是我觉得2.7的扩展比较多,且较之前的版本变化不大,使用顺手。3.X简直就是革命性的变化,用的蹩手。3.x的版本urllib与urllib2已经合并为一个urllib库,学着比较清晰些,2.7的版本呢urllib与urllib2各有各的作用,下面我把自己学习官方文档和其他资料的总结写下,方便以后使用。 urllib与url

Urllib库及其常用的四个模块
文章目录 1. 什么是Urllib2. Urllib库的4个核心模块2.1 request2.2 error2.3 parse2.4 robotparser 1. 什么是Urllib urllib 是 Python 标准库中的一个模块,用于处理 URL 及其相关操作。它提供了一组用于打开和读取 URL 的功能,支持 HTTP、HTTPS、FTP 等协议。 2. Urlli
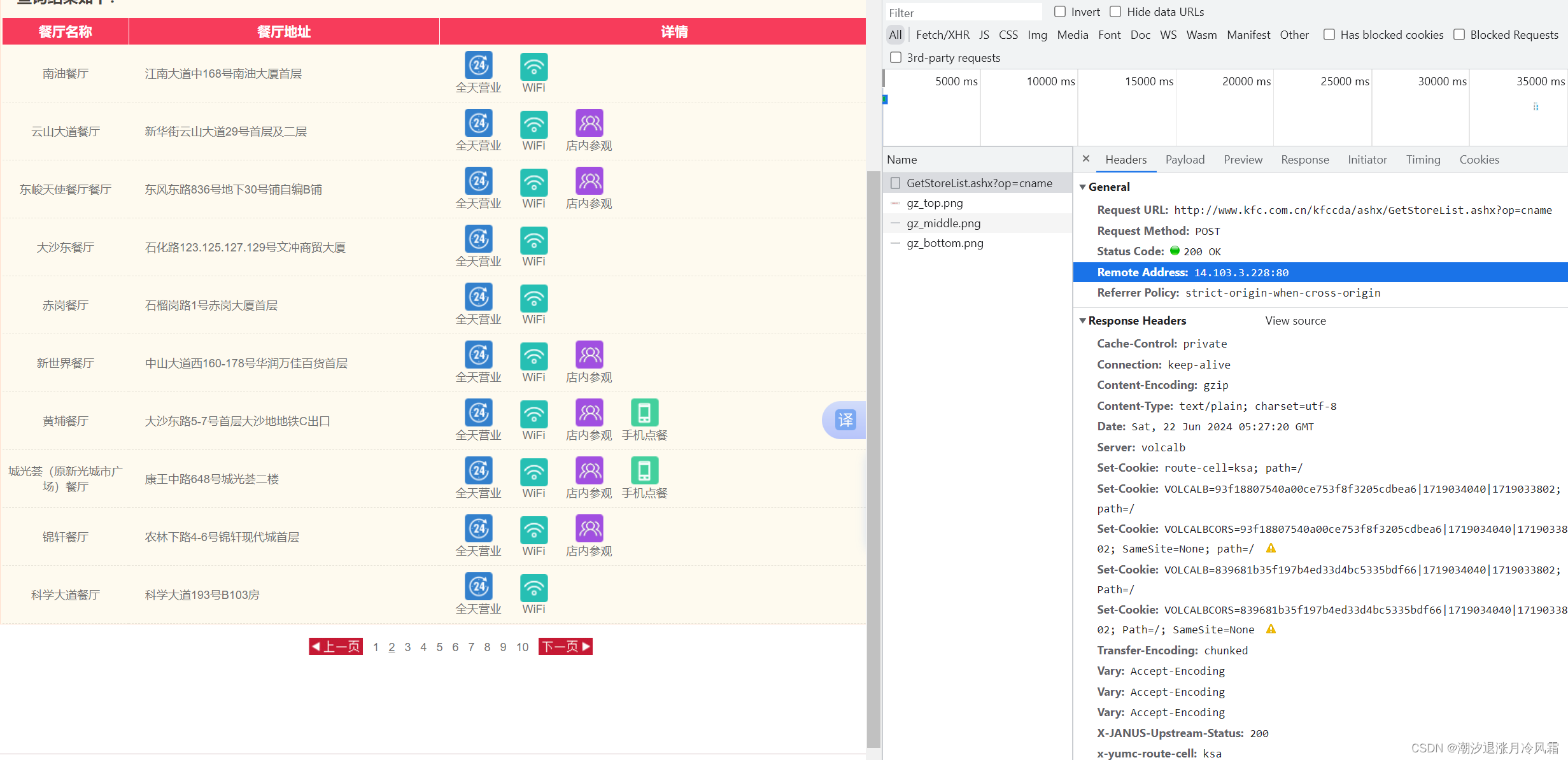
python爬虫学习笔记一(基本概念urllib基础)
学习资料:尚硅谷_爬虫 学习环境: pycharm 一.爬虫基本概念 爬虫定义 > 解释1:通过程序,根据URL进行爬取网页,获取有用信息 > 解释2:使用程序模拟浏览器,向服务器发送请求,获取相应信息 爬虫核心 > 1.爬取整个网页 > 2.解析数据,获取关心的数据 > 3.难点:爬虫VS非爬虫 爬虫设计思路 > 1.确定爬取的url > 2.模拟浏览器通过http协议访问url

Python基础教程(二十七):urllib模块
💝💝💝首先,欢迎各位来到我的博客,很高兴能够在这里和您见面!希望您在这里不仅可以有所收获,同时也能感受到一份轻松欢乐的氛围,祝你生活愉快! 💝💝💝如有需要请大家订阅我的专栏【Python系列】哟!我会定期更新相关系列的文章 💝💝💝关注!关注!!请关注!!!请大家关注下博主,您的支持是我不断创作的最大动力!!! 文章目录 引言一、urllib.request:发送网络请求1
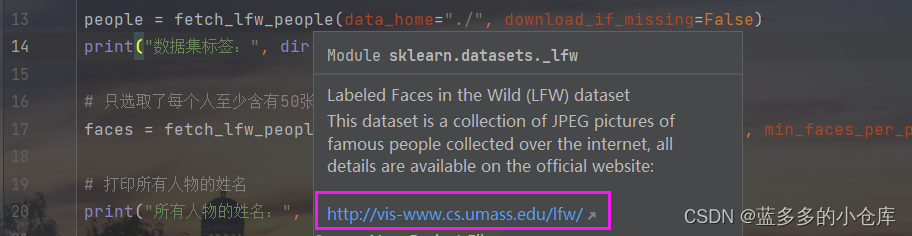
fetch_lfw_people()报错urllib.error.HTTPError: HTTP Error 403: Forbidden的解决方案
零、实验报告地址 计算机视觉实验二:基于支持向量机和随机森林的分类(Part one: 编程实现基于支持向量机的人脸识别分类 )-CSDN博客 一、代码报错 fetch_lfw_people()报错urllib.error.HTTPError: HTTP Error 403: Forbidden 二、报错原因 通常是由于访问权限不足导致的,fetch_

通过 urllib 结合代理IP下载文件实现Python爬虫
本教程将向您展示如何使用 Python 的 urllib 库结合代理 IP 来下载文件。这种技术对于避免被目标网站封锁 IP 或简单地从不同的地理位置访问网站特别有用。通过这种方式,您可以更安全地进行网页数据的爬取和分析。 安装必须的库 在开始编写代码之前,您需要确保已经安装了 Python 环境,并且安装了 urllib 库。urllib 是 Python 标准库的一部分,通常不需要单独安装
urllib.parse
架构概述 urllib.parse 是 Python 的 URL 解析和构造库。它提供了一系列函数,用于解析 URL、连接 URL、分割 URL 的各个部分、编码和解码 URL 组件等。这个库在处理网络请求和操作 URL 时非常有用。 基础功能 urlparse() - 用于解析 URL。 示例:from urllib.parse import urlparseresult = urlp
Python核心模块——urllib模块
urllib提供了一系列用于操作URL的功能。 urllib提供的功能就是利用程序去执行各种HTTP请求。如果要模拟浏览器完成特定功能,需要把请求伪装成浏览器。伪装的方法是先监控浏览器发出的请求,再根据浏览器的请求头来伪装,User-Agent头就是用来标识浏览器的。 参考资料: urllib方法介绍:https://www.cnblogs.com/sysu-blackbear/p/36294

06.爬虫---urllib与requests请求实战(POST)
06.urllib与requests请求实战POST 1.Urllib模块2.Requests模块3.实战(Requests) POST请求 Python中的POST请求是HTTP协议中的一种请求方法,用于向服务器提交数据。与GET请求不同,POST请求将数据封装在请求体中,而不是在URL中传递。通常情况下,POST请求用于向服务器提交表单数据、上传文件等操作。 urlli
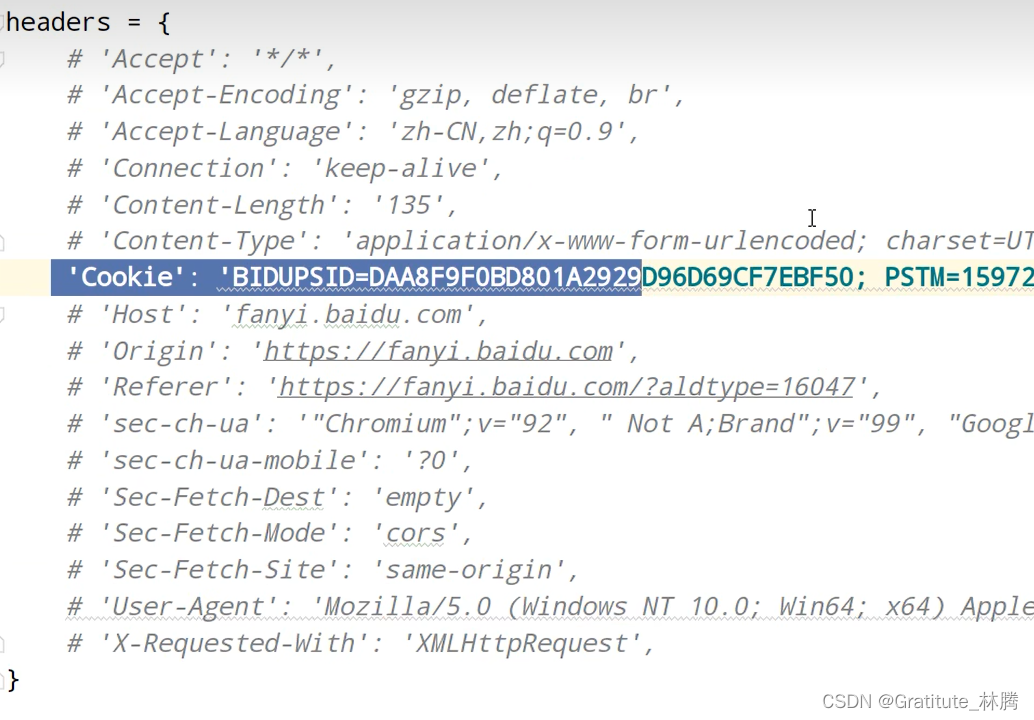
urllib_post请求_百度翻译之详细翻译
百度翻译有一个详细翻译的接口: post请求: 请求参数(较多): 打印之后,发现有问题: 改一下请求头: 将Accept-Encoding注释掉,因为我们使用的是utf-8编码: 加上下面这个,保证得到的字符串看得懂: 打印结果: 成功了。 将请求头的一些注释掉: 发现依然能打印正确的结果,说明是cookie反爬,heade
python3 urllib JWT json token 登录
python3 urllib JWT json token 登录 import urllib.requestimport jsonurl = "Response包含token信息的url"# 抓包登录参数username = "用户名"password = "密码"# 转换为JSON格式data = json.dumps({"username": username, "passwo
python3.x module 'urllib' has no attribute 'urlopen' 或 ‘urlencode’问题解决方法
问题 最近在使用Python的第三方模块 urllib 中的urlencode方法将字典编码,用于提交数据给url等操作,发现urllib 下并没有urlencode 和openurl,原来是因为在python3和python2下urllib模块中提供的urlencode 和openurl 位置不同。 解决 最好的解决办法就是找到 urllib 库文档 python2 python2
《爬虫学习》(二)(urllib库使用)
urllib库是Python中一个最基本的网络请求库。可以模拟浏览器的行为,向指定的服务器发送一个请求,并可以保存服务器返回的数据。 1.urlopen函数: 在Python3的urllib库中,所有和网络请求相关的方法,都被集到urllib.request模块下面了,以先来看下urlopen函数基本的使用: from urllib import requestresp = request
python3 urllib 链接中有中文的解决方法
环境python3,开发平台pycharm,使用urllib时,当url中存在中文时会出现以下错误: UnicodeEncodeError: 'ascii' codec can't encode characters in position 69-78: ordinal not in range(128) 解决方法 单独处理url中的中文如: import urllibs
Python中urllib的urlretrieve
urllib.urlretrieve(url[, filename[, reporthook[, data]]]) 内部会使用URLopener或者 FancyURLOpener类 url 外部或者本地url filename 本地文件地址 reporthook 回调函数 data post数据 利用urlretrieve下载sina首
爬虫学习--2.urllib 库
urllib了解 urllib 库 是 Python 内置的 HTTP 请求库。urllib 模块提供的上层接口,使访问 www 和 ftp 上的数据就像访问本地文件一样。 有以下几种模块: urllib.request 请求模块 urllib.error 异常处理模块 urllib.parse url解析模块 urllib.robotparser robots.txt 解析模块
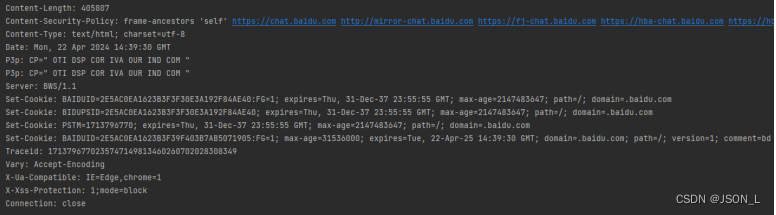
Python urllib 爬虫入门(1)
本文主要为Python urllib类库函数和属性介绍及一些简单示例。 目录 urllib爬取网页 简单示例 写入文件 其他读取方法 readline函数 readlines函数 response属性 当前环境信息 返回状态码 返回url地址 对url进行编码与解码 写入文件 总结 urllib爬取网页 通过python的urllib库请求爬取网页的一

Python urllib 爬虫入门(2)
本文为Python urllib类库爬虫更入门的一些操作和爬虫实例及源码。 目录 模拟浏览器请求 简单模拟 设置随机user-agent 请求超时 HTTP请求类型 Get请求 Post请求 抓取网页动态请求 封装ajax请求 调用 循环调用 抓取小说 封装请求函数 把html写入本地分析 调用 正则匹配 网页内容 正则匹配设置 总结 模拟浏
2020-11-06 Python----------爬取豆瓣预备知识(urllib库request,beautifulsoup)
Python爬取豆瓣 Python编码规范 一般第一句加 # -*- coding: utf-8 -*- 或 # coding=utf-8 加入main函数用于测试函数 # -*- coding: utf-8 -*-def main():print("hello")if __name__ == "_main_": #主程序入口main()#两个下划线name再两个下划线
urllib.parse 库详解
概述 urllib.parse 是 Python 标准库中用于处理 URL 的库。它提供了一系列函数和类,用于在 Python 程序中与网络交互。urllib.parse 库的功能包括: 解析 URL 字符串构造 URL 字符串对 URL 进行编码和解码处理 URL 的组成部分(如协议、主机、路径等)标准化 URL 格式 常用函数 urllib.parse 库中提供了以下常用函数:
urllib库 + re模块爬取内涵吧的文字段子
源码 # !/usr/bin/env python# -*- coding:utf-8 -*-"""爬去内涵吧的段子关键点:1.分析url2.分析html源码中段子的标题和内容,构建正则表达式3.findall()方法"""import urllib.requestimport reclass Spider(object):def __init__(self):"""page:页码""
urllib库进行网络请求后返回的HTTPResponse对象的用法总结
不管是使用urllib.request.urlopen()方法,还是使用opener.open()方法,都返回同样类型的HTTPResponse对象,用法总结如下: # !/usr/bin/env python# -*- coding:utf-8 -*-from urllib import requestfrom urllib import responseURL="http://www