本文主要是介绍从0到1用java再造tcpip协议栈:使用责任链模式实现ICMP错误数据报解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
上一节我们讲述了ICMP协议的数据格式,说到了ICMP数据报包含两种类型的信息:错误消息和控制消息。同时我们详细解析了包含错误消息时的数据格式,本节我们使用代码来实现ICMP错误数据报的解析。
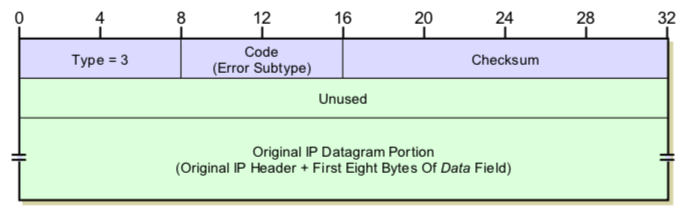
上图显示的是ICMP数据报包含错误消息时的格式。它一个特点是底层数据格式需要根据上头type和code两个字段指定,这两个字段不同数值的组合对应底层不同数据结构,由于type有125种取值,而对应固定的type取值,code的取值有可能有十几种,因此我们的解析代码需要处理成千上万种情况。如果我们把所有的处理逻辑用代码集中起来处理,那么我们就得写庞大的if…else…分支,这会使得代码冗余,容易出错,而且难以维护,为了实现代码的结构化和鲁棒性,我们采用设计模式中的责任链模式来完成数据解析设计,如下图:
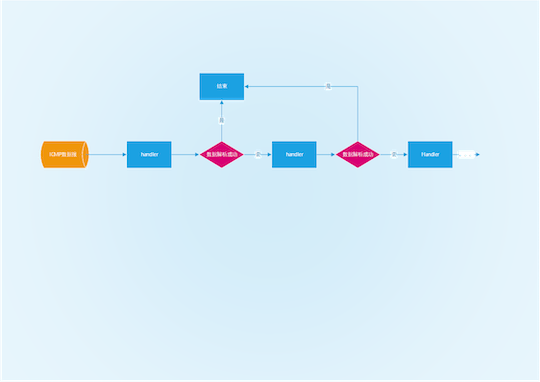
所谓责任链模式就是把很多个if…else拆解成多个并列的处理对象,然后将这些对象用队列串联起来,这些对象导出同一个接口,一旦有数据来临时,我们从队列里将这些处理对象一一取出,把数据传入,如果该对象能解析当前数据,那么它返回true,处理流程结束,如果不能处理,那么我们把数据传入下一个解析对象,一直到所有解析对象都调用完毕为止。责任链模式能很好应对多变的数据格式场景,如果要解析的数据发生改变,我们只要改变某个处理对象或增加一个新的处理对象即可,于是代码可以保持紧凑和鲁棒。由于ICMP错误数据报有多种格式,因此我们采用这种模式来应对,接下来看看代码实现。
首先我们添加一个新类叫ICMPProtocolLayer,它专门用于解读或构造ICMP数据包:
package ICMPProtocolLayer;import java.nio.ByteBuffer;
import java.util.ArrayList;
import java.util.Arrays;import jpcap.PacketReceiver;
import jpcap.packet.EthernetPacket;
import jpcap.packet.Packet;public class ICMPProtocolLayer implements PacketReceiver{private static byte PROTOCL_ICMP = 1;public static int ICMP_DATA_OFFSET = 20 + 14; //越过20字节IP包头private static int PROTOCOL_FIELD_IN_IP_HEADER = 14 + 9;private ArrayList<IICMPErrorMsgHandler> error_handler_list = new ArrayList<IICMPErrorMsgHandler>();private enum ICMP_MSG_TYPE {ICMP_UNKNOW_MSG,ICMP_ERROR_MSG,ICMP_INFO_MSG};private int icmp_type = 0;private int icmp_code = 0;private byte[] packet_header = null;private byte[] packet_data = null;public ICMPProtocolLayer() {//添加错误消息处理对象error_handler_list.add(new ICMPUnReachableMsgHandler());}@Overridepublic void receivePacket(Packet packet) {if (packet == null) {return;}//确保收到数据包是IP类型EthernetPacket etherHeader = (EthernetPacket)packet.datalink;if (etherHeader.frametype != EthernetPacket.ETHERTYPE_IP) {return;}//读取IP包头,也就是接在数据链路层后面的20字节,读取协议字段是否表示ICMP,也就是偏移第10个字节的值为1if (packet.header[PROTOCOL_FIELD_IN_IP_HEADER] != PROTOCL_ICMP) {return;}packet_header = Arrays.copyOfRange(packet.header, ICMP_DATA_OFFSET, packet.header.length);packet_data = packet.data;analyzeICMPMessage(packet_header);}private ICMP_MSG_TYPE checkType(int type) {/** 传递错误消息的ICMP数据报type处于0到127,* 传递控制信息的ICMP数据报type处于128到255*/if (type >= 0 && type <= 127) {return ICMP_MSG_TYPE.ICMP_ERROR_MSG;}if (type >= 128 && type <= 255) {return ICMP_MSG_TYPE.ICMP_INFO_MSG;}return ICMP_MSG_TYPE.ICMP_UNKNOW_MSG;}private void analyzeICMPMessage(byte[] data) {ByteBuffer byteBuffer = ByteBuffer.wrap(data);icmp_type = byteBuffer.get(0);icmp_code = byteBuffer.get(1);//检测当前数据包是错误信息还是控制信息,并根据不同情况分别处理if (checkType(icmp_type) == ICMP_MSG_TYPE.ICMP_ERROR_MSG) {handleICMPErrorMsg(packet_data);}}private void handleICMPErrorMsg(byte[] data) {/** ICMP错误数据报的类型很多,一个type和code的组合就能对应一种数据类型,我们不能把对所有数据类型的处理全部* 塞入一个函数,那样会造成很多个if..else分支,使得代码复杂,膨胀,极难维护,因此我们使用责任链模式来处理*/for (int i = 0; i < error_handler_list.size(); i++) {if (error_handler_list.get(i).handleICMPErrorMsg(icmp_type, icmp_code, data) == true) {break;}}}}
它跟我们前几节实现的ARP解析类一样,一旦数据链路层有数据包时,就会将数据包交给它,它会检测数据包是否来自ICMP协议,如果不是就返回,是的话就执行下一步处理流程。它包含的error_handler_list就是前面我们提到的将处理对象串联起来的队列,这些处理对象统一导出一个名为handleICMPErrorMsg的接口,该接口定义如下:
package ICMPProtocolLayer;public interface IICMPErrorMsgHandler {public boolean handleICMPErrorMsg(int type, int code, byte[] data);
}接下来我们实现一个能解读Destination Unreachable错误数据报的处理对象,其代码如下:
package ICMPProtocolLayer;import java.nio.ByteBuffer;import jpcap.packet.IPPacket;public class ICMPUnReachableMsgHandler implements IICMPErrorMsgHandler {private static int ICMP_UNREACHABLE_TYPE = 3;private static int IP_HEADER_LENGTH = 20;enum ICMP_ERROR_MSG_CODE {ICMP_NETWORK_UNREACHABLE,ICMP_HOST_UNREACHABLE,ICMP_PROTOCAL_UNREACHABLE,ICMP_PORT_UNREACHABLE,ICMP_FRAGMETATION_NEEDED_AND_DF_SET//后面需要在继续添加其他类型} ;@Overridepublic boolean handleICMPErrorMsg(int type, int code, byte[] data) {if (type != ICMPUnReachableMsgHandler.ICMP_UNREACHABLE_TYPE) {return false; }ByteBuffer buffer = ByteBuffer.wrap(data);switch (ICMP_ERROR_MSG_CODE.values()[code]) {case ICMP_PORT_UNREACHABLE://错误数据格式:IP包头和8字节内容//获取协议类型byte protocol = buffer.get(9);if (protocol == IPPacket.IPPROTO_UDP) {handleUDPError(buffer);}break;default:return false;}return true;}private void handleUDPError(ByteBuffer buffer) {System.out.println("protocol of error packet is UDP");System.out.println("Source IP Address is :");int source_ip_offset = 12;for (int i = 0; i < 4; i++) {int v = buffer.get(source_ip_offset + i) & 0xff;System.out.print(v + ".");}System.out.println("\nDest IP Address is :");int dest_ip_offset = 16;for (int i = 0; i < 4; i++) {int v = buffer.get(dest_ip_offset + i) & 0xff;System.out.print(v + ".");}/** 打印UDP数据包头前8个字节信息,其格式为:* source_port(2 byte),* dest_port (2byte)* length (2byte)* check_sum(2byte)*/int source_port = (int) (buffer.getShort(IP_HEADER_LENGTH) & 0xFFFF);System.out.println("\nSource Port: " + source_port);int source_port_len = 2;int dest_port = (int) (buffer.getShort(IP_HEADER_LENGTH + source_port_len) & 0xFFFF);System.out.println("dest port: " + dest_port);}}
我们看到,Destination UnReachable错误对应的type是3,但它有对应不同的code值,这些值对应不同情形的unreachable错误,代码里的枚举类ICMP_ERROR_MSG_CODE对应不同code值,在上面实现中,我们暂时只处理code值是3的情况,也就是处理port unreachable这种情形。该类继承了IICMPErrorMsgHandler,因此它必须实现handleICMPErrorMsg函数。在Destination UnReachable ICMP数据包中,附带内容的格式是导致该错误数据包的IP包头加8字节内容,因此我们需要按照IP数据包头格式解析前20字节,回忆一下IP包头的数据结构:

从包头开始偏移9个字节后表示数据包上层协议类型,因此在函数handleICMPErrorMsg中,它首先读取该字段,确定数据包采用的是UDP协议,如果是的话,我们调用handleUDPError进一步对数据进行解析。该函数首先从IP包头中打印数据包发出者和接收者的IP,然后根据UDP数据包的协议,开始两字节是发送者的端口,接着两字节是接收者的端口。
为了验证代码的正确性,我们先使用wireshak抓取一个ICMP错误类型数据包:
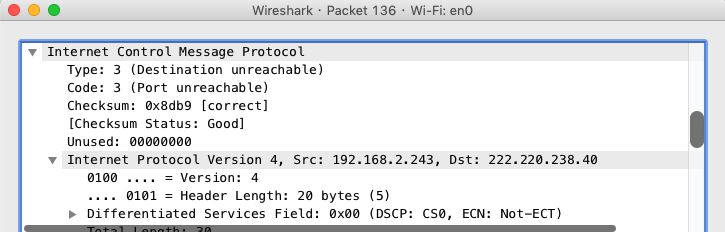
从上图看出该数据包的type和code都是3,表示它包含Destination UnReachable错误信息,具体错误类型为port unreachable。接着往下拉我们会看到接在ICMP报头后面的是IP报头:
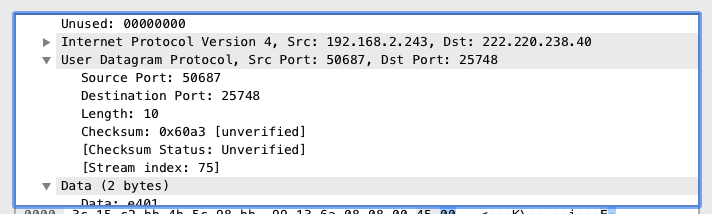
从上图我们可以看出,错误数据包的发送者ip是192.168.2.243,接收者是222.220.238.40,越过20字节的IP包头后,跟着的是UDP数据包头,它头两个字节是发送者端口,从上面看出是50687,接收者端口是25748,由此我们对应一下代码运行后的结果:
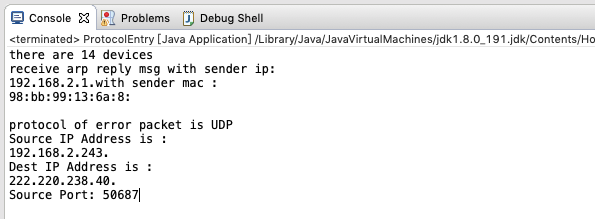
从代码运行结果来看,它打印出来的信息与wireshak抓包的信息时一致的,在上面显示中没有打印接收者端口,那是因为我在调试时提前把代码运行终止了。
更详细的讲解和代码调试演示过程,请点击链接
这篇关于从0到1用java再造tcpip协议栈:使用责任链模式实现ICMP错误数据报解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






