本文主要是介绍hadoop examples(wordcount.class)例子,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天我们学习了一个hadoop下的examples,全名是hadoop-mapreduce-examples-2.8.0.jar
在hadoop-mapreduce-examples-2.8.0.jar下,有很多的算法,用来实现很多的功能。其中有个wordcount.txt,功能是统计文件内容的个数(按空格分隔)。
例题
开启hadoop
[root@Tyler01 ~]# start-all.sh创建一个有内容的文件 word.txt
[root@Tyler01 ~]# vi word.txthello tyler
hello kopmgkomg
hello tylerhjghjghjghjgjh
hello as
hello pp
hello as
hello pp
hello as
hello daniu
hello daniu
在hdfs上创建个目录
[root@Tyler01 ~]# hadoop fs -mkdir /wc/
将文件上传到hdfs上
hadoop fs -put ./word.txt /wc/input
执行hadoop官方提供的mapreduce的wordcount的例子
首先进入到/home/tyler/apps/hadoop-2.8.0/share/hadoop/mapreduce目录下
[root@Tyler01 mapreduce]#hadoop jar hadoop-mapreduce-examples-2.8.0.jar wordcount /wc/word.txt /wc/output/
命令说明:
hadoop jar :用hadoop发方式运行jar文件
hadoop-mapreduce-examples-2.8.0.jar:具体的jar文件
wordcount:jar文件中的具体类
/wc/input/wordcount.txt:word类运行需要的第一个参数,hdfs文件系统的输入目录
/wc/output/:word类运行需要的第二个参数,hdfs文件系统的输出目录
查看执行完word后,hdfs的输出目录,最后的计算结果如下:
hadoop fs -ls /wc/out
hadoop fs -cat /wc/out/part-r-00000
as 3
daniu 2
hello 10
kopmgkomg 1
pp 2
tyler 1
tylerhjghjghjghjgjh 1
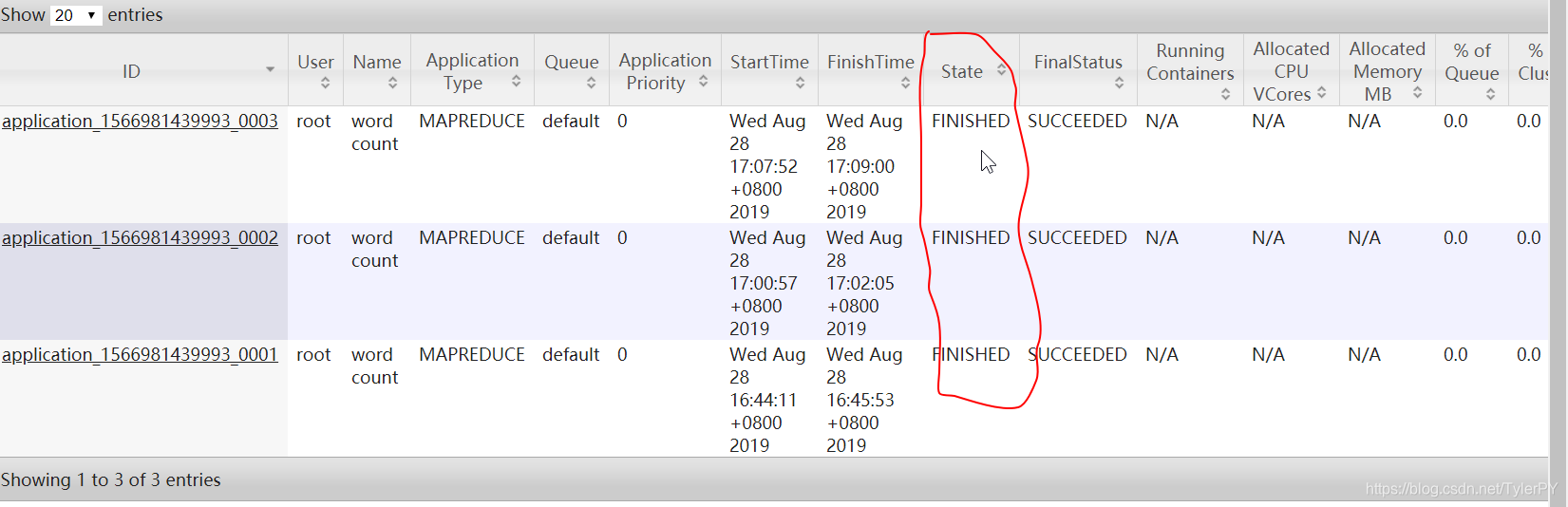
执行完后,在192.168.72.110:8088下查看执行的状态。若是以下结果,则说明执行完毕。
这篇关于hadoop examples(wordcount.class)例子的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!