本文主要是介绍【论文阅读】ELAN-Efficient Long-Range Attention Network for Image Super-resolution,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ELAN-Efficient Long-Range Attention Network for Image Super-resolution
- 论文地址
- 简介
- 1 引言
- 2相关工作
- 2.1 基于 CNN 的 SR 方法
- 2.2 基于 Transformer 的 SR 方法
- 3 方法论
- 3.1 ELAN 的整体流程
- 3.2 Efficient Long-range Attention Block (ELAB)
- 4实验
- 4.1实验设置
- 4.2 与轻量级 SR 模型的比较
- 4.4 消融研究
- 5 结论
论文地址
1、论文
2、源码
简介
最近,基于变压器的方法通过利用自注意力 (SA) 进行特征提取,在各种视觉任务中展示了令人印象深刻的结果,包括图像超分辨率 (SR)。然而,在大多数现有的基于变压器的模型中,SA 的计算非常昂贵,而一些采用的操作对于 SR 任务可能是多余的。这限制了 SA 计算的范围,从而限制了 SR 性能。在这项工作中,我们提出了一种用于图像 SR 的高效远程注意力网络 (ELAN)。具体来说,我们首先采用移位卷积(shift-conv)有效地提取图像局部结构信息,同时保持与 1x1 卷积相同的复杂度,然后提出一个分组多尺度自注意力(GMSA)模块,它使用不同的窗口大小计算非重叠特征组的 SA,以利用远程图像依赖性。然后通过简单地将两个 shift-conv 与 GMSA 模块级联来构建高效的远程注意力块 (ELAB),并通过使用共享注意力机制进一步加速。没有花里胡哨的东西,我们的 ELAN 通过顺序级联 ELAB 遵循相当简单的设计。大量实验表明,ELAN 相对于基于 Transformer 的 SR 模型获得了更好的结果,但复杂性显着降低。源码可以在https:/github.com/xindongzhang/ELAN找到。
关键词:Super-Resolution, Long-Range Attention, Transformer
1 引言
图像超分辨率 (SR) 旨在再现其降级的低分辨率 (LR) 对应物的高分辨率 (HR) 输出。近年来,基于深度卷积神经网络(CNN)[23]的SR模型[11, 12, 47, 29, 6, 50, 60, 60, 46, 53]因其强大的图像高频细节恢复或生成能力而流行起来,在图像和视频的恢复、过渡和显示方面显示出较高的实用价值。然而,许多基于CNN的方法提取具有空间不变内核的局部特征,这些内核对于自适应地建模像素之间的关系是不灵活的。此外,为了扩大感受野,基于 CNN 的 SR 模型倾向于采用非常深且复杂的网络拓扑 [60、10、64、41、40] 来恢复更多细节,从而导致大量计算资源消耗。最近,基于转换器的方法在自然语言处理任务 [4, 14, 33, 43] 上显示出令人印象深刻的性能,因为它们对输入数据的自注意力 (SA) 建模具有强大的能力。 Transformers 在 NLP 上的巨大成功激发了研究人员探索它们在计算机视觉任务中的应用,并且在几个高级视觉任务中显示了有趣的结果[13、26、34、35、44
、52]。
一般而言,首先将输入图像划分为不同尺度的非重叠块作为标记,然后将局部特征提取和 SA 模块应用于块的集合。尽管 SA 已被证明对高级视觉任务有效,但其复杂性随输入特征尺寸呈二次方增长,限制了其在低级视觉任务(如 SR,其中特征尺寸通常非常大)中的使用。是为了降低 SA 在 SR 应用中的计算成本。梅等。 [40] 将图像分成非重叠的块,用于独立建模局部特征和 SA,但这可能会引入边界效应并降低恢复图像的视觉质量。 SwinIR [28] 遵循 Swin Transformer [35] 的设计,其中局部特征首先通过两个级联的 1×1 卷积提取,然后在一个小尺寸窗口(即 8×8)内通过移位机制计算 SA与其他窗口建立连接。然而,通过具有小感受野的 1×1 卷积提取的局部特征可能会产生弱特征表示来计算远程建模的 SA。此外,使用小窗口计算 SA 限制了对图像像素之间的长程依赖性建模的能力。 Restormer [58] 计算 SA 依赖于仍然适用于大图像的通道空间。然而,对通道空间的建模依赖可能会牺牲一些有用的纹理和结构空间信息,这对于再现高质量的 HR 图像很重要。
在本文中,我们的目标是开发一种有效且高效的方法来利用图像远程注意力具有简单网络架构的图像 SR。现有的基于 transformer 的模型,如 SwinIR [28] 有许多冗余和零散的组件,这些组件对于 SR 任务来说不具有成本效益,例如相对位置偏差、掩蔽机制、层归一化以及使用残差快捷方式创建的几个子分支.因此,我们的目标是构建一个高度整洁和高效的 SR 模型,其中 LR 到 HR 图像映射是通过按顺序堆叠局部特征提取操作和 SA 来简单构建的。
两个连续的移位卷积(shift-conv)操作用于有效地提取局部结构信息,而 shift-conv 具有更大的感受野但与 1×1 卷积具有相同的算法复杂度。
对于SA计算,我们提出了一个group-wise multi-scale self-attention (GMSA)算子,它将特征分成不同窗口大小的不同组并分别计算SA。
这种策略提供了比小的固定-更大的感受野大小窗口用于远程注意力建模,同时比大型固定大小窗口更灵活,用于降低计算资源成本。
此外,还提出了一种共享注意力机制,以加快后续GMSA模块的计算。通过移动转换和GMSA的武装,共享注意力,很容易获得一个高效的远程注意力网络,即ELAN,用于SR。我们的贡献总结如下:
1)我们提出了一种高效的远程注意力块来建模图像的远程依赖性,这对于提高SR性能具有重要意义。
2)我们提出了一个相当简单但功能强大的网络,即ELAN,它记录了图像SR的新技术水平,其复杂性明显低于现有的基于视觉变压器的SR方法。
2相关工作
在过去的十年中,已经开发了许多基于深度学习的图像 SR 方法。在这里,我们从基于 CNN 的方法和基于 Transformer 的方法的角度简要讨论相关工作。
2.1 基于 CNN 的 SR 方法
基于 CNN 的方法在 SR 任务中表现出了令人印象深刻的性能。 SRCNN [11] 首次尝试通过学习从双三次上采样 LR 图像到仅三个卷积层的 HR 输出的非线性映射,将 CNN 用于图像 SR。金等人。 [20] 用 VGG-19 和残差学习加深了网络,并取得了更好的性能。由于预上采样策略增加了 CNN 的输入数据量并导致大量计算成本,因此 FSRCNN [12] 采用后上采样策略来加速 CNN 模型。 [29] 中提出了一种增强的残差块来训练深度模型而无需批量归一化,开发的 EDSR 网络获得了 NTIRE2017 挑战赛的一等奖 [1]。为了构建更有效的 SR 模型,最近开发的方法倾向于采用更深层次和更复杂的架构以及注意力技术。张等。提出了一种残差结构与通道注意力相结合,以训练一个超过 400 层的非常深的网络。 MemNet [49] 和 RDN [62] 等其他作品是通过使用密集块 [16] 来设计的,以利用来自所有层的中间特征。除了增加网络深度外,其他一些工作,如 SAN [10]、NLRN [30]、HAN [41] 和 NLSA [40],沿着空间或通道维度挖掘特征相关性以提高 SR 性能.我们提出的 ELAN 具有快速局部特征提取的优势,同时通过高效的分组多尺度自注意力对特征的远程依赖性进行建模。
2.2 基于 Transformer 的 SR 方法
Transformer 网络在自然语言处理 (NLP) 中的突破受启发于在计算机视觉任务中使用自注意力 (SA)。 Transformer 中的 SA 机制可以有效地对数据之间的依赖关系进行建模,并且在图像分类 [13、26、34、35、44、52]、图像检测 [ 8、32、35、52] 和分割 [7、35、57、63]。最近,Transformer 也被应用于低级视觉任务 [28、55、58、9]。 IPT [9] 是一个非常大的预训练模型,用于基于标准视觉转换器的各种低级视觉任务。它在非重叠块上计算局部特征和 SA,但是这可能会丢失一些用于再现图像细节的有用信息。 SwinIR [28] 因此将 Swin Transformer [35] 应用于图像恢复,它结合了 CNN 和 Transformer 的优点。尽管 SwinIR 在图像 SR 方面取得了令人瞩目的成果,但其网络结构主要借鉴了专为高级视觉任务设计的 Swin Transformer。特别是,SwinIR 的网络设计对于 SR 问题是冗余的,它在固定大小的小窗口上计算 SA,防止它利用远程特征依赖性。我们提出的 ELAN 不仅比 SwinIR 更有效,而且能够在更大的窗口中计算 SA。
3 方法论
在本节中,我们首先介绍了用于 SR 任务的高效长程注意力网络 (ELAN) 的流水线,然后详细讨论了其关键组件,即高效长程注意力块 (ELAB)。
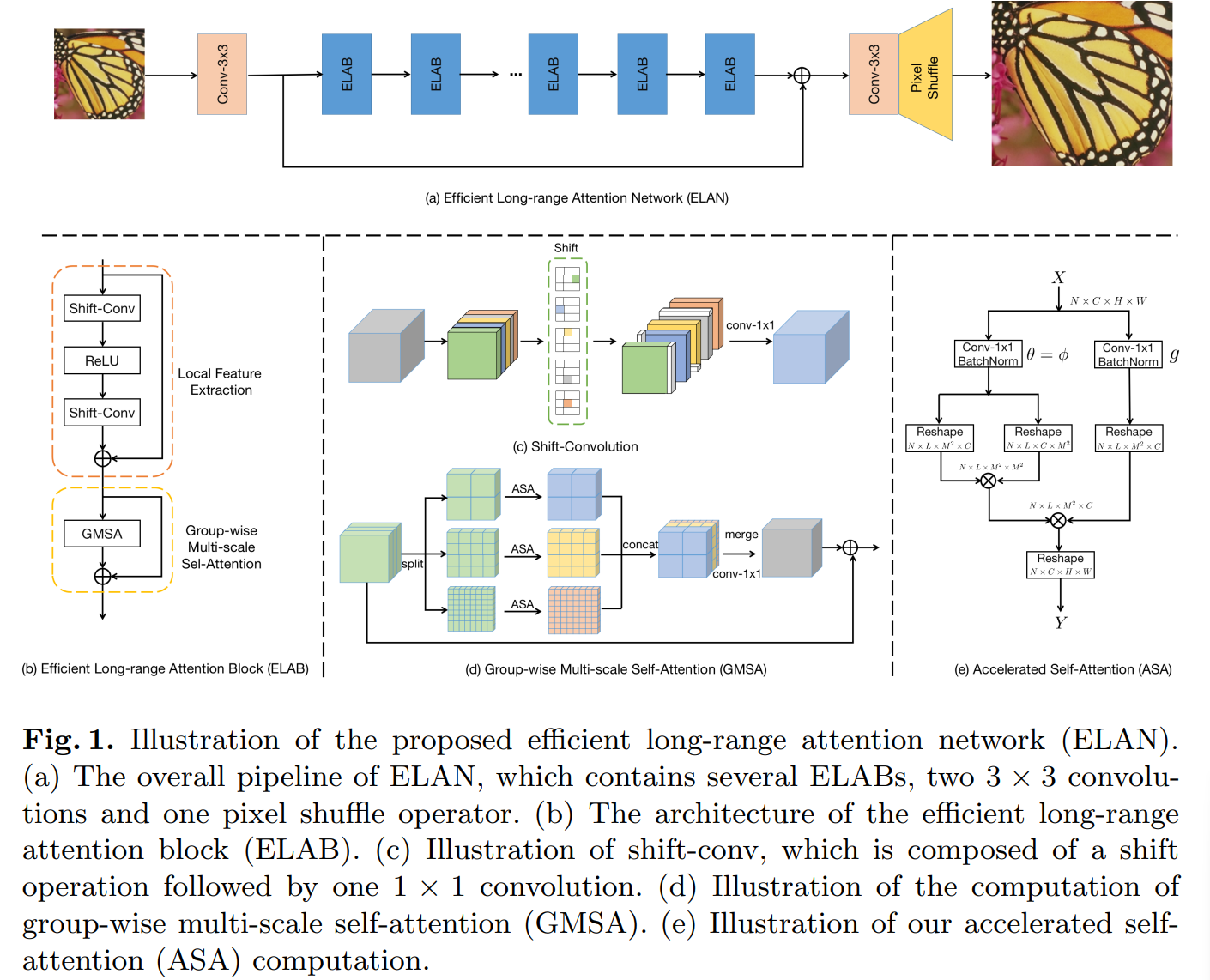
3.1 ELAN 的整体流程
ELAN 的流程如图 1(a) 所示,它由三个模块组成:浅层特征提取、基于 ELAB 的深度特征提取和 HR 图像重建。
该网络遵循一个相当简单的拓扑结构,在输入 HR 重建模块之前,从浅层特征提取模块到深层特征提取模块的输出具有全局快捷连接。
具体来说,给定退化的 LR 图像 Xl ∈ R3×H×W,其中 H 和 W 分别是 LR 图像的高度和宽度,我们首先应用浅层特征提取模块,用 HSF (·) 表示,它包括只有一个3×3的卷积,提取局部特征 Xs ∈ RC×H×W :Xs = HSF (Xl) (1) 其中C是中间特征的通道数。Xs然后进入深度特征提取模块,用HDF(·)表示,由M个级联的ELAB组成。即:Xd = HDF(Xs), (2)
其中 Xd ∈ RC×H×W 表示输出。通过以Xd和Xs作为输入,将HR图像Xh重建为:Xh =HRC(Xs +Xd),(3)其中HRC为重建模块。重建模块的设计有一些选择[11,12,47,29]。为了实现高效率,我们只需使用单个 3 × 3 卷积和像素洗牌操作即可构建它。ELAN 可以使用常用的 SR 损失函数进行优化,例如 L2 [11, 20, 48, 49]、L1 [22, 29, 62] 和感知损耗 [16, 45]。为简单起见,给定 N 个真实心率图像 {Xt,i}Ni=1,我们通过最小化像素级 L1 损失来优化 ELAN 的参数:1 XNL = NT亚当优化器 [21] 用于优化我们的 ELAN,使其在低级视觉任务中的良好性能。
3.2 Efficient Long-range Attention Block (ELAB)
如图 1(b) 所示,我们的 ELAB 由一个局部特征提取模块和一个分组多尺度注意力(GMSA)模块组成,都配备了残差学习策略.
局部特征提取。
给定中间特征 X,以往的研究大多通过多层感知或两个级联的 1×1 卷积来提取局部特征,但它们只有 1×1 的感受野。为了扩大感受野以更有效地提取局部特征,我们使用两个 shift-conv [56],它们之间有一个简单的 ReLU 激活。如图 1© 所示,shift-conv 由一组移位操作和一个 1×1 卷积组成。
具体来说,我们将输入特征平均分为五组,前四组特征沿不同的空间维度移动,包括左、右、上、下,而最后一组保持不变。因此,接下来的 1×1 卷积可以利用来自相邻像素的信息。在不引入额外的可学习参数和大量计算的情况下,shift-conv 可以提供更大的感受野,同时保持与 1×1 卷积几乎相同的算术复杂度。
Group-wise 多尺度自注意力 (GMSA)。
给定 C × H × W 的特征图,使用 M×M 非重叠窗口的基于窗口的自注意力 [35, 28] 的计算复杂度为 2M2HWC。窗口大小 M 决定了 SA 计算的范围,较大的 M 有助于利用更多的自相似信息。然而,直接扩大 M 将二次方地增加计算成本和资源。为了更有效地计算远程 SA,我们提出了 GMSA 模块,如图 1(d) 所示。我们首先将输入特征 X 分成 K 组,用 {Xk}Kk=1 表示,然后使用窗口大小 Mk 在第 k 组特征上计算 SA。这样,我们可以通过设置不同窗口大小的比例来灵活地控制计算成本。例如,假设 K 组特征被 KC 个通道平均分割,则 K 组 SA 的计算成本是 K2 (Pk Mk2)HWC。然后通过 1×1 卷积连接并合并在不同组上计算的 SA。
加速自注意力 (ASA)。
在现有的变压器模型中,SA 的计算是计算和内存密集型的 [7,35,28,55]。我们做了一些修改来加速 SA 的计算,特别是在推理阶段。首先,我们放弃了在以前的变压器模型 [7、35、28、55] 中广泛采用的层归一化(LN),因为 LN 将 SA 的计算分割成许多不友好的元素操作进行有效推理。相反,我们利用批量归一化 (BN) [19] 来稳定训练过程。值得一提的是,BN 可以合并到卷积运算中,不会在推理阶段造成额外的计算成本。其次,SwinIR [28] 中的 SA 是在嵌入式高斯空间上计算的,其中三个独立的 1×1 卷积(用 θ、φ 和 g 表示)用于将输入特征 X 映射到三个不同的特征图中。我们设置 θ = φ 并在对称嵌入高斯空间 [30, 5] 中计算 SA,这可以在每个中节省一个 1 × 1 卷积SA。这种修改在不牺牲 SR 性能的情况下进一步减轻了 SA 的计算和内存成本。我们的 ASA 如图 1(e) 所示。
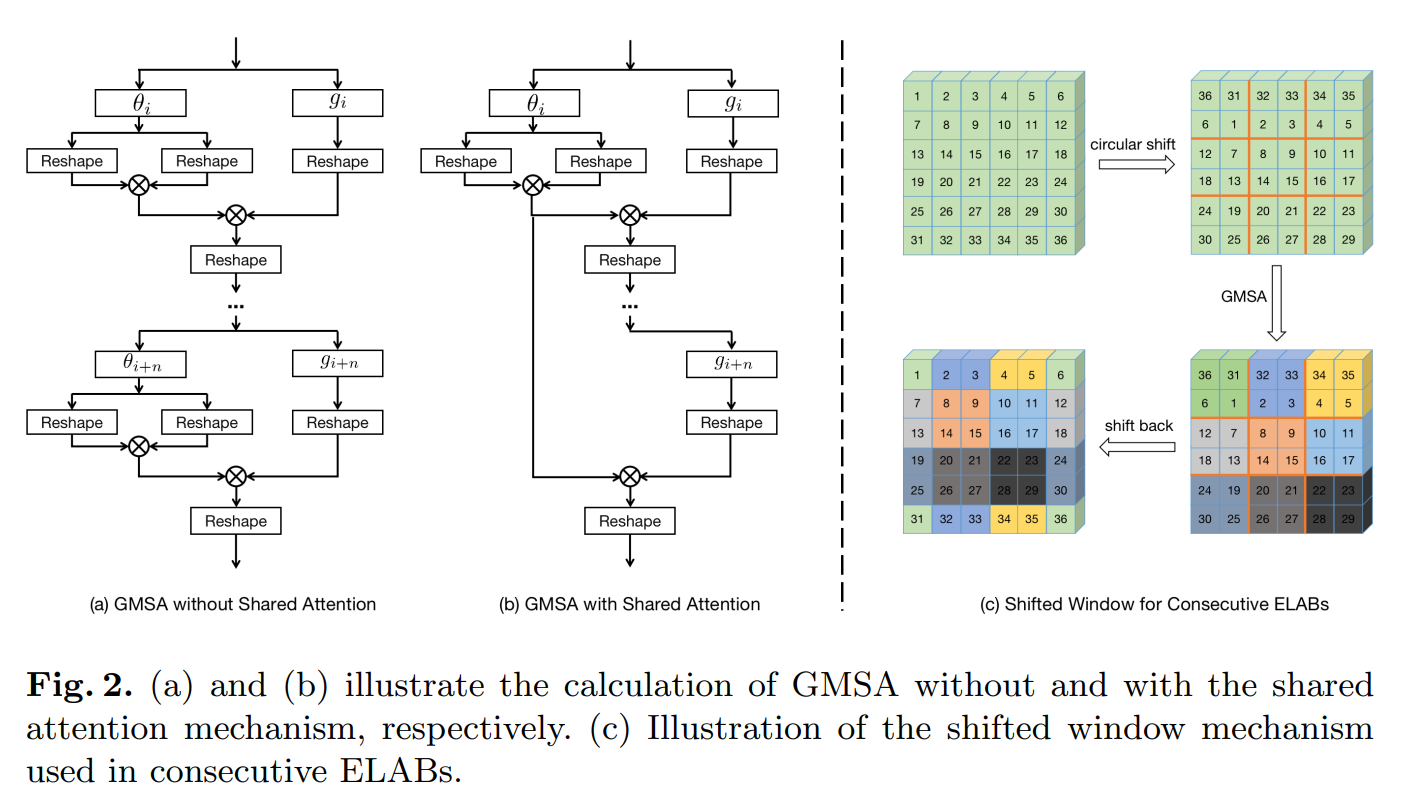
Shared attention。
尽管有上述加速,SA 的一次前向传递仍然包含两个 1×1 卷积和四个 IO 密集型重塑操作。虽然 reshape 操作是无 FLOPs 的,但由于 SR 任务中的大特征尺寸,它很耗时。为了进一步加速整个网络的 SA 计算,我们建议在相邻的 SA 模块之间共享注意力分数。如图 2(b) 所示,第 i 个 SA 模块中计算出的注意力分数直接被后续 n 个相同规模的 SA 模块重复使用。这样,我们可以避免对接下来的 n 个 SA 进行 2n 次重塑和 n 次 1×1 卷积操作。我们发现所提出的共享注意机制仅通过使用少量 n(例如 1 或 2)导致 SR 性能略有下降,同时在推理期间节省了大量计算资源。
Shifted window。
在分组多尺度窗口上计算的 SA 仍然缺乏同一尺度内跨局部窗口的连接。我们改进了 SwinIR [28] 的移位窗口机制,为 SR 任务提供了一种简单而有效的移位方案。整个过程如图 2© 所示。我们首先沿对角线方向对特征进行循环平移,然后计算平移后特征的 GMSA。然后我们通过逆循环移位将结果移回。窗口大小减半的循环移位导致特征图的新分区,并在先前的 GMSA 模块中引入相邻非重叠窗口之间的连接。尽管边界上的一些像素通过循环移位被转移到远处的区域,但我们发现它对最终 SR 性能的影响可以忽略不计,因为这些像素在 SR 任务中只占整个特征图的一小部分。得益于循环移位机制,我们去除了 SwinIR [28] 中采用的屏蔽策略和相对位置编码,使我们的网络更整洁、更高效。
4实验
在本节中,我们进行了广泛的实验,以定量和定性地验证我们的ELAN在五个SR基准数据集上用于轻量级和经典SR任务的卓越性能。我们还提出了全面的消融研究,以评估我们提出的ELAN.
4.1实验设置
数据集和评估指标的设计。
我们使用带有800张训练图像的DIV2K数据集[51]来训练我们的ELAN模型,并使用五个基准数据集,包括Set5[3],Set14[59],BSD100[38],Urban100[17]和Manga109[39]进行性能比较。PSNR和SSIM作为评估指标,在将RGB转换为YCbCr格式后在Y通道上计算。为了进行效率比较,我们报告了在单个 NVIDIA 上评估的延迟推理阶段的 2080Ti GPU。我们还报告了网络参数和 FLOPs 的数量作为参考,尽管它们可能无法忠实地反映网络的复杂性和效率。请注意,由于一些竞争方法没有发布源代码,我们只能复制它们的 PSNR/ SSIM 来自原始论文,但无法报告其延迟和 FLOPS 的结果。
训练细节。
在 SwinIR [28] 之后,我们训练了两个具有不同复杂性的 ELAN 版本。轻量级版本,即 ELAN-light 由 24 个 ELAB 和 60 个通道组成,而普通版本的 ELAN 由 36 个 ELAB 和 180 个通道组成。我们在窗口大小为 4 × 4、8 × 8 和 16 × 16 的三个等分尺度上计算 GMSA。默认情况下,我们为共享注意机制设置 n = 1。双三次下采样用于生成训练图像对。我们从 LR 图像中随机裁剪 64 个大小为 64×64 的补丁和 32 个大小为 48×48 的补丁,分别作为轻量级和普通 ELAN 模型的训练小批量。我们采用随机旋转 90°、180°、270° 和水平翻转来增强数据。两个模型都使用 ADAM 优化器训练,其中 β1 = 0.9、β2 = 0.999 和 ε = 10−8,持续 500 个时期。学习率初始化为 2 × 10−4,并在第 {250, 400, 425, 450, 475} 轮后乘以 0.5。模型训练由 Pytorch [42] 在 NVIDIA 2080Ti GPU 上进行。
4.2 与轻量级 SR 模型的比较
我们首先将我们的 ELAN-light 与最先进的轻量级 SR 模型进行比较,包括基于 CNN 的模型CARN[2]、IMDN[18]、LAPAR-A[25]、LatticeNet[37],以及基于变换器的模型 ESRT[36] 和 SwinIR-light[28]。
定量比较。
表 1 报告了不同方法的定量指标。从表中可以得出几个观察结果。首先,与类似ELAN-light相对于SwinIR-light的优势是使用更少的计算成本实现的,正如我们在表1.4.3中验证的那样 与传统SR模型的比较为了验证ELAN的可扩展性,我们进一步将ELAN的普通版本与最先进的经典面向性能的SR模型进行了比较,包括EDSR [29],SRFBN [27],RNAN [61],RDN [62],RCAN [31], SAN [10], IGNN[64],HAN [41],NLSA [40]和SwinIR [28]。请注意,这些模型采用具有大通道数的非常深的网络拓扑或复杂的自我注意和非本地策略。
定量比较。
定量结果如表2所示。可以看出,我们的ELAN在几乎所有基准和所有升级因素上都取得了最佳结果。特别是,与 SwinIR 相比,我们的 ELAN 在几乎所有设置上都获得了更好的 PSNR 和 SSIM 索引,参数和 FLOP 数量更少,推理速度提高了 ×2 以上。这些性能收益表明,所提出的 ELAB 块成功地捕获了有用的信息(例如远程依赖),从而以更高效和有效的方式进行超分辨率。尽管经典的基于 CNN 的 SR 模型具有大量参数和 FLOP,但它们的性能不如基于 Transformer 的模型具有竞争力。与大多数基于 CNN 的方法相比,我们的 ELAN 在重建性能指标方面显示出显着优势,受益于其更大的感受野和建模远程空间特征相关性的能力。 HAN 和 NLSA 等一些方法也可以通过利用专用注意力机制和非常深的网络来获得有竞争力的性能,但它们的计算和内存成本非常昂贵。例如,×2 放大任务的 NLSA 模型太重,无法在单个 NVIDIA 2080Ti GPU 上执行。尽管如此,我们的 ELAN 以更少的成本获得了比这些复杂的基于 CNN 的模型更好的性能。
定性比较。
我们比较了 ELAN 和六个代表性模型的 SR 结果的视觉质量,包括 EDSR [29]、RDN [62]、SAN [10]、RCAN [62]、IGNN [27] 和 SwinIR [28],×4升级任务。图 5 和图 6 显示了六个示例图像的结果。首先可以观察到,大多数比较方法产生的边缘和纹理要么模糊,要么不准确(参见图 5 中老虎身体的皮毛纹理和图 6 中的裙子),而我们的 ELAN 可以恢复更准确和更锐利的边缘。 ELAN 的优势在具有重复图案和边缘的图像上更为明显(参见图 5 的第 2 和第 3 个图像以及图 6 的第 1 个图像)。大多数比较方法都无法重建正确的结构,甚至会产生不需要的伪影。基于变换器的方法,如 SwinIR [28] 可以重现“img092”和“img003”中的大部分图案和边缘,但也会受到“img062”和“img092”中的伪影和失真的影响。相比之下,我们的 ELAN 可以在这些示例中恢复非常清晰的图案和边缘。参考图 6 中的最后一个示例,其中汉字由多个方向的密集笔画组成,我们的 ELAN 是唯一可以在所有笔画中再现不同边缘的模型。这些比较清楚地证明了 ELAN 在从低分辨率输入中恢复图像结构和细节方面的优势。
4.4 消融研究
为了更好地了解ELAN的工作原理,我们提出了全面的消融螺柱,以评估ELAN不同组件的作用,以及共享注意力机制的深度选择。
ELAN的组件。
我们首先利用ELAN-light的架构和设置来消融ELAB不同组件的作用,并观察性能和效率的变化。表3报告了五个基准的PSNR/SSIM指数和变体模型的推理时间。还列出了SwinIR-light的索引以供参考。具体来说,我们从天真的基线开始,从SwinIR-light中删除冗余的子分支,其中深度特征提取模块由24个连续的swin变压器块组成。正如预期的那样,这种简化会导致轻微的性能与SwinIR-light相比有所下降,同时将延迟从271ms降低到247ms。通过利用我们的移位窗口机制,性能几乎保持不变,而推理速度从 247ms 降低到 177ms。然后,我们将SA计算替换为我们提出的ASA,推理延迟从177ms大大降低到66ms,而不会损失PSNR / SSIM性能。通过采用能够有效模拟长期不确定性的GMSA,PSNR和SSIM指数在所有五个数据集上都得到了显着改善。具体来说,在 your- ban100 和 Manga109 数据集上的 PSNR 分别增加了 0.21dB 和 0.19dB,而延迟仅略微增加了 9 毫秒。这表明GMSA在SwinIR中对SA的有效性,具有较小的固定窗口尺寸。最后,通过采用提议的共享注意机制,我们可以进一步加快ELAN-light的推理时间,而性能下降很小。结合所有改进,ELAN-light的最终版本实现了约×4.5的加速度,同时保持了与SwinIR-light相当的性能。
Depth of shared attention.
我们进一步对顺序层中共享注意力块(即图2(b)中的n)的深度进行了详细的消融研究。本研究采用ELAN-light,共享注意力块的深度在{0,1,3,5}中变化。请注意,n = 0 表示每个 ELAB 计算独立自我关注。使用不同n的ELAN-light结果报告在表4中。我们还提供了一种具有代表性的基于CNN的方法EDSR基线,以进行直观比较。可以观察到,使用较大的 n 可以有效减少推理阶段的网络参数、FLOP 和延迟时间的数量,但代价是性能下降。通过选择合适的n,我们的ELAN可以在效率和性能之间实现良好的权衡。值得一提的是,即使使用n = 5,ELAN-light在具有挑战性的Urban100和Manga109上的PSNR仍然远远超过EDSR基线。裕量(分别高达0.31 dB和0.28 dB),验证了在我们的模型中对远程注意力进行建模的优势。
5 结论
在本文中,我们提出了一种用于单幅图像超分辨率的高效远程注意力网络(ELAN)。
ELAN 有一个整洁的拓扑结构,具有顺序级联的高效远程注意力块 (ELAB)。
每个 ELAB 由一个局部特征提取模块和两个连续的 shift-conv 和一个分组多尺度自注意力(GMSA)模块组成,以逐渐增加自注意力(SA)的感受野。
得益于我们加速的 SA 计算和共享注意力机制,ELAB 可以非常有效地捕获局部结构和远程依赖。
广泛的实验表明,ELAN 在轻量级和性能导向设置上可以获得比以前最先进的 SR 模型更具竞争力的性能,同时比以前基于变压器的 SR 方法更经济。
虽然我们的 ELAN 比 SwinIR 实现了显着的加速,但与那些基于 CNN 的轻量级模型相比,SA 的计算仍然是计算和内存密集型的。未来,我们将进一步探索更有效的 SA 实现或近似,用于更多低级视觉任务。
这篇关于【论文阅读】ELAN-Efficient Long-Range Attention Network for Image Super-resolution的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







