本文主要是介绍一文带你看懂IM智己CSOP用户数据权益计划,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
日前,智己汽车首度登场上海车展,车展首日,智己汽车正式公布了“豪华纯电智能轿车”智己L7“天使轮版”预售价格及购车福利,其中尤值一提的是“重磅天使轮用户水晶福利”,这是“CSOP用户数据权益计划”为天使轮用户特别定制的专属礼遇。CSOP用户数据权益计划,即IM智己的创始股东将其拥有的4.9%的股权收益,回馈给为IM智己贡献数据的用户。

“两大介质”回馈用户数据价值
水晶:即积分,车主及非车主均可通过参与APP上的互动任务、官方组织的共创活动、或开通使用特定功能来获取“水晶”。“水晶”具有有效期。
原石:是CSOP用户数据权益计划中,用以代表用户数据贡献的符号。当用户签署同意数据权益协议后,其拥有的原石可以兑换智己品牌车辆适配的硬件升级或软件空中升级服务,与公司共享创新发展的成长价值。“原石”数量恒定共3亿枚。
“两大方式”确保数据权益获取途径,丰富有趣
养成式开采:用户参与IM智己官方组织的共创活动,或完成APP上的互动任务,赢得积分“水晶”,使用一定数量的“水晶”抽取“智己矿箱”,赢取各种礼品,购车用户有机会获得数据权益“原石”或“原石碎片”,该部分“原石”占总量30%。

里程式开采:购车用户基于日常用车产生授权使用的“车辆与驾驶行为数据”获取“原石”。车主从开始驾驶车辆的那一刻起,就已开启了“里程式开采”模式。在车辆使用过程中,基于先进的智能合约技术,原石将以一个约定的速度随机掉落。该部分“原石”占总量70%,原石产出将遵循“四年减半”原则。

“两种数据”在行业内率先明确用户数据驱动公司价值成长的边界
“日常行驶数据”:IM智己采用Data-Driven(数据驱动)技术路线。在获得用户授权的前提下,海量累积的用户“日常行驶数据”将驱动智己汽车产品,用更全面、高效的方式,解决日常驾驶中的长尾场景,从而让用户的智能驾驶体验获得阶跃式的提升,摆脱对智能驾驶的不信任和紧张感,建立起对IM智己产品的充分信任。
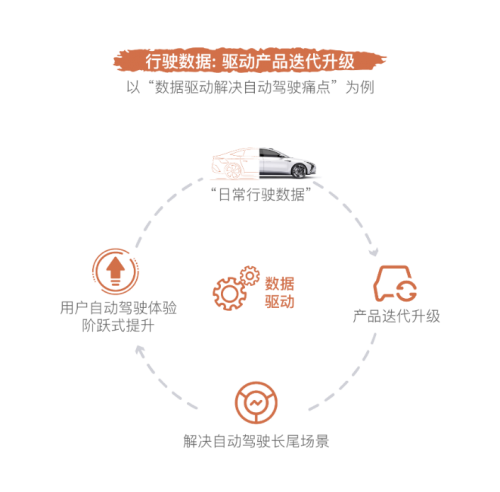
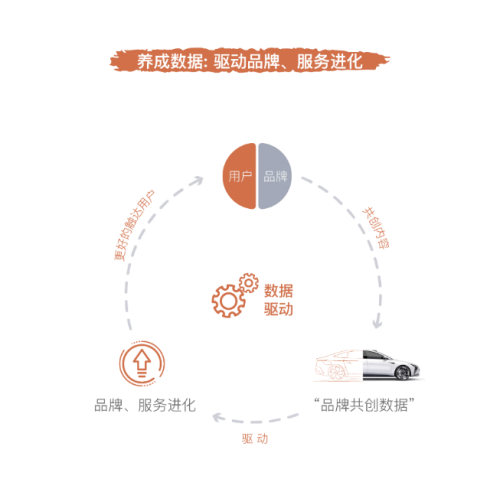
“品牌共创数据”:是IM智己汽车品牌、服务进化的驱动力。这部分数据将帮助智己汽车实时掌握、评估品牌动向、优化品牌定位、加强品牌和用户的内在衔接、加深品牌的用户粘性。IM智己将运用该部分数据形成AI推荐,不断优化品牌的传播内容,从而真正触达用户,达成新颖有趣的沟通。
高科技赋能,保障用户数据与权益安全
IM智己已经制定出IDPP数据隐私及保密计划,将用户数据隐私与安全置于CSOP平台运营的首位,应用包括零知识证明、差分隐私、数据库防火墙技术在内的前沿科技,保护用户数据安全。此外,IM智己还制定了用户数据隐私伦理的监管机制,杜绝采用人脸识别、声纹识别、指纹识别,实现个人信息脱敏。

当下信息化高度发达,数据是极其重要的一项财富,IM智己充分看重并尊重用户的数据价值,“重磅天使轮用户水晶福利”作为CSOP用户数据权益计划为天使轮用户特别定制的专属礼遇,将助力天使轮用户在AI时代数据驱动的赛道中,加速获得数据权益的回馈,和IM智己一起“做时代的合伙人”。
这篇关于一文带你看懂IM智己CSOP用户数据权益计划的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







