本文主要是介绍爬虫自动调用shell通过脚本运行scrapy爬虫(crawler API),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、爬虫时如何同时调用shell
1)终端cd项目>>scrapy crawl example
2)打开example.py
import scrapy
from scrapy.shell import inspect_response#引入shellclass ExampleSpider(scrapy.Spider):name = "example"allowed_domains = ["example.com"]start_urls = ["https://example.com"]def parse(self, response):inspect_response(response,self)#调用parse函数时调用shellpass3)终端cd项目>>scrapy crawl example
运行结果:终端运行完会转到shell端
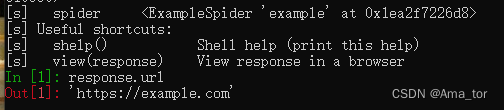
4)退出shell:
>>ctrl+d
二、用脚本调用scrapy
1、补充知识:
一、脚本(script):脚本通常是可直接执行的代码段,由其自身运行。脚本中一般不包含类、函数等
二、模块(module):模块里面定义了各种函数和类。任何Python模块都可以作为脚本执行。
三、包(package):装了一个__init__.py,且含有多个模块的文件夹子。包的本质依然是模块
四、库(library):一个库中可能有多个包,可视为一个完整的项目打包,直接调用或者运行,
2、动态配置API,建立scrapy(免建项目project)
API( Application Programming Interface),它能够帮你实现轻松的和其他软件组件(如服务器,操作系统等)的交互
2.1 scrapy genspider crawl2
2.2修编crawl2.py(代码如下)
2.3python crawl2.py
import scrapy
from scrapy.crawler import CrawlerProcess
#from scrapy.utils.project import get_project_settings
#process = CrawlerProcess(get_project_settings())class Crawl2Spider(scrapy.Spider):name = "crawl2"allowed_domains = ["tianqi.2345.com"]start_urls = ["https://tianqi.2345.com"]def start_requests(self):return [scrapy.Request(url=self.start_urls[0], callback=self.parse)] #def parse(self, response):print(response.url)process = CrawlerProcess({"User-Agent":'Mozilla/5.0 (compatible;'''''')})
process.crawl(Crawl2Spider)
process.start()运行结果:
![]()
3、通过脚本运行project
Core API — Scrapy 2.11.1 documentation(源文档参考)
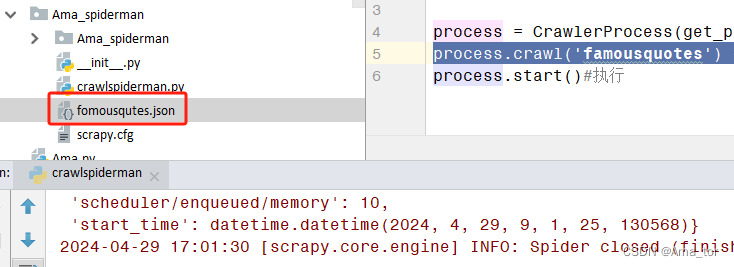
(在项目根目录新建一个crawlspiderman.py文件,运行即可完成一次project的爬虫调用运行,不用再进终端run)
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settingsprocess = CrawlerProcess(get_project_settings())#调用项目内settings
process.crawl('famousquotes') #这里调用上一章已有的爬虫文件
process.start()#执行运行结果:
这篇关于爬虫自动调用shell通过脚本运行scrapy爬虫(crawler API)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





