crawler专题

转:cygwin简单应用及Nutch之Crawler工作流程
cygwin简单应用: cygwin home 目录: ls / -- 根目录 ls /cygdrive -- 查看本地操作系统的盘符,如c盘、d盘 pwd -- 当前位置路径 /home/zf
Elasticsearch:Open Crawler 发布技术预览版
作者:来自 Elastic Navarone Feekery 多年来,Elastic 已经经历了几次 Crawler 迭代。最初是 Swiftype 的 Site Search,后来发展成为 App Search Crawler,最近又发展成为 Elastic Crawler。这些 Crawler 功能丰富,允许以稳健而细致的方式将网站数据导入 Elasticsearch。但是,如果用户想在
爬虫自动调用shell通过脚本运行scrapy爬虫(crawler API)
一、爬虫时如何同时调用shell 1)终端cd项目>>scrapy crawl example 2)打开example.py import scrapyfrom scrapy.shell import inspect_response#引入shellclass ExampleSpider(scrapy.Spider):name = "example"allowed_domains = ["

ML-Agents案例之Crawler
本案例源自ML-Agents官方的示例,Github地址:https://github.com/Unity-Technologies/ml-agents 本文基于我前面发的两篇文章,需要对ML-Agents有一定的了解,详情请见:Unity强化学习之ML-Agents的使用、ML-Agents命令及配置大全。 参考资料:ML-Agents(十)Crawler 上一次运行的3DBall的任务比

爬虫工作量由小到大的思维转变---<第六十九章 > Scrapy.crawler模块中的异常
前言: 继续上一章: 爬虫工作量由小到大的思维转变---<第六十八章 > scrapy.utils模块中的异常-CSDN博客 Scrapy.crawler模块是Scrapy框架的核心之一,它负责管理和控制整个爬虫的生命周期。该模块提供了各种工具和功能,以便开发者可以配置和运行爬虫、处理请求和响应、解析数据以及生成输出等。它是构建Scrapy爬虫的基础,为高效地执行爬虫任务提

爬虫(Web Crawler)逆向技术探索
实战案例分析 为了更好地理解爬虫逆向的实际应用,我们以一个具体的案例进行分析。 案例背景 假设我们需要从某电商网站上获取商品价格信息,但该网站采取了反爬虫措施,包括动态Token和用户行为分析等。 分析与挑战 动态Token:该网站在每次请求中都会生成一个动态的Token,用于验证用户身份和请求合法性。这意味着简单地发送请求无法成功获取数据。 用户行为分析:网站可能会监控用户的访问行为,

爬虫(Web Crawler)介绍与应用
## 摘要 本文将介绍什么是爬虫(Web Crawler)以及其在信息抓取、数据分析等领域的应用。我们将深入探讨爬虫的工作原理、设计特点以及开发过程中需要考虑的关键问题。 ## 一、什么是爬虫 爬虫是一种自动化程序或脚本,用于从互联网上抓取信息并进行处理。它通过访问网页、解析内容、提取信息等方式,实现数据的自动化收集和处理。 ## 二、爬虫的工作原理 1. **URL收集与调度**:爬虫

CHAPTER 9: 《DESIGN A WEB CRAWLER》第9章 《设计一个web爬虫》
CHAPTER 9: 《DESIGN A WEB CRAWLER》第九章 设计一个web爬虫 在本章中,我们将重点介绍网络爬虫设计:一种有趣而经典的系统设计 面试问题。 网络爬虫被称为机器人或蜘蛛。它被搜索引擎广泛用于发现网络上的新内容或更新内容。内容可以是网页、图像、视频、PDF文档等。网络爬虫首先收集一些网页,然后跟踪这些网页上的链接页面以收集新内容。图 9-1 显示了爬网过程的直观示例。
Become.com的 Web Crawler: 一个超大规模的Java应用程序(想开发自己的搜索引擎增值服务的必读)
原文地址:http://java.sun.com/developer/technicalArticles/WebServices/become/?feed=JSC 1 Become.com准备开发他们的第二代搜索引擎。他们曾经花了一年的时间开发了一个C++版本的web crawler ,但是有明显的内存和线程问题。 2 现在他们决定用java重新开发这个引擎。两个开发者,花了3个月,就构建
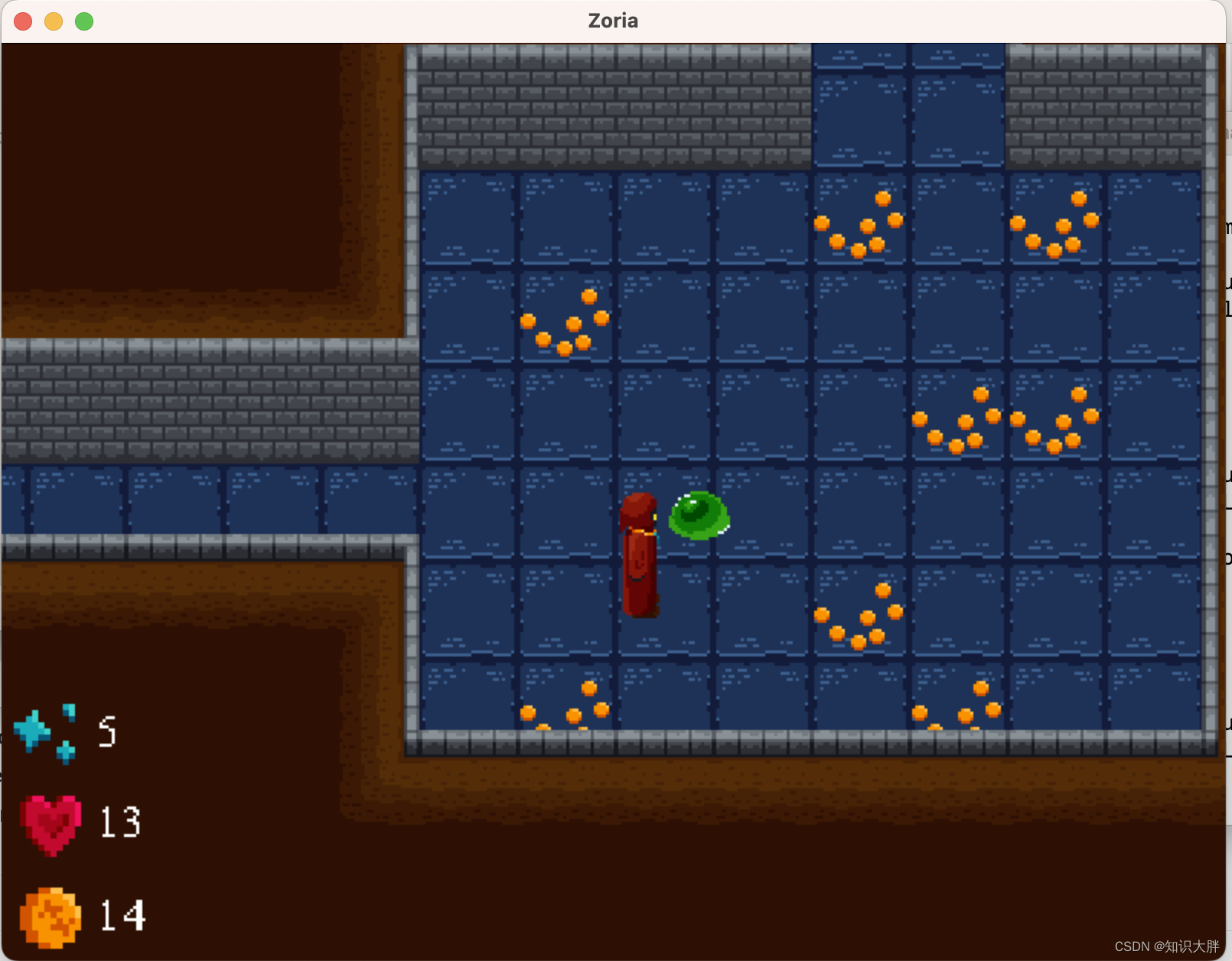
Python游戏开发之Dungeon Crawler 游戏源码大全
源码一 功能: WASD 移动 SPACE 攻击 SHIFT 使用楼梯 介绍 每个级别都包含一把钥匙和一个上锁的舱口。收集钥匙以解锁通往下一层的通道(SHIFT解锁)。 史莱姆造成的伤害最小,但每一层都会产生更多。他们可以降低健康或 XP。更多 XP = 每次攻击造成更多伤害。硬币目前没有用。 水平是无限的和持久的。唯一的限制是您的 RAM。世界在死亡时重置。 运行方式 pytho

App Crawler使用教程
写在前面的话: 今年因为疫情,公司各个状况都变了,降薪、改变方向 都有。以前不重视的APP现在一下子史无前例的重视起来。还有就是时间紧张过程混乱下,如果保证最后一关,一月送审9个版本,有2个版本明显crash问题。 整的我筋疲力尽,这不,为了就会这2天的版本,临时把所有自动化的都弄上了。明天加班把选车遍历(352个品牌、1500个车系,近5K次的点击)搞出来了,用的python+appium 给

scrapy crawler - 爬虫小记
最近熟悉了一波爬虫,挺有用的,推荐入门资料如下: 【视频资料】: Python Scrapy Tutorial - YouTube2018年最新Python3.6网络爬虫实战廖xf商业爬虫 (太多了,只能看小部分,不过确实很细)当然如果不想写代码也是ok的,搜一搜八爪鱼,后羿采集器等类似app都挺方便好用的,可满足日常简单需求。 【书籍资料】: 还是推荐大神 崔庆才 的书 【学习总结】基

crawler_exa4
优化中... #! /usr/bin/env python# -*- coding:utf-8 -*-# Author: Tdcqma'''获取漏洞目标站点:绿盟安全漏洞通告v1.0:由于网站结构存在变更的可能性,一旦爬虫爬取的页面发生变化则会影响正则表达式的匹配,导致爬虫失效。为了解决这个问题重新架构该爬虫,新的爬虫将分3个部分,即:【1】信息收集:一旦网站结构发生变化只需要更改此部分的
GPT-Crawler一键爬虫构建GPTs知识库
GPT-Crawler一键爬虫构建GPTs知识库 写在最前面安装node.js安装GPT-Crawler启动爬虫结合 OpenAI自定义 assistant自定义 GPTs(笔者用的这个) 总结 写在最前面 GPT-Crawler一键爬虫构建GPTs知识库 能够爬取网站数据,构建GPTs的知识库,项目依赖node.js环境,接下来我们按步骤来安装,非常简单 参考:https:/
Watson Explorer 入门(3):创建搜寻器(crawler,数据爬虫)
(许野平的 Watson Explorer 笔记) 创建集合后,可以看到如下界面: 我们可以看到三个面板:1-搜寻与导入;2-解析和索引;3-搜索和内容分析。本练习讨论搜寻器的创建和配置,以及如何导入数据。 “搜寻器”的英文是 crawler,俗称爬虫,用于从网络、硬盘等数据源自动抓取数据。因为创建界面很直观,步骤不一一细说了,这里说一下几个需要注意的问题。 数据源问题 前几天在一次

python crawler -利用XPath获取B站推荐视频封面
推荐页封面抓取不需要考虑JS,直接用XPath定位<img>即可。 推荐页url:https://www.bilibili.com/list/recommend/1.html 翻到x页就是x.html 抓取封面,定位到<img>中的src,获取这个src访问下载到本地就行了。 用XPath获取src路径: "//div[@class='zr_recomd']/ul/li/div/a/img/@s

python yellow page thread crawler
把之前的爬虫用python改写了,多线程和队列 来抓取,典型的生产者消费者模式 ,用mvc分层来写的 #-*- coding: utf-8 -*-''' spider.pyCreated on 2013-12-21http://www.cn360cn.com/news.aspx?pageno=2@author: Administrator'''import Pagerimpo