本文主要是介绍Alibaba Cloud Linux 与倚天软硬结合,加速数据智能创新,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
根据 IDC 报告统计,通过云满足客户业务的需求,已经大大超过了传统管理基础设施。ECS 作为阿里云的比较关键的产品和服务,需要用自身产品能力满足不同类型的市场需求。阿里云 ECS 首席架构师吴天议在 2023 龙蜥操作系统大会上分享基于龙蜥操作系统 Anolis OS,阿里云采用倚天芯片与 CIPU 构建的面向云原生神龙计算体系架构,如何满足未来智能化的应用的需求。以下为本次分享原文:

(图/阿里云 ECS 首席架构师吴天议)
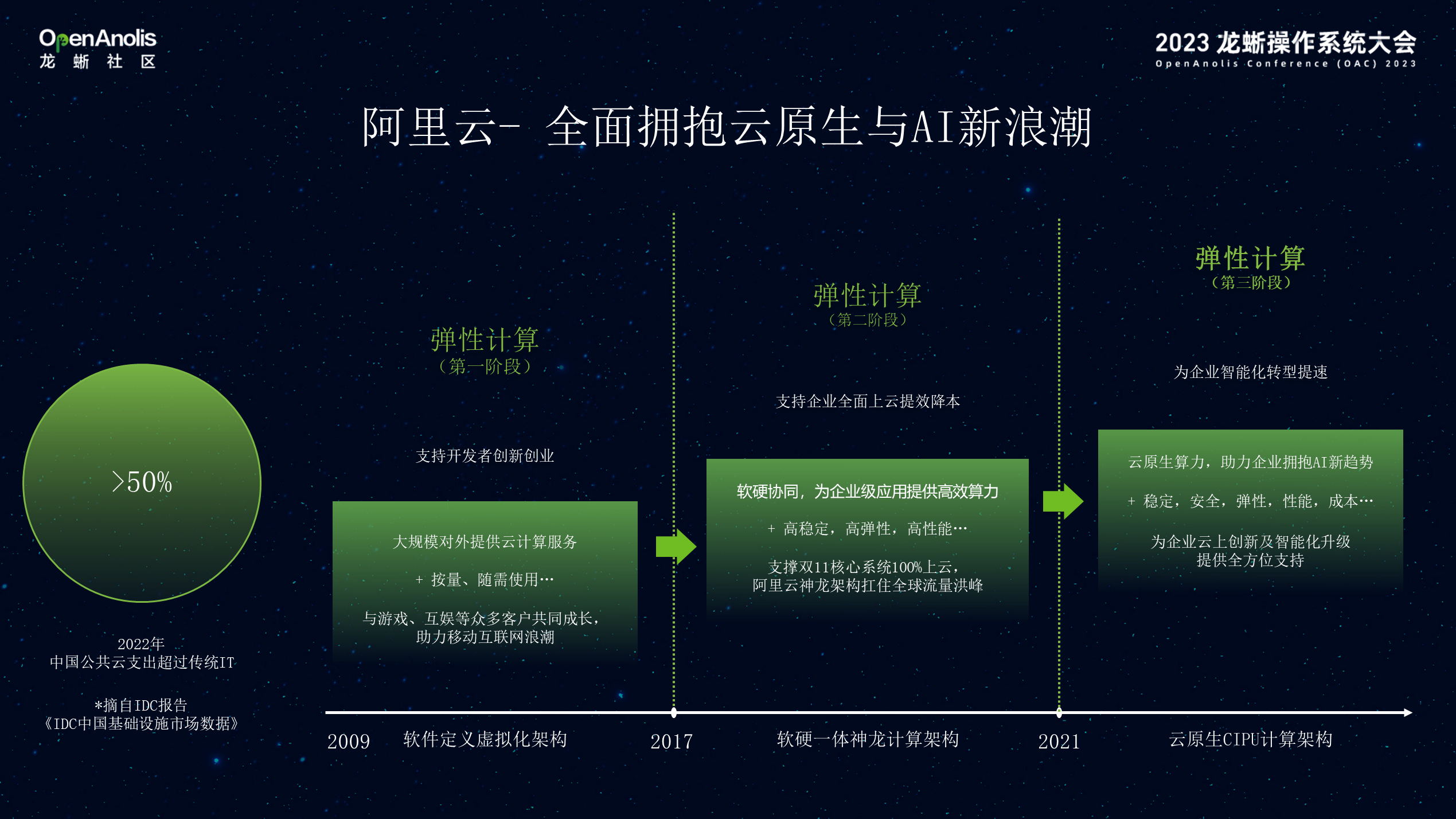
01 ECS 弹性计算的发展历程
截止 2022 年,根据 IDC 报告统计,通过云满足客户业务的需求,已经大大超过了传统管理基础设施。ECS 作为阿里云的比较关键的产品和服务,发展经历了三个阶段,第一个阶段主要满足移动互联网客户突发性的需求。在这个阶段,通过软件实现计算/网络虚拟化,将算力弹性,多租户方式提供给客户。从 2017 年开始主要进入第二个阶段,通过软硬一体的计算架构服务和满足云原生、大数据的要求。第三个阶段,主要从 2021 年开始基于发布了CIPU 的计算架构满足面向智能计算时代算力的需求。
02 未来的 AI 应用应该会变什么样子?
2023 年迎来了 AIGC 应用爆发。AI 作为知识的产生方式,将引领第四次的产业革命。
首先在应用层 , AI 从感知智能到认知智能的提升,将改变原有应用的范式与业务架构会产生翻天覆地的变化。数据类业务的在数据收集、标签、检索、知识向量化等方面需要与 AI 深度融合,通过 AGI 将有更多的知识与信息自动的生产出来。通过 AGI 越来越多的知识和数据,将在云上产生。视频类业务也将会被重塑,今天的短视频/直播本身已经用到 AI 加持的内容鉴别、推荐等能力,图片、视频的内容将更多的由 AI 来参与协助,加快内容的生产速度;AI 作为大脑,最终的视频存储,推送将会消耗等多的算力。在一些新的领域,如基因工程、分子动力学方面也会发掘出更多创新性的应用与做法。
其次,算力将从以标量数据处理通用 CPU 计算为中心,向以围绕数据与模型服务为中心的异构计算迁移。最后,未来的操作系统将不是围绕单机服务器的虚拟化,而是采用基于云构建分布式操作系统,需要实现在不同的计算专利、CPU、TPU 等其他方式的融合调度。在整个内存管理上,跨 CPU 和 GPU 之间的内存管理、通信系统、文件系统各方面都会被重塑。

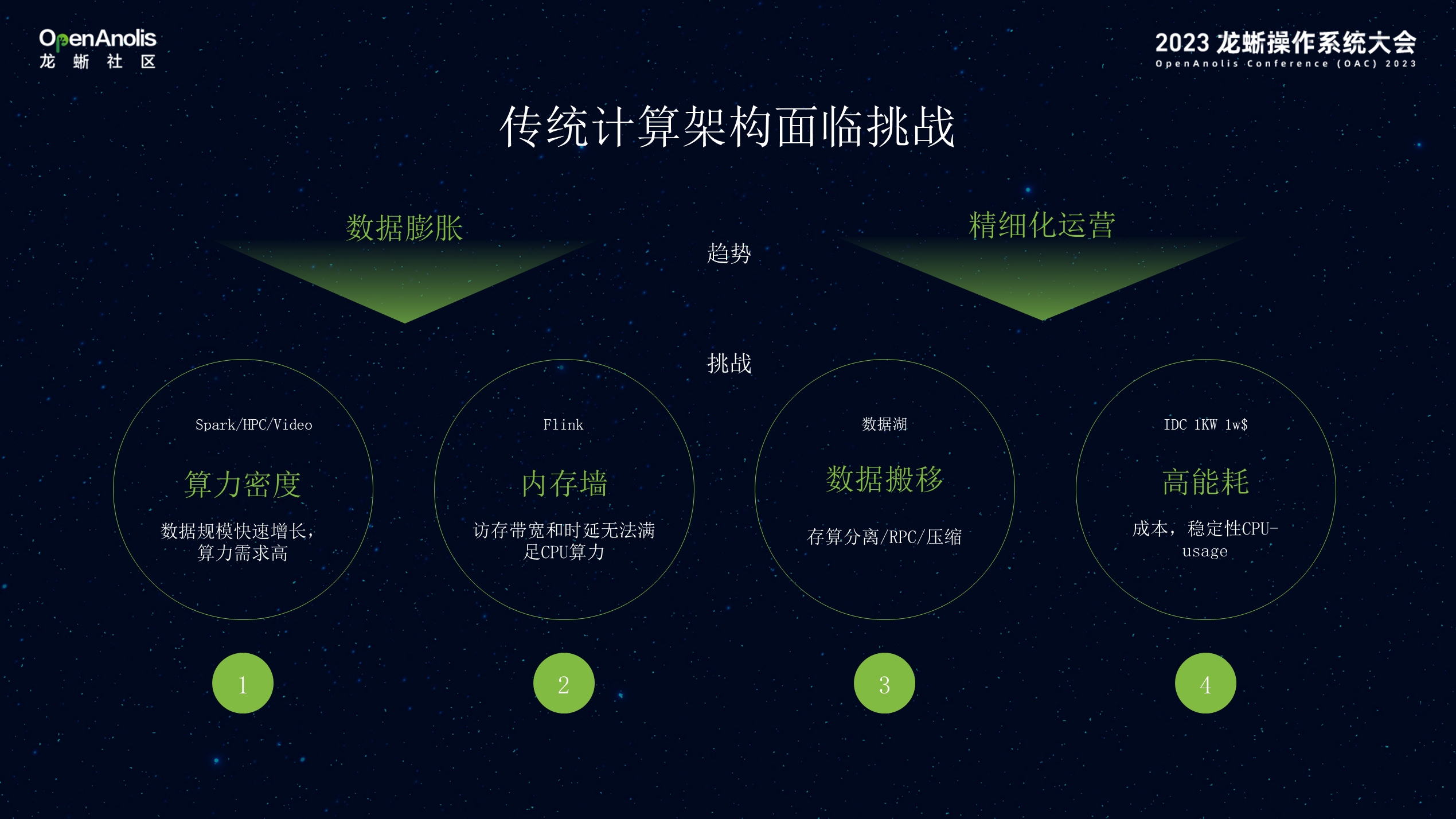
今天大部分的 AI 模型训练,推理工作将越来越多的被 GPU 算力所取代。同时对传统的 CPU 通用计算架构也提出更多的挑战,主要有 4 个方面:首先是算力密度问题。传统互联网主要面向 ToC 的交互式应用,CPU 的负载不高,对于 Spark/Flink/ 视频这类对 CPU 的算力密度与负载要求高;其次,由于 CPU 核数的增加,需要频繁访问内存的应用,需要突破内存墙的限制。第三由于数据的爆炸,业务架构倾向于存算分离,通过分布式 EBS、OSS 进行数据存储,这样会将计算与数据拉远,带来数据搬移的问题。最后是能耗的挑战,IDC 的机柜在建设时能耗是标定的,在部署服务器时,按照一定中等负载进行规划由于分析类业务持续性,IDC 需要的能耗越来越高 。
针对这样的技术挑战,需要构建云原生处理器为解决算力需求:首先 CIPU 实现了算力、网络、存储资源池化,转变原有的芯片视角以 CPU 为中心设计理念,以 CIPU 为中心技术架构。其次是构建云原生处理器。第一需要算力稳定输出,充分考虑现有处理器线程之间算力争抢、降频的问题,通过物理核设计理念、缓存 Qos 等特性。接着软硬协同,通过将网络、存储等 IO 能力卸载到专用处理器,可以有效突破传统物理网卡的性能瓶颈,提供更加优异的网络和存储数据处理能力;最后支持垂直场景加速,为应对客户在特定垂直场景的高性能要求,芯片原生具备垂直场景的加速能力,例如视频、大数据等场景加速特性。
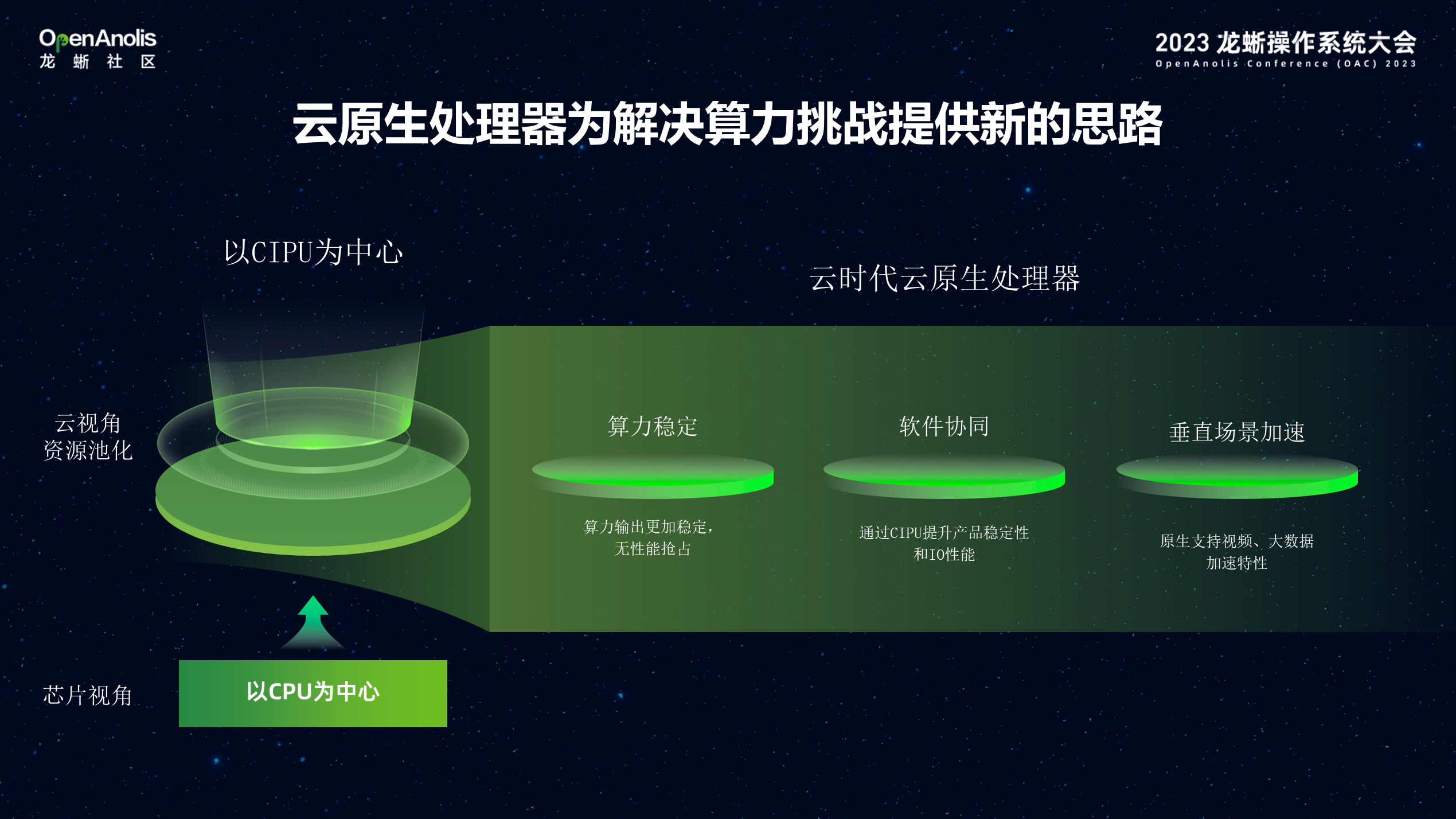
未来的云基础设施,将不仅仅是基于通用 CPU 服务器之上的虚拟化,算力调度;底层以 CIPU-- Cloud Infrastructure Process Unit 为中心,重构云数据中心互联架构、CPU/GPU/FPGA/AISIC 等异构算力组件化部署,与算力、内存互联,通过高性能的 VPC 与 RDMA 网络互联能力,加速计算对数据加载、存储。同时越来越多的客户数据上云,需要实现虚拟化安全隔离,数据加密构建可信计算能力;通过飞天操作系统向提供裸金属、虚拟机、容器、计算集群的能力;服务上层 AI、HPC、大数据等应用。

2021 年阿里巴巴发布自研 Arm 架构倚天 710 CPU。这是阿里第一颗“为云而生”的 CPU,容纳了高达 600 亿个晶体管。它基于 Armv9 架构打造,拥有 128 核,并在全球权威 CPU 基准测试集 SPECint 2017 上拿到了 440 分的超高成绩,超出业界标杆 20%,能效优于业界标杆 50%。

基于倚天 710 CPU,过去的两到三年 ECS 团队经历了三年进行产品打磨。
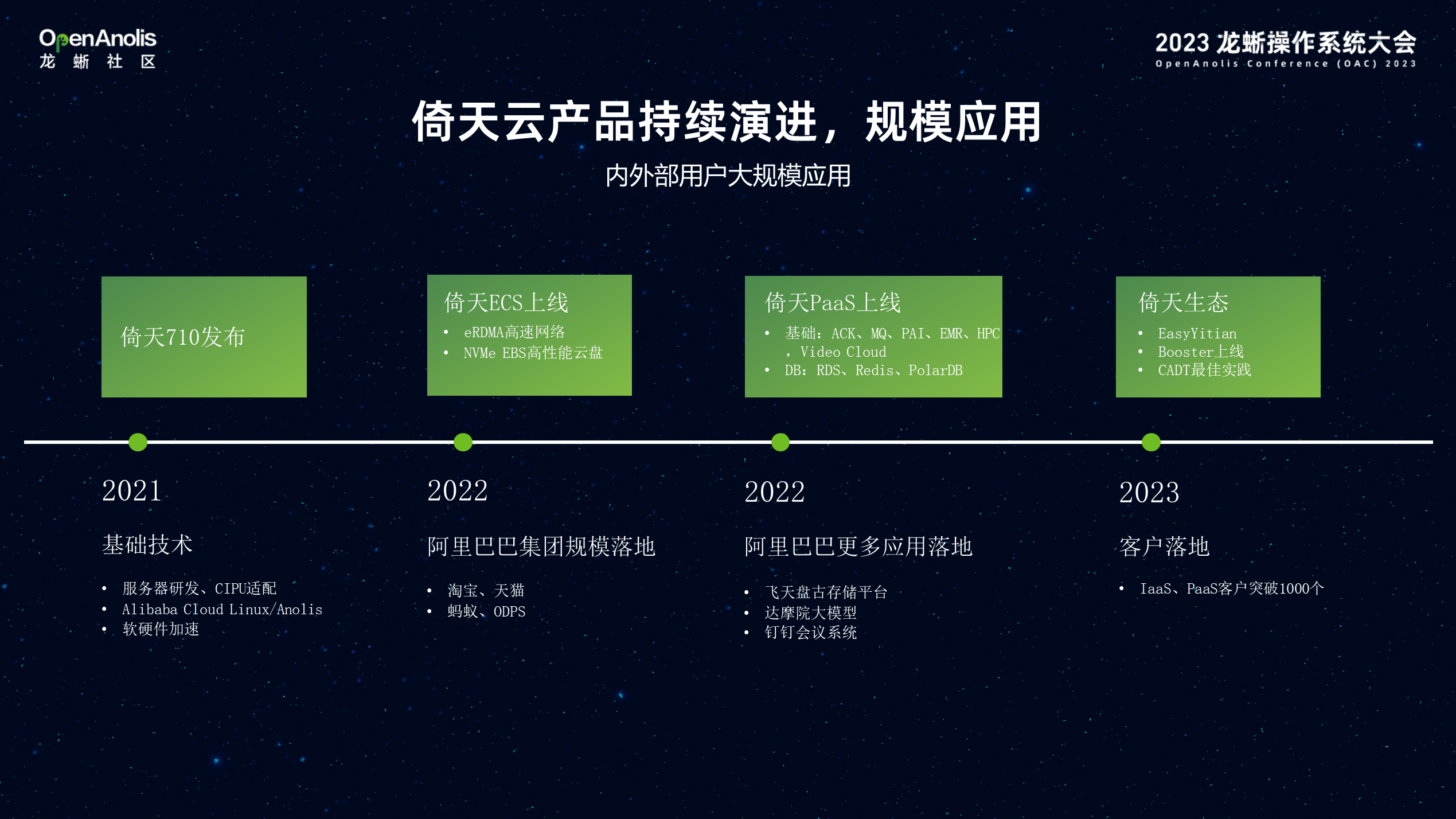
2021 年基于倚天 710 CPU 为基础完成了服务器研发、CIPU 适配,Anolis OS/Alibaba Cloud Linux 软硬件加速推出倚天产品。2022 年完成阿里云内应用落地,包括 ODPS、 RDS、盘古存储平台等,并规模落地到阿里巴巴集团应用,包括 淘宝、天猫、钉钉会议、达摩院大模型等。2023 年已有 1000+ 企业客户,陆续使用阿里倚天产品,达到规模商用。
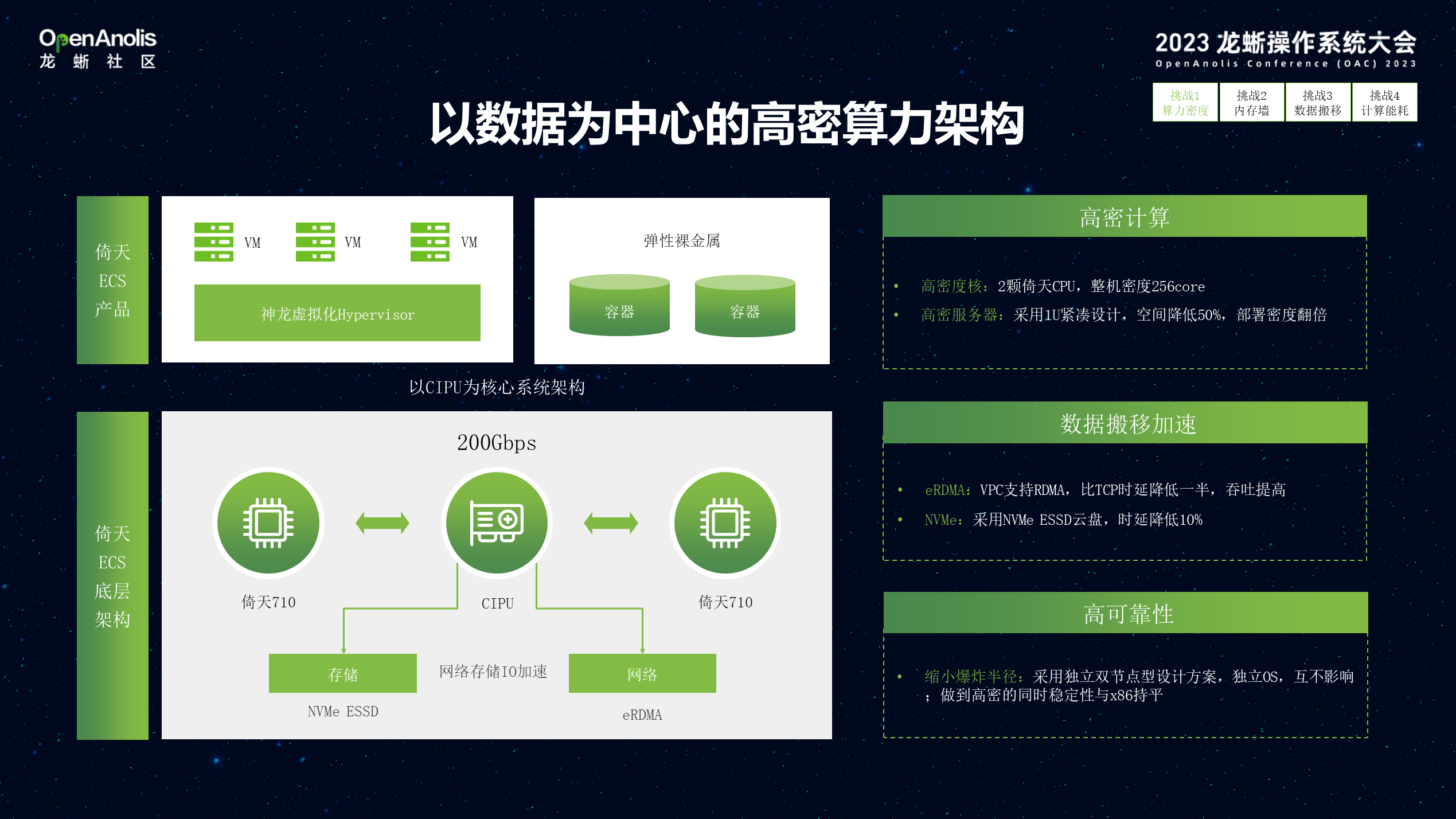
03 倚天面向云原生数据应用的 CPU 架构
下图第一个是面向算力密度的挑战, 我们采用双单路设计,在 1U 的服务器上部署 2 个相互独立的 CPU,这样极大的提升了计算的密度。通过 CIPU 实现 MultiHost 互联,CPU 独立 OS 保证可靠性,两个系统之间共享 io 能力,解决高密度的问题,直接采用 2*100G 物理网络,基于 VPC 网络,不依赖 IB 物理网络即可实现 eRDMA 远程内存访问。
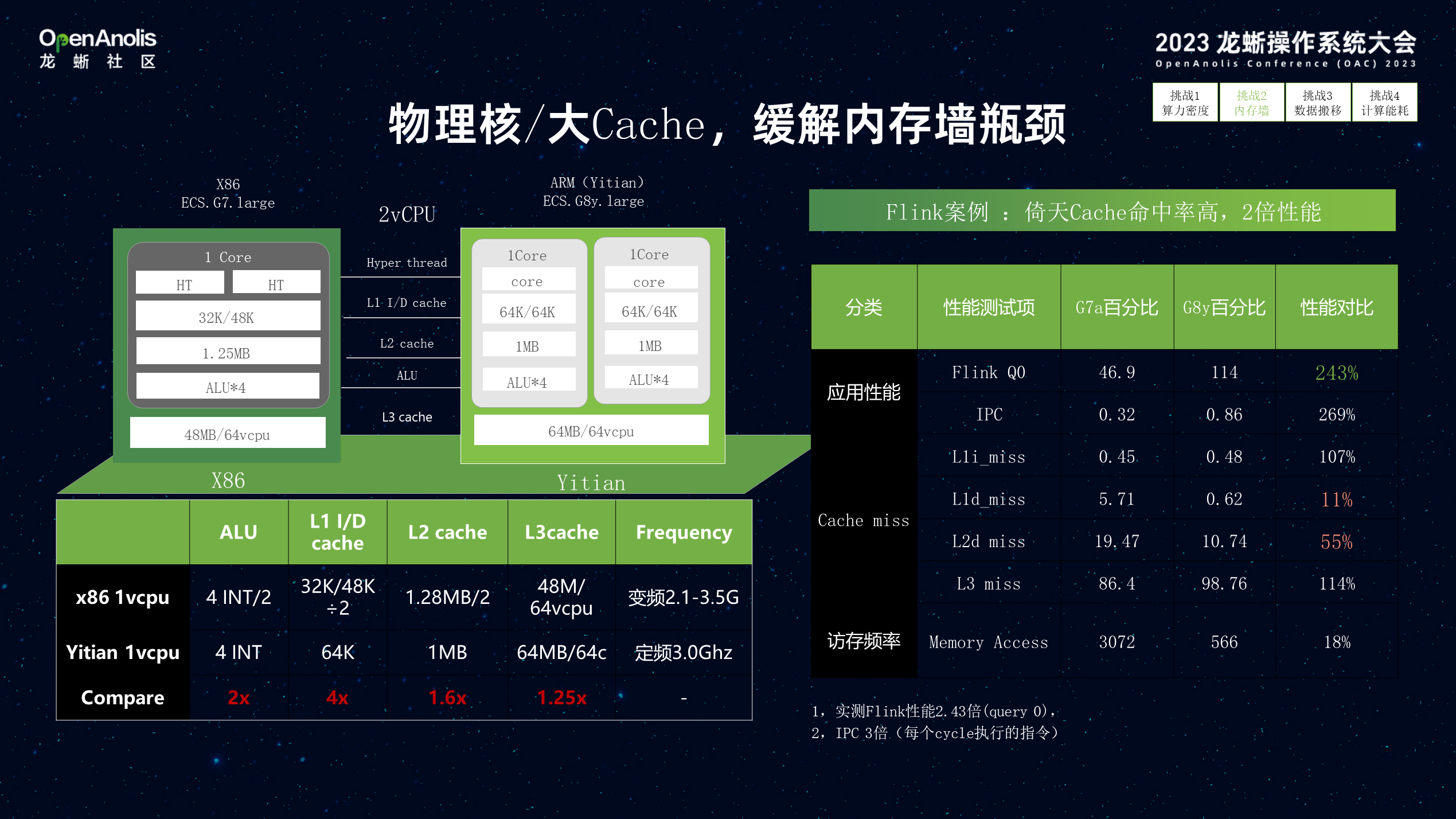
第二个问题是如何面向算力墙的问题。由于倚天 Arm CPU 直接使用物理核,与同代 X86 CPU 相比,在 L1/L2/L3 的 Cache 方面都 1~2 倍以上的提升,同时也极大减少了多核 CPU 对内存通道的争抢。通过这样的优化,对需要大量数据访问的应用,如Flink 比较友好,由于 Cache Miss 的减少,端到端处理性能得到极大提升。
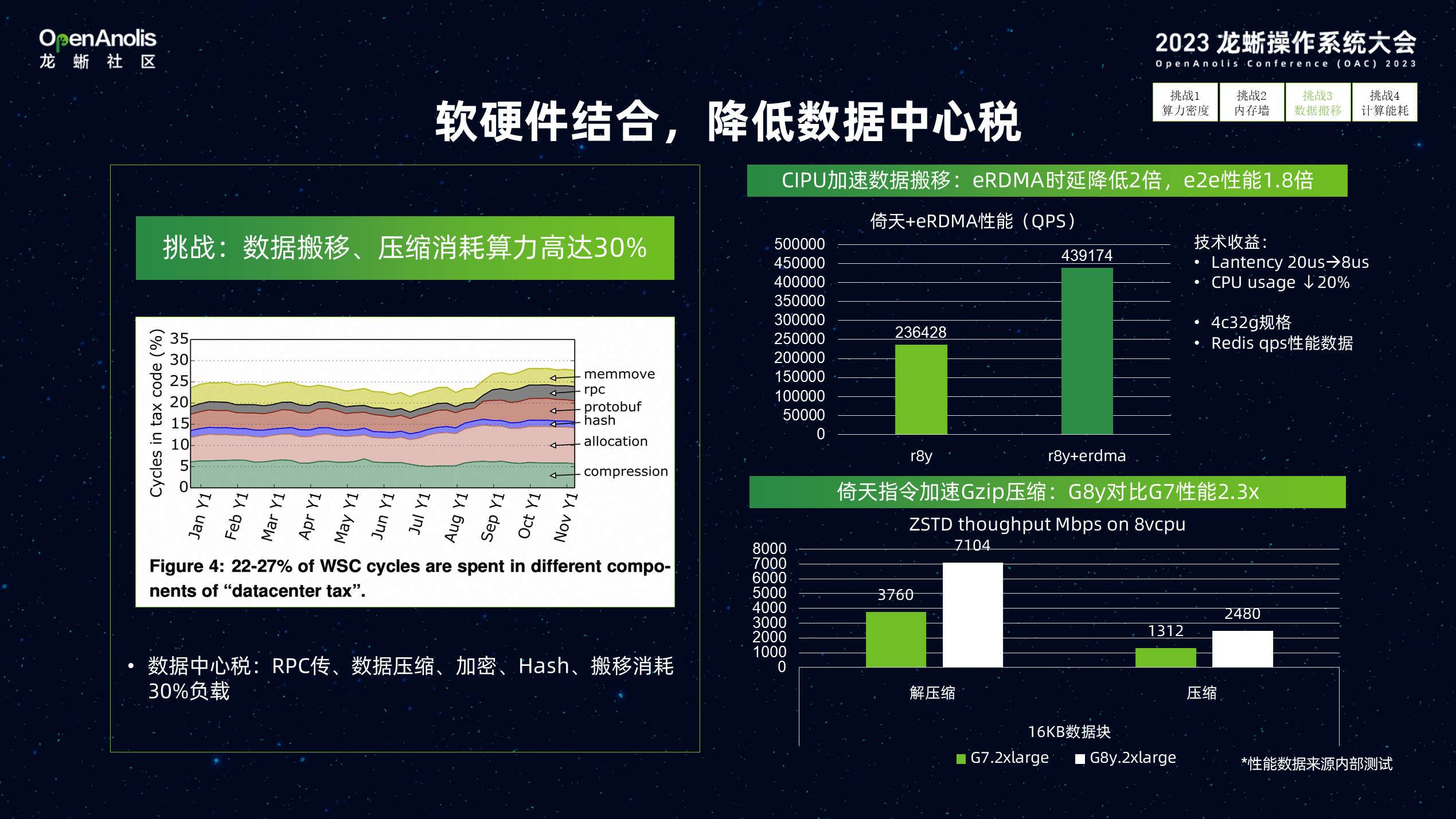
第三个是如何降低数据中心税。今天我们提到数据中心税的概念,是由于存储与计算分离带来的额外的开销,需要在存储与计算节点间进行来回的数据传输、加密、Hash的动作,这些额外的开销消耗的 30% 以上算力资源。通过在倚天+CIPU eRDMA 的结合,主机间数据传输时延从 20us 降低到 8us,减少 20% CPU 占用率。通过在倚天中内置指令加速 GZIP 压缩/解压能力,可以极大降低数据传输与存储的成本。

第四个在应对功耗的挑战方面。在 X86 CPU,为了降低功耗,通常采用动态频率。面向 ToC 交互式的应用如电商/游戏等突发性应用,由于机柜功耗限制,需要控制一个安全的功率水位,以保证业务的连续性。通常我们会将 CPU 安全功耗设置在 50%;由于倚天 Arm CPU 自身低功耗,只有普通 CPU 的 1/6,这样就不需要开启降频率的手段,数据中心的安全水位可被提升到 70%。可以在面向数据/视频这类高负载应用场景获得更好的业务稳定性。
04 倚天 ECS 实例:云原生算力再进化
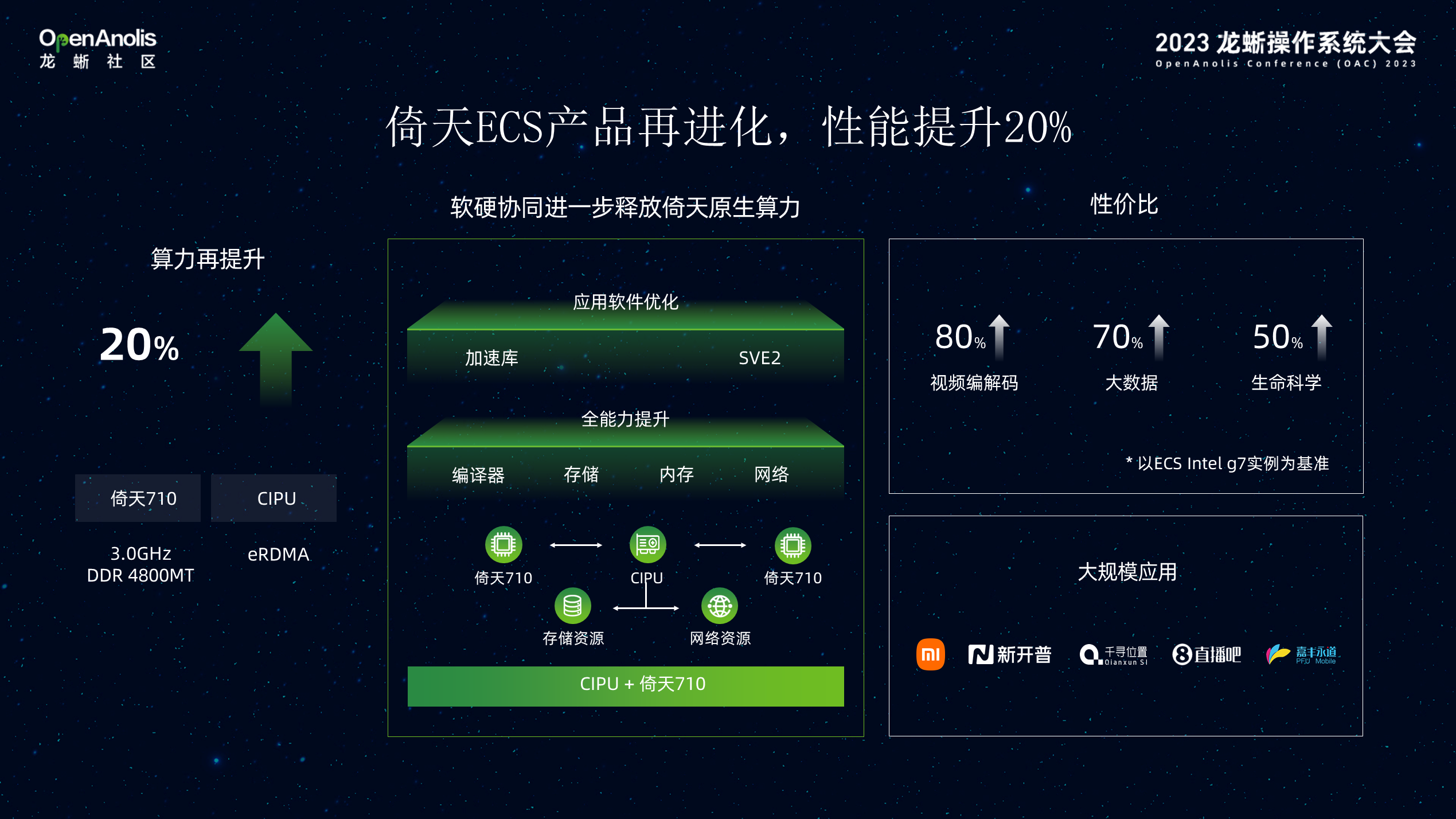
2023 年,我们持续优化倚天计算架构的产品,不断挖潜。在物理层倚天 CPU 频率由 2.75GHz 提升到 3.0GHz,内存频率由 4400 提升到 4800MHz,结合 CIPU 在存储、网络加速特性,倚天算力提升 20%。不仅如此,通过虚拟化软件、操作系统、编译器以及中间件等全栈软件优化,倚天实例在大数据、视频编解码、生命科学等场景性价比提升超过 30%。目前,已经服务小米、新开普、千寻位置等在内的一大批客户,持续助力客户业务降本增效。
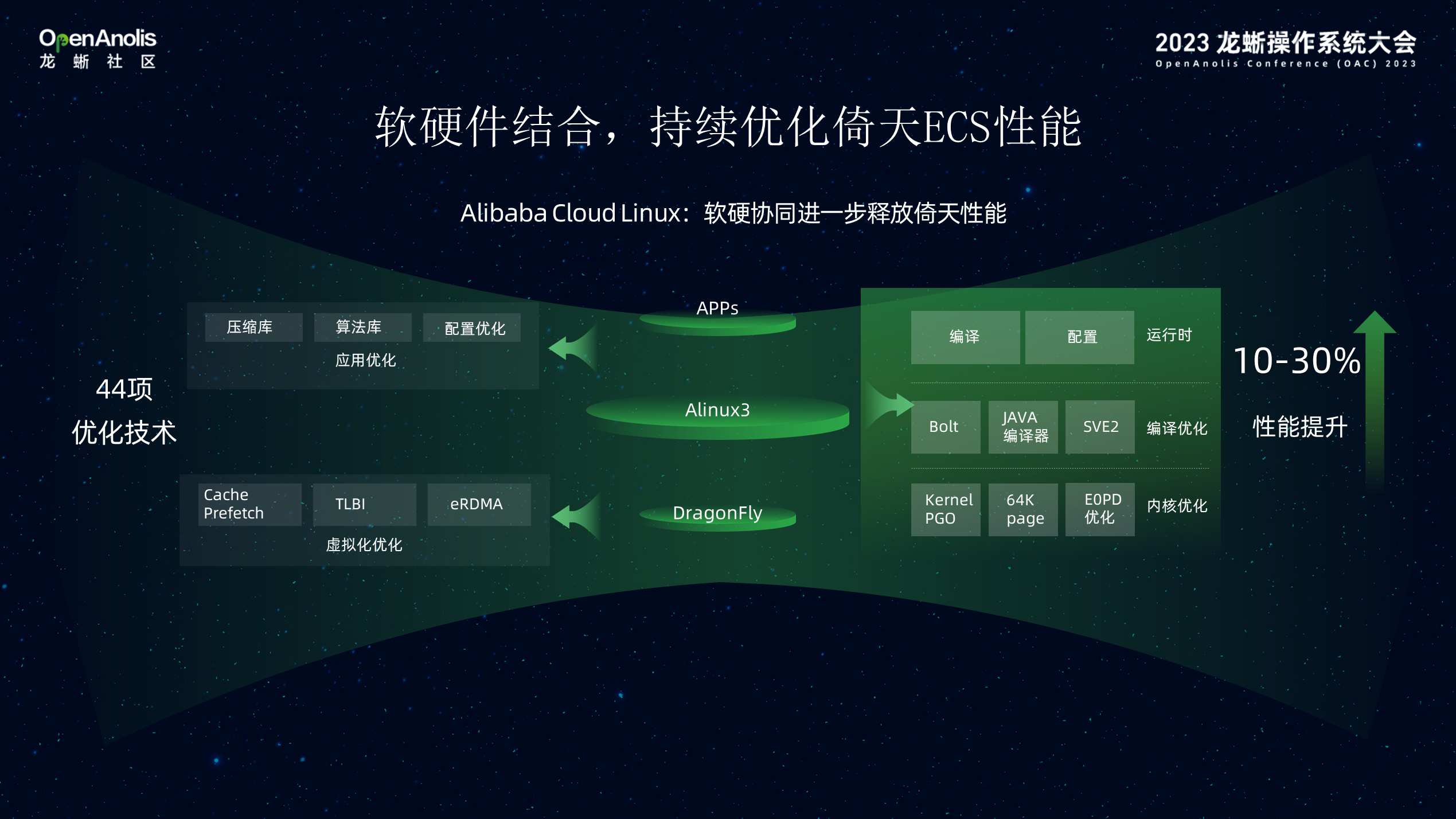
这些性能的提升得益于整个软件体系架构性能的优化,在底层 DragonFly 虚拟化层实现 Cache 预测,TLB 大页表、eRDMA、Alibaba Cloud Linux 是从倚天 ECS 产品开始建设初期就作为其默认搭载的操作系统,通过与倚天 ECS 的软硬协同优化,进一步释放倚天性能。操作系统在保证软件兼容性的同时,通过内核层调度、内存、网络优化匹配 CIPU+倚天 Arm 架构,运行时的编译/配置优化,对大数据、数据库场景进一步提升性能。
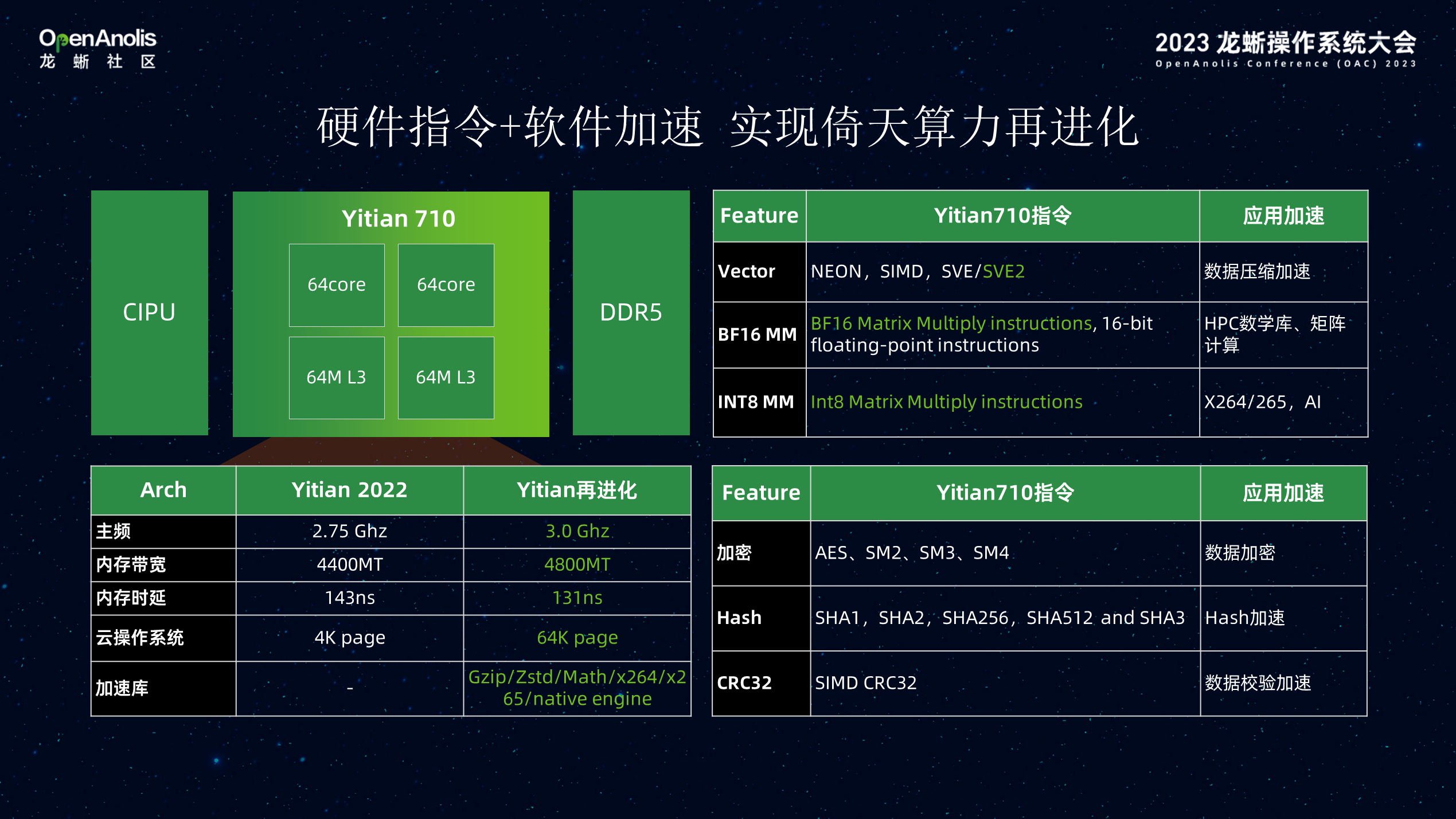
倚天这款产品是面向未来的智能化的产品。倚天 710 支持 SVE2 矢量指令集(可支持数据压缩场景),BF16 适合 HPC 业务,INT8 适用于视频编解码/AI 推理场景,结合 Arm 提供的 APL 数学加速库以及 CIPU 在网络存储的加速能力,倚天提供了良好的垂直场景加速底座。视频编解码、大数据、HPC等通用场景通过软硬协同配置优化,使能倚天实例并行指令、X-SIMD、APL加速库、编译优化等特性,极大提升端到端业务性能 。
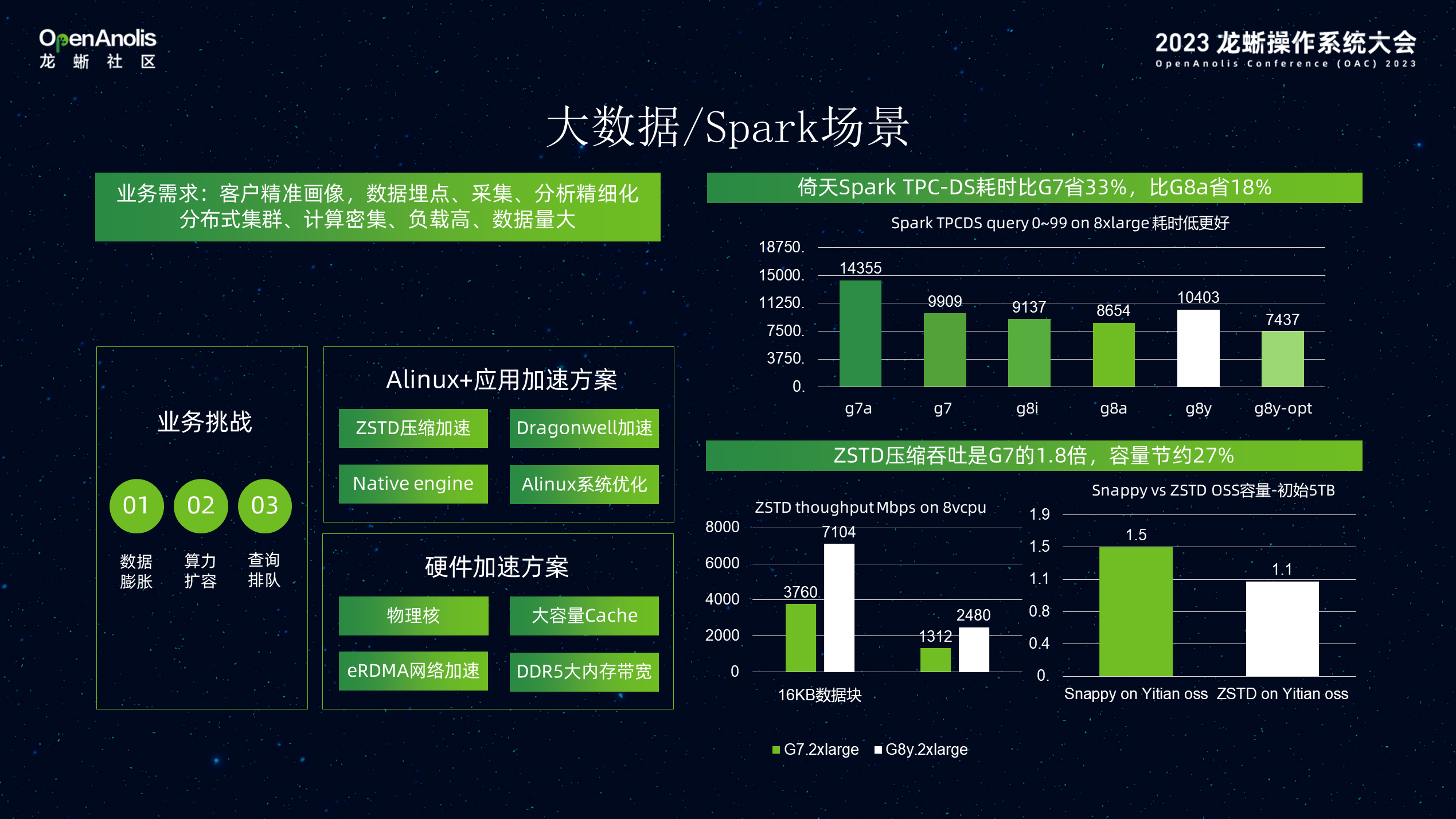
在 Spark 大数据业务场景中,对于客户精准画像,数据埋点,采集,分析等业务。数据快速膨胀,对大算力扩容需求极高。通过硬件层、阿里 Linux 系统优化,应用层的加速。Spark 在 TPCDS 测试级 的耗时更省,通过压缩可以节省 27% 的 OSS 存储空间 。
倚天 ECS 实例助力小米科技大数据业务上云,小米线下大数据业务面临以下挑战:
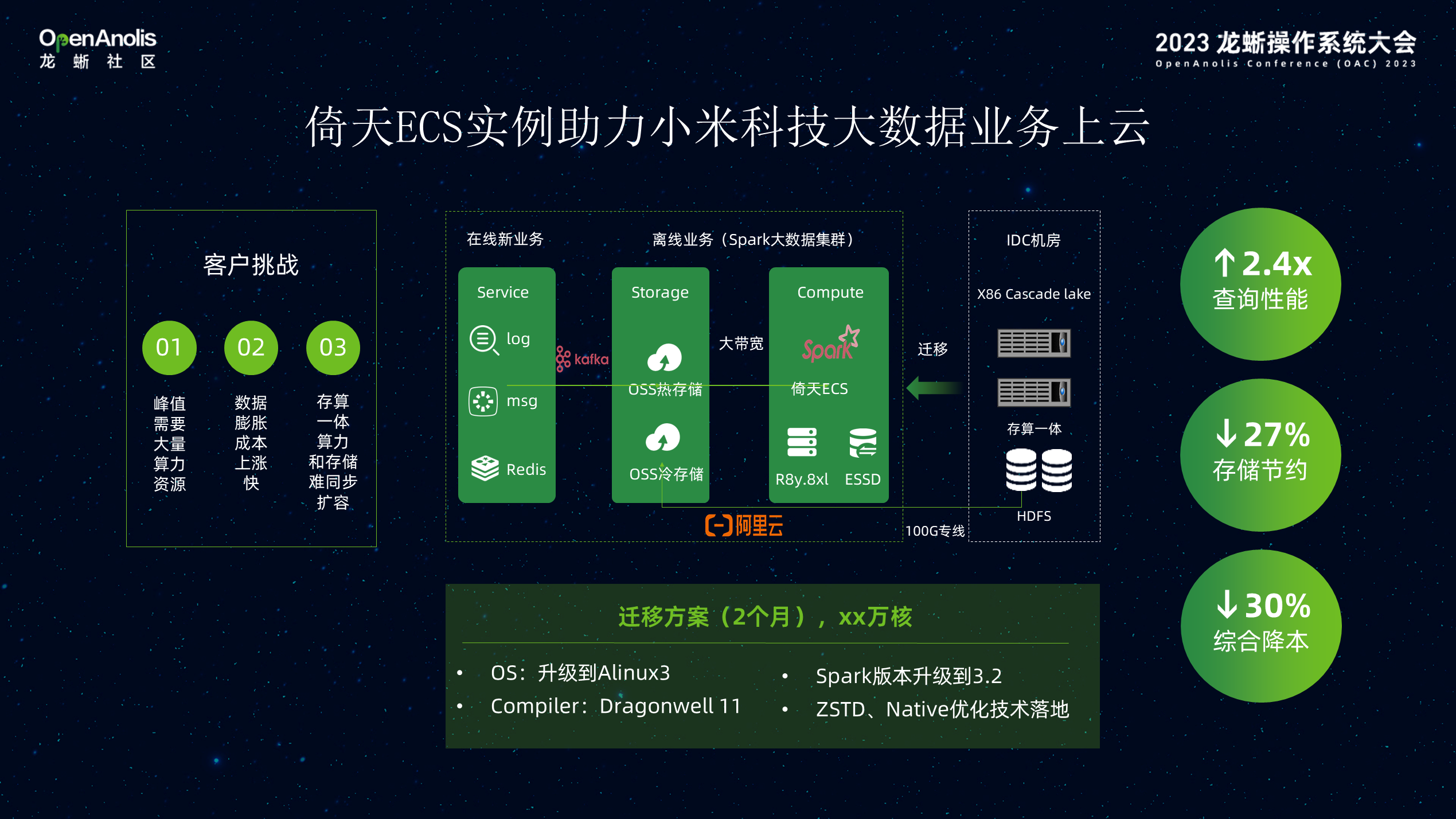
1)峰值算力要求高:在大数据技术的发展过程中,算力是其核心之一,对于数据的处理、分析和推断都需要极大的算力支持。离线计算任务重,并发处理高,如何保证弹性、高负载下稳定的算力输出对算力资源提出挑战。
2) 数据膨胀存储成本上涨:数据的海量爆发增长对数据存储成本挑战巨大,需要更加优异的技术方案以解决数据存储成本高的问题。
3) 线下存算一体架构,很难保证数据与算力的最佳匹配,同步扩容。小米将大数据业务迁移到阿里云倚天实例后,可实现离线与在线业务混布。依托优异的算力、针对倚天优化的数据压缩等特性,使得在 vCPU 资源缩小一半的情况下,性能提升了 27-34%,这个对客户来讲是很有价值的一件事情。
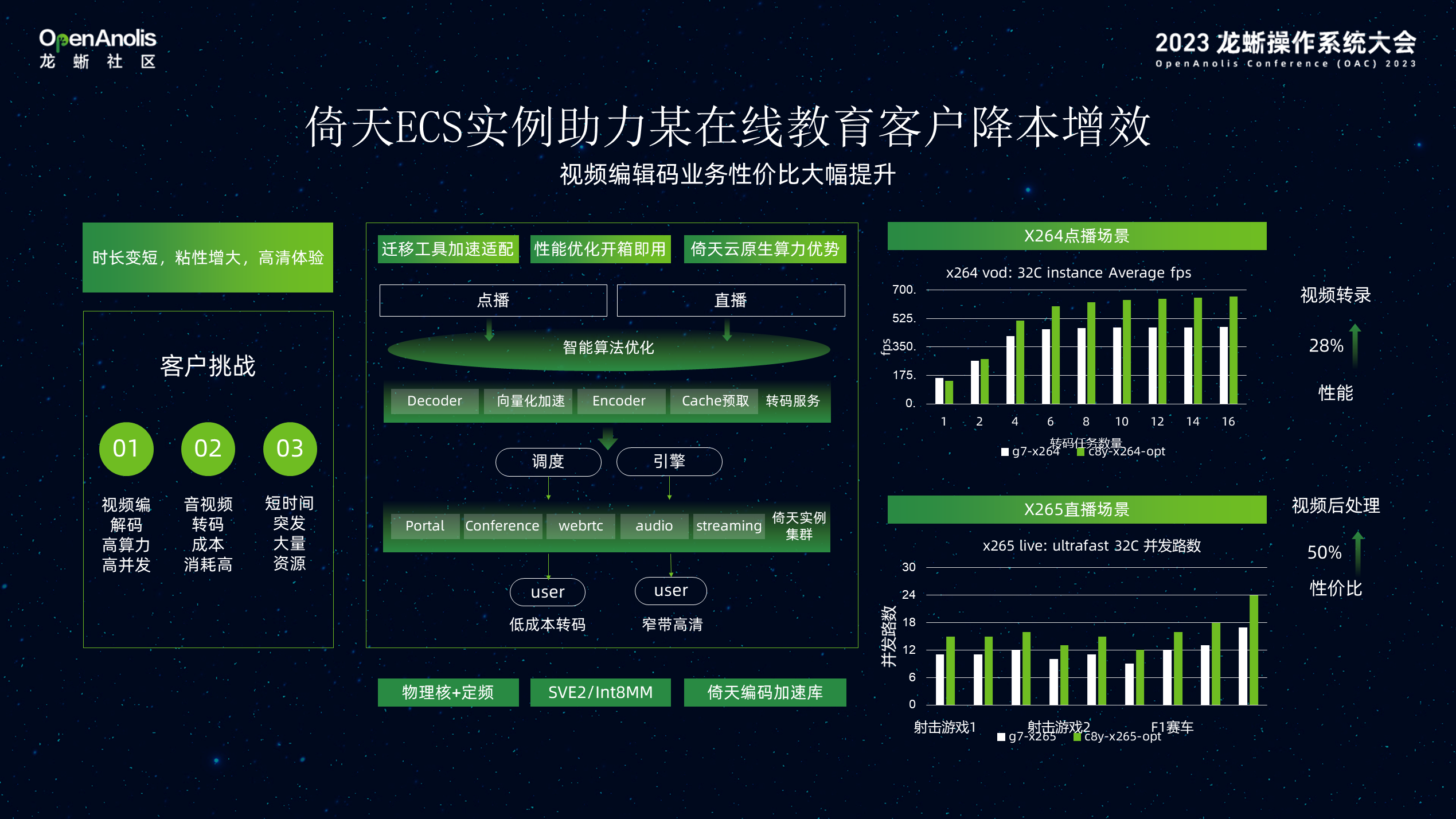
倚天 ECS 实例助力某在线教育客户降本增效。随着短视频、直播行业蓬勃发展,编解码作为典型视频处理任务之一对高算力、高并发、低成本提出了更高的要求。不仅如此,短视频是典型的波峰波谷场景,以某在线教育客户为例,它需要在课程直播时快速拉起大量资源,非直播时释放,因此对于资源按需弹性提出了高要求。在线教育客户将其视频转录、视频后处理业务模块迁移到倚天实例后,性能提升超过28%,性价比提升超过 50%,并很高的满足了客户按需弹性诉求。
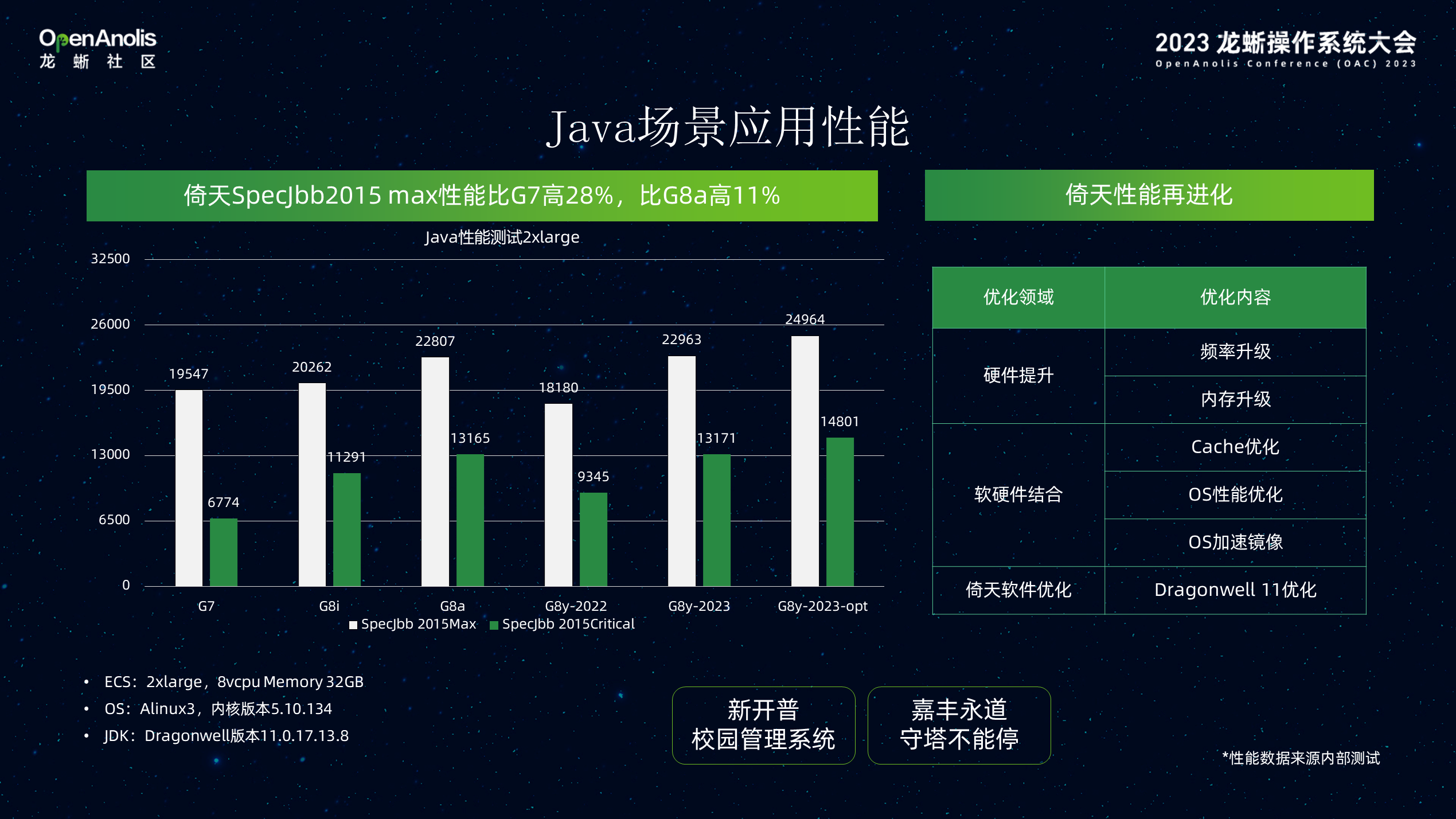
Java 部分的硬件部分,CPU 自带了很多 Java 优化能力,更重要的是 Dragonwell 系统,Java 库对 Java 的性能在这款产品上得到了比较好的应用。
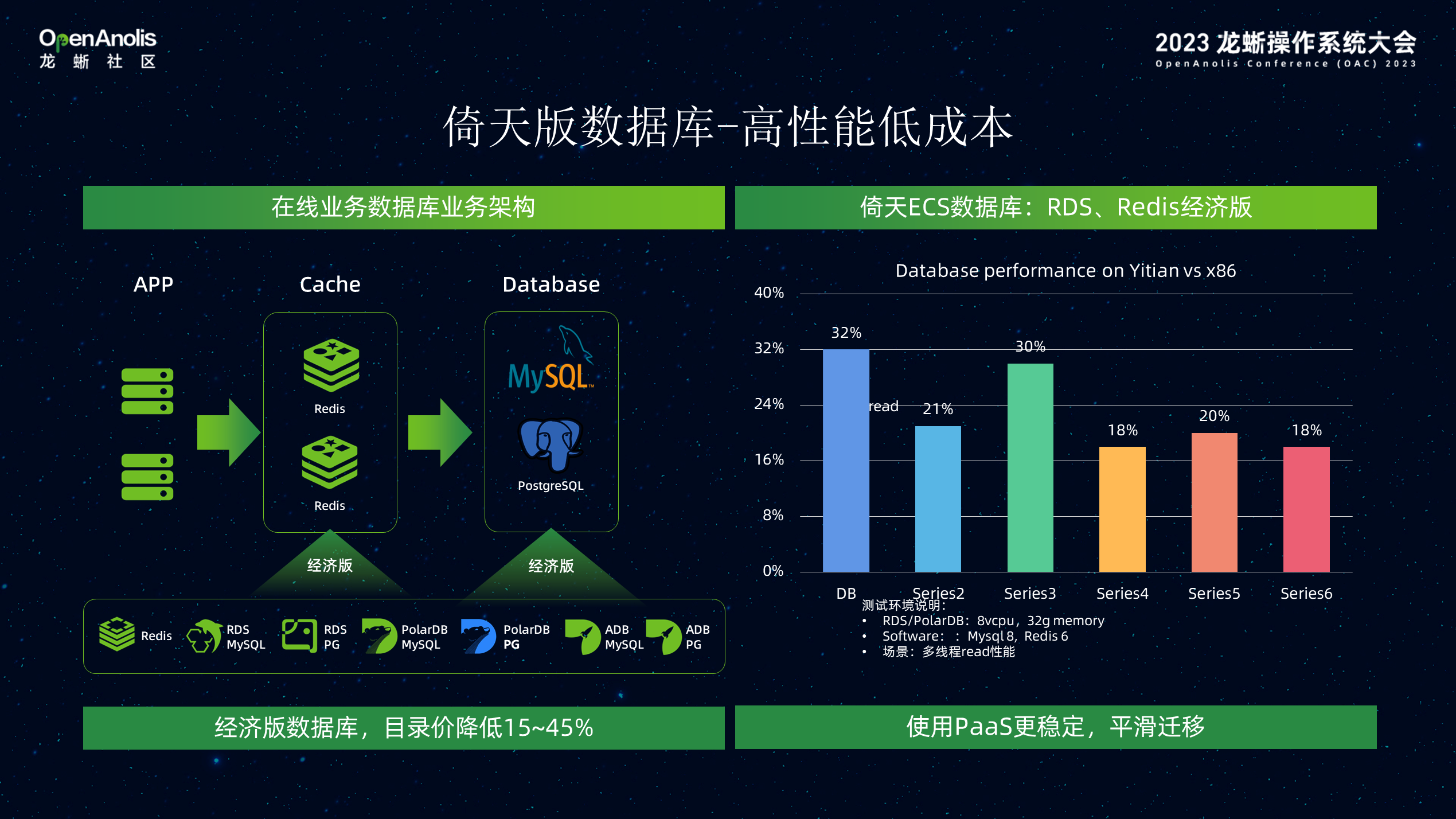
在数据库的场景,阿里云内部 RDS 产品采用倚天发布经济型数据库。采用倚天 CPU 的高处理能力和大 Cache,适合 Redis KV 类数据低时延诉求。

除了操作系统以外,围绕大数据、数据库、Java 等应用,驱动我们和龙蜥社区构建了一个丰富的开源软件生态系统,通过 2~3 年的软件生态建设,会越来越满足应用的要求。倚天从底层的操作系统、编程语言,各种开放算法库,常见的开源软件都进行了兼容性的测试。大部分的应用可无缝平滑迁移到倚天系统。

阿里云内部的产品也在逐步完善,我们团队更多的是负责 iaas 层,而 pass 层的产品,更多上层应用也在不断完善。
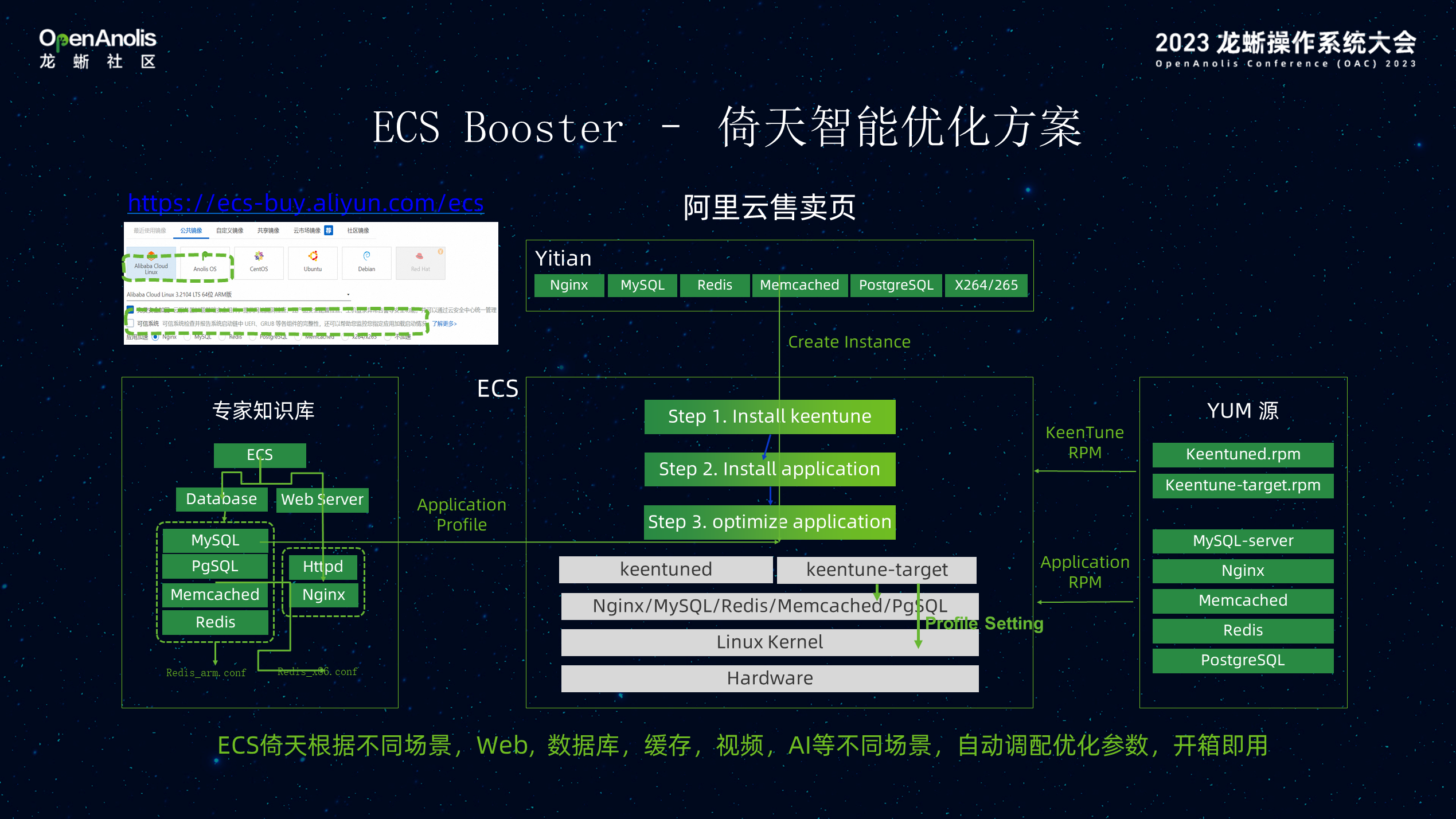
为了方便更多客户,解决迁移到 Arm 生态比较困难,上层应用优化方面要付出非常大的努力,这层内置了很多的优化过的软件,通过 BOOSTER 系统,让客户快速加载,原来的软件优化能力、系统的配置能力一键式获得。
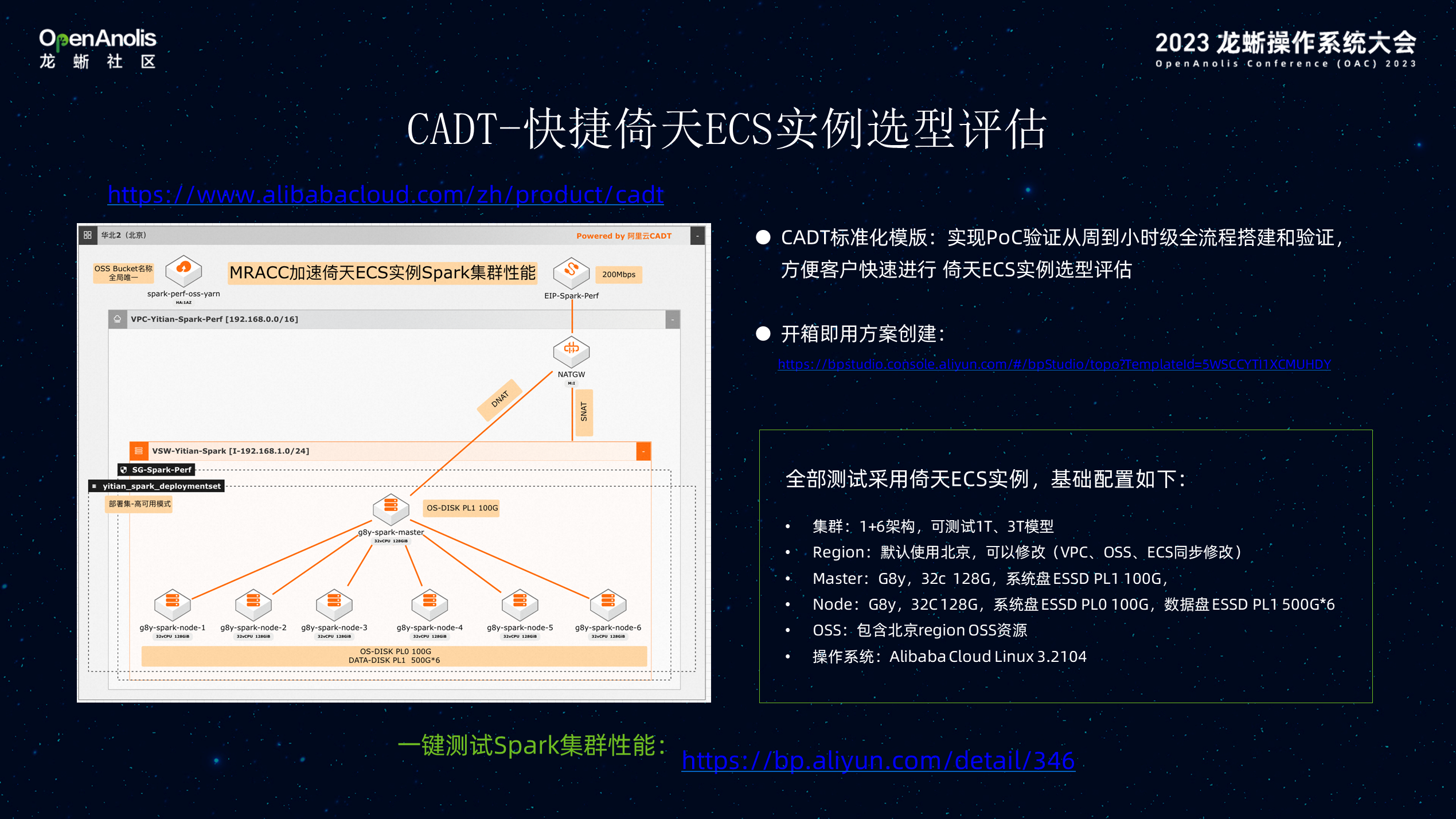
为了帮助大家很好地评估,是否适合使用这款产品。阿里云提供了可视化的 CADT 标准模版,可以小时级搭建完整的完整验证测试环境,实现一键式的 Spark 测试平台环境搭建,通过这个产品可以在小时内快速构建分布式环境帮助客户验证。

倚天 ECS 实例作为 Arm 实例,在软件生态上还是与 X86 有部分的差异,为了保障用户的平稳迁移,我们建设了 EasyYitian 迁移平台。通过迁移前的代码兼容性扫描、系统差异性评估,来进行迁移前分析,帮助用户提前发现差异和需要改造的点,通过 EasyBuild 来帮助用户快捷高效的编译构建,通过迁移后的性能评估、性能优化来帮助用户做到迁移后的性能最优,通过 EasyYitian 迁移平台,从全流程保障用户向倚天的平稳迁移。
构建面向 Arm 的开发者生态对于倚天的发展至关重要。倚天社区定位一站式开发者支撑平台,涵盖倚天热点技术、最佳实践以及其他活动。开发者如果有迁移、兼容性、性能等相关的任何问题均可以通过提问或者浏览论坛的方式找到答案。
最后是一个呼吁,通过龙蜥社区能贡献更多的产品和能力,为中国自研的 CPU、CIP,可能还有更多未来的各种产品,硬件的产品共同构建自己的产业链格局。
Alibaba Cloud Linux 官网:Alibaba Cloud Linux_aliyun linux_Linux操作系统_计算-阿里云
更多视频回放、课件获取:
2023 龙蜥操作系统大会直播回放及技术 PPT上线啦,欢迎点击下方链接观看~
回放链接:2023 OpenAnolis Conference - OpenAnolis龙蜥操作系统开源社区
技术 PPT :关注龙蜥公众号【OpenAnolis 龙蜥】,回复“龙蜥课件”获取。
这篇关于Alibaba Cloud Linux 与倚天软硬结合,加速数据智能创新的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






