本文主要是介绍DDL语言(数据定义语言),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 一、库的管理
- 1.库的创建
- 2.库的修改
- 3.库的删除
- 二、表的管理
- 1.表的创建
- 2.表的修改
- 3.表的删除
- 4.表的复制
- 测试
前言
数据定义语言主要包括库和表的管理。
一、库的管理
创建、修改、删除
二、表的管理
创建、修改、删除
关键词
创建:create
修改: alter
删除: drop
这里要与之前的对数据进行付定义操作,区分delete、truncate
一、库的管理
1.库的创建
语法:
create database 库名;
案例:创建Books
CREATE DATABASE books;
#CREATE DATABASE if not exists books;如果不存在,就创建
2.库的修改
RENAME DATABASE books TO 新库名;
可以更改库的字符集:
ALTER DATABASE books CHARACTER SET gbk;
3.库的删除
DROP DATABASE books;
#DROP DATABASE IF EXISTS books;如果存在就删除
二、表的管理
1.表的创建
语法:
create table 表名(列名 列的类型【(长度) 约束】,列名 列的类型【(长度) 约束】,列名 列的类型【(长度) 约束】,...列名 列的类型【(长度) 约束】
)
案例1:创建表Books
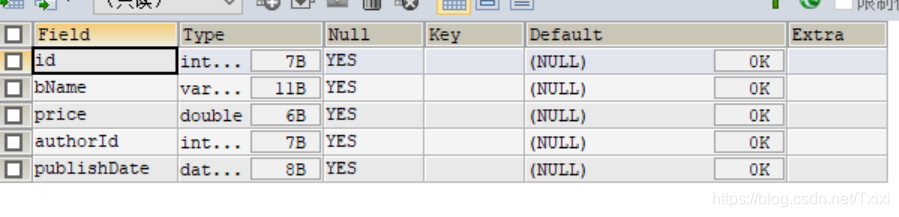
USE books ;CREATE TABLE book (id INT,#编号 bName VARCHAR (20),#图书名 price DOUBLE,#价格 authorId INT,#作者编号 publishDate DATETIME#出版日期
) ;DESC book ;
结果:
案例2:创建表author
CREATE TABLE author (id INT,au_name VARCHAR (20),nathion VARCHAR (10)
) ;DESC author;
结果:

2.表的修改
核心语法:
alter table 表名 add(添加)|drop(删除)|modify(修改)|change(改变) column 列名 【列类型 约束】;
①修改列名
ALTER TABLE book CHANGE COLUMN publishdate pubDate DATETIME ;
②修改列的类型或约束
ALTER TABLE book MODIFY COLUMN pubDate TIMESTAMP ;
③添加新列
ALTER TABLE author ADD COLUMN annual DOUBLE ;
④删除列
ALTER TABLE author DROP COLUMN annual;
⑤修改表名
ALTER TABLE author RENAME TO book_author ;3.表的删除
DROP TABLE book_author;
DROP TABLE IF EXISTS book_author;
SHOW TABLES;
通用的写法:
DROP DATABASE IF EXISTS 旧库名;
CREATE DATABASE 新库名;DROP TABLE IF EXISTS 旧表名;
CREATE TABLE 表名();
4.表的复制
(1)仅仅复制表的结构
CREATE TABLE copy LIKE author ;
(2)复制表的结构+数据(全部)
CREATE TABLE copy2
SELECT *
FROMauthor ;
(3)只复制部分数据
CREATE TABLE copy3
SELECT id,au_name
FROMauthor
WHERE nation='中国' ;
(4)仅仅复制某些字段(只要列结构,不要数据)
CREATE TABLE copy4
SELECT id,au_name
FROMauthor
WHERE 1 = 2 ;
测试
1.创建表deptl
| name | Null | type |
|---|---|---|
| id | int(7) | |
| name | varchar(25) |
USE test ;#创建表首先要找一个库
CREATE TABLE dept1 (id INT (7), NAME VARCHAR (25)) ;2.将表departments中的数据插入新表dept2中
CREATE TABLE dept2
SELECT *
FROMmyemployees.departments ;
3.创建表emp5
| name | Null | type |
|---|---|---|
| id | not null | int(7) |
| first_name | varchar(25) | |
| last_name | varchar(25) | |
| dept_id | not null | int(7) |
CREATE TABLE emp5(id INT(7) NOT NULL,first_name VARCHAR(25),last_name VARCHAR(25),dept_id INT(7) NOT NULL
);
4.将列Last_name的长度增加到50
ALTER TABLE emp5 MODIFY COLUMN last_name VARCHAR (50) ;
5.根据表employees创建employees2
CREATE TABLE employees2 LIKE myemployees.employees ;
6.删除表emp5
DROP TABLE IF EXISTS emp5;
7.将表employees2重命名为emp5
ALTER TABLE employees2 RENAME TO emp5 ;
8.在表emp5中添加新列test_column,并检查所作的操作
ALTER TABLE emp5 ADD COLUMN test_column VARCHAR (10) ;DESC emp5 ;
9.直接删除表emp5中的列dept_id
ALTER TABLE emp5 DROP COLUMN dept_id ;这篇关于DDL语言(数据定义语言)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



