本文主要是介绍Flask框架进阶-Flask流式输出和受访配置--纯净详解版,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Flask流式输出🚀
在工作的项目当中遇到了一种情况,当前端页面需要对某个展示信息进行批量更新,如果直接将全部的数据算完之后,再返回更新,则会导致,前端点击刷新之后等待时间过长,开始考虑到用进度条或者流式输出的方式,但是由于进度条的计算前端页面的设计都需要改动会增加额外的工作量,因此考虑使用流式输出的方式,前端接收一个或一部分更新一个或一部分,因此就需要用到Flask框架中的流式输出的功能,其次,例如如果想要自己实现大语言模型的流式输出的效果,那这也是一项绕不开的学习点。
Flask框架初探-如何在本机发布一个web服务并通过requests访问自己发布的服务-简易入门版
文章目录
- Flask流式输出🚀
- 1.Flask流式输出基础代码+浏览器访问
- 2.使用requests库接收流式输出的返回
- 3.设置跨域
- 4.设置响应头和响应类型
- 5.设置SSE格式输出
- 结束
1.Flask流式输出基础代码+浏览器访问
Flask作为服务端的基础代码如下,先从简单的开始,下面会对代码中的部分再进行解释:
import timefrom flask import Flask, Response
app = Flask(__name__)@app.route('/stream')
def stream_numbers():def generate_numbers():for number in range(1, 10):yield f"{number}\n" # 每次生成一个数字就发送 \n 最好不要删除time.sleep(0.5) # 为了演示,加入短暂延迟return Response(generate_numbers())if __name__ == "__main__":app.run(host="0.0.0.0", port=5000)
先给出直接使用浏览器的访问结果。这里我也观察到了好像是从2开始流输出,似乎是前一秒的数据会先缓存然后直接打印出来,然后后面的再正常流式输出,如果是用代码的话几乎不会有这个问题。

2.使用requests库接收流式输出的返回
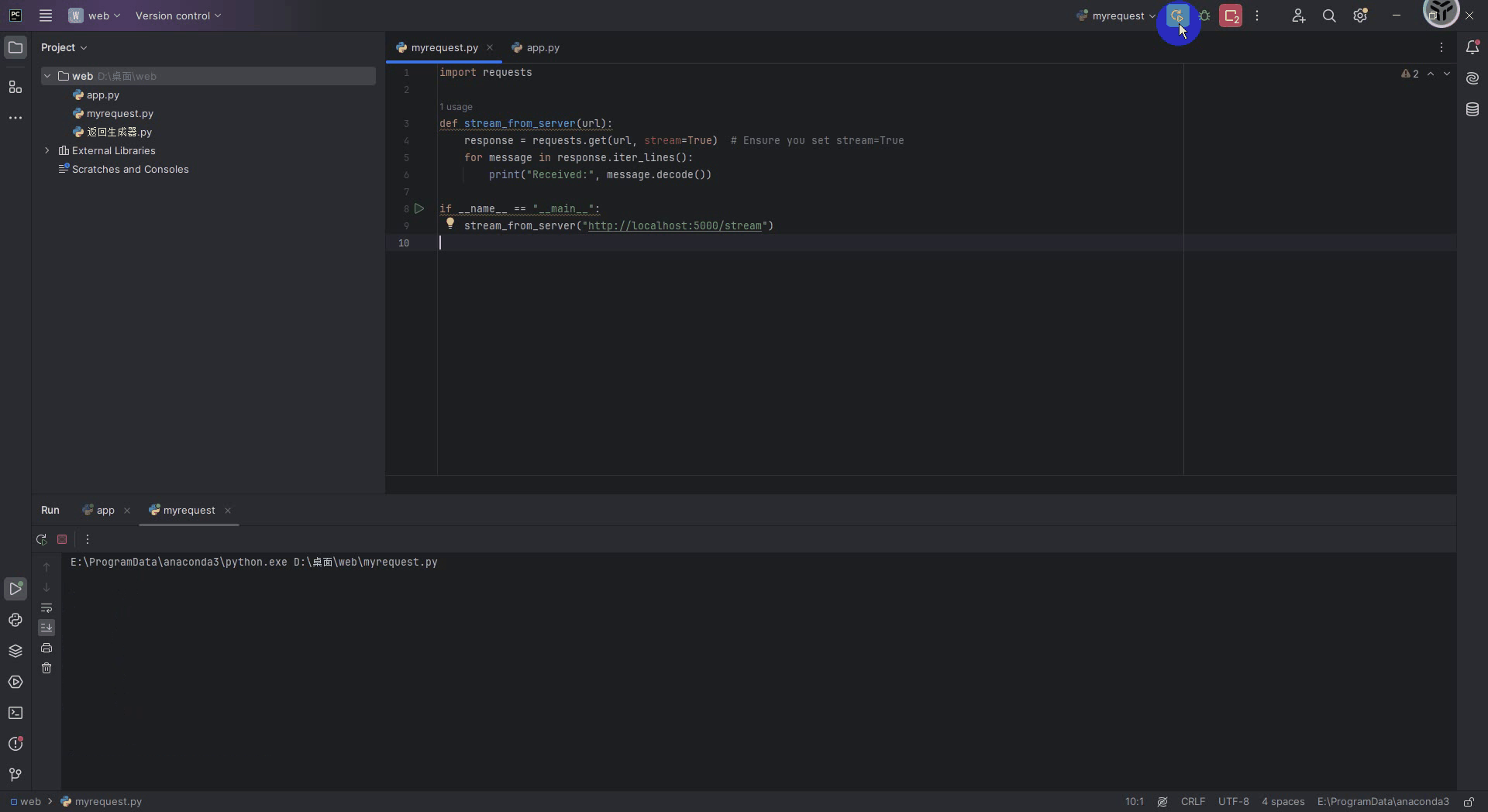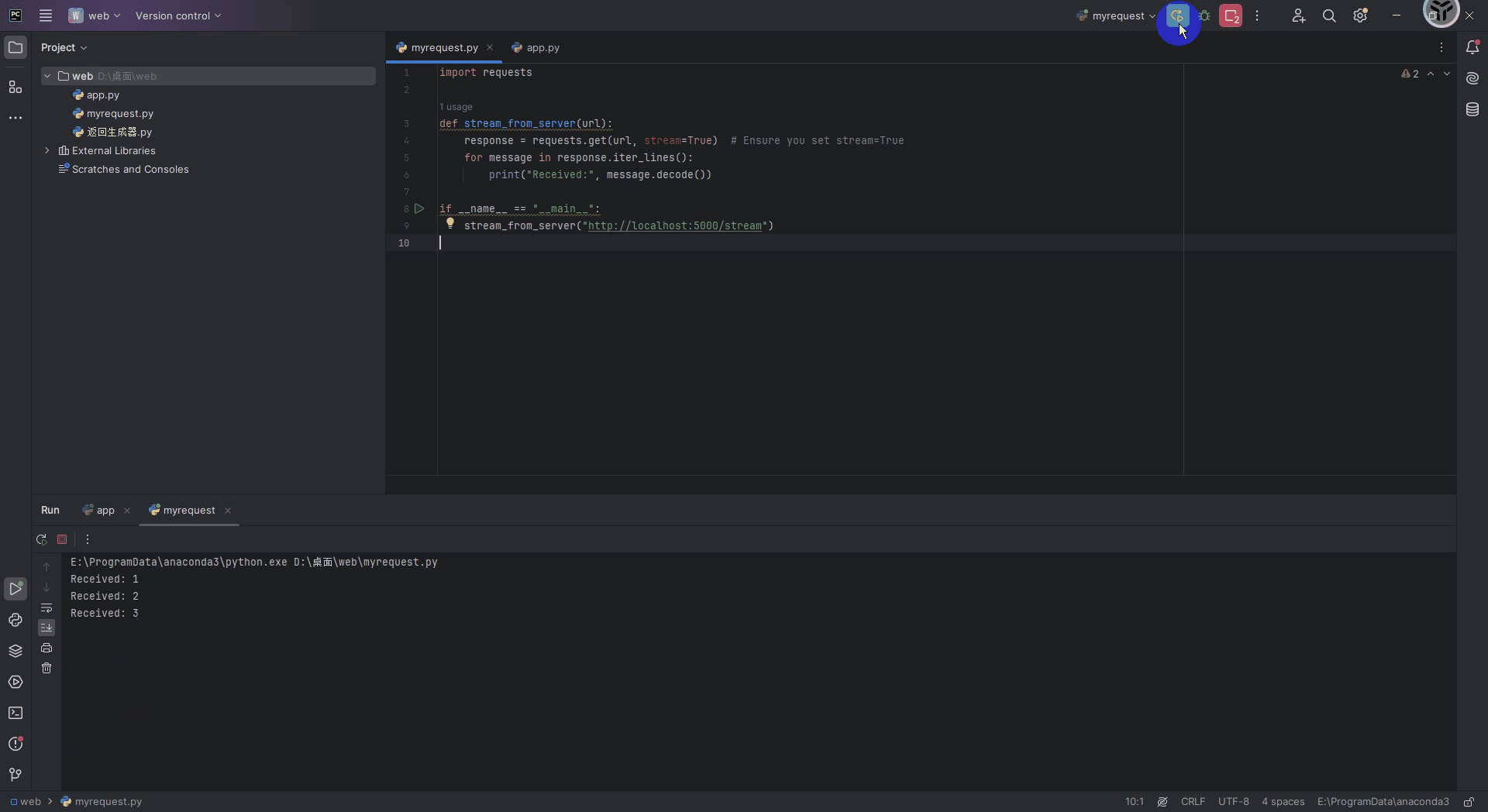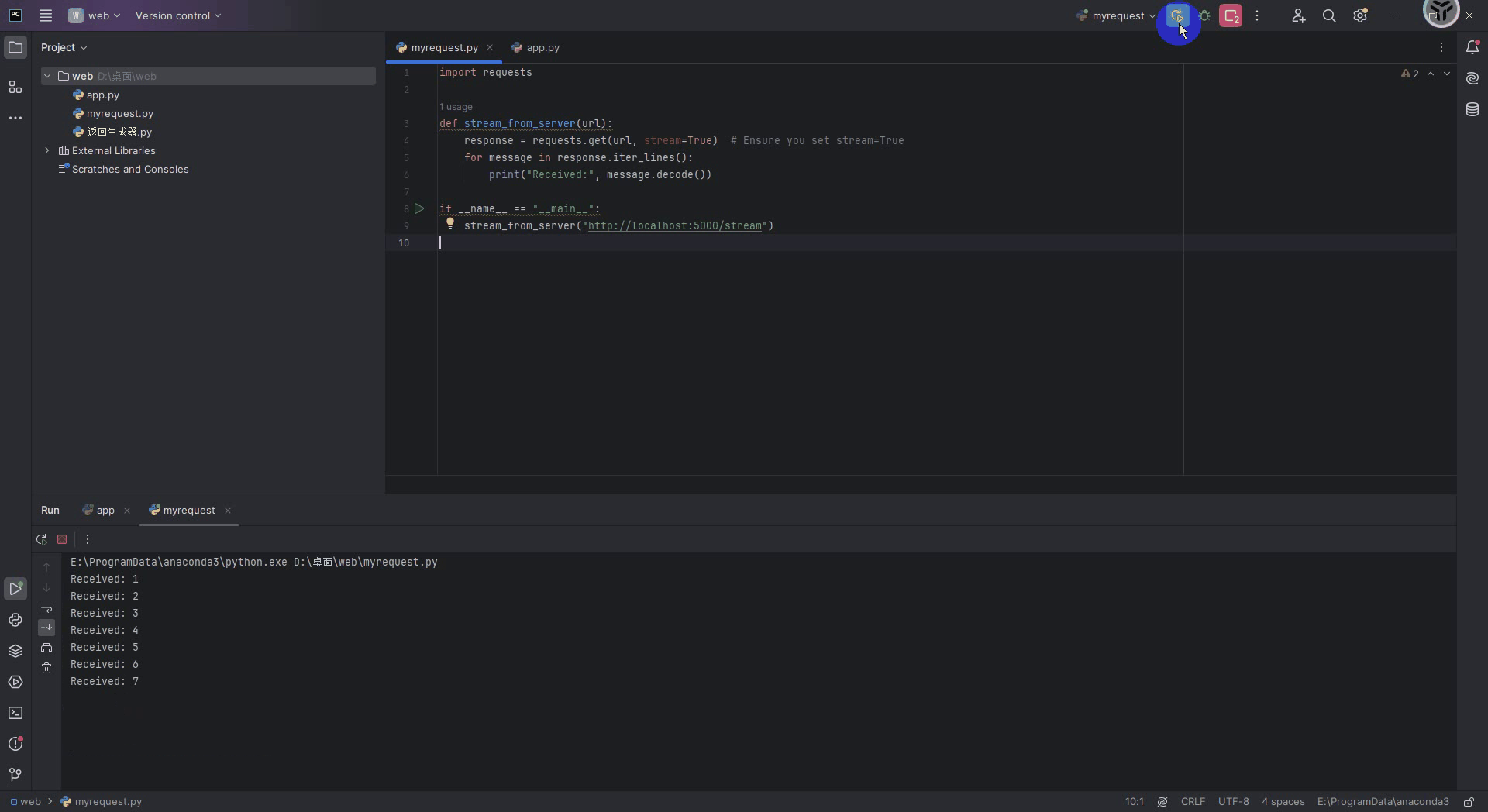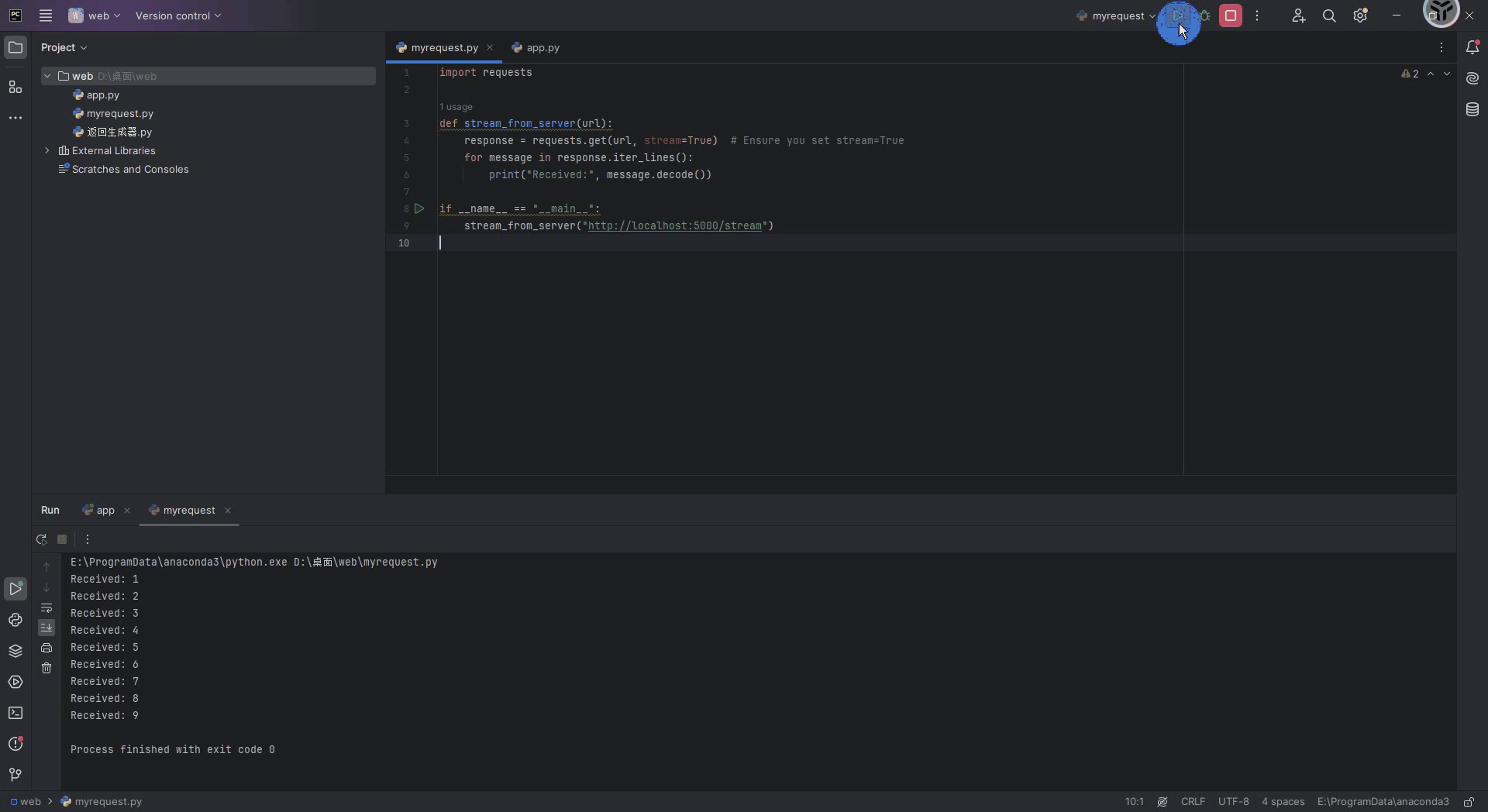
在python中可以使用通过requests库来接收流式输出的web服务格式,下面给出代码,运行下面代码之前别忘了把启动Flask服务的代码先运行起来。
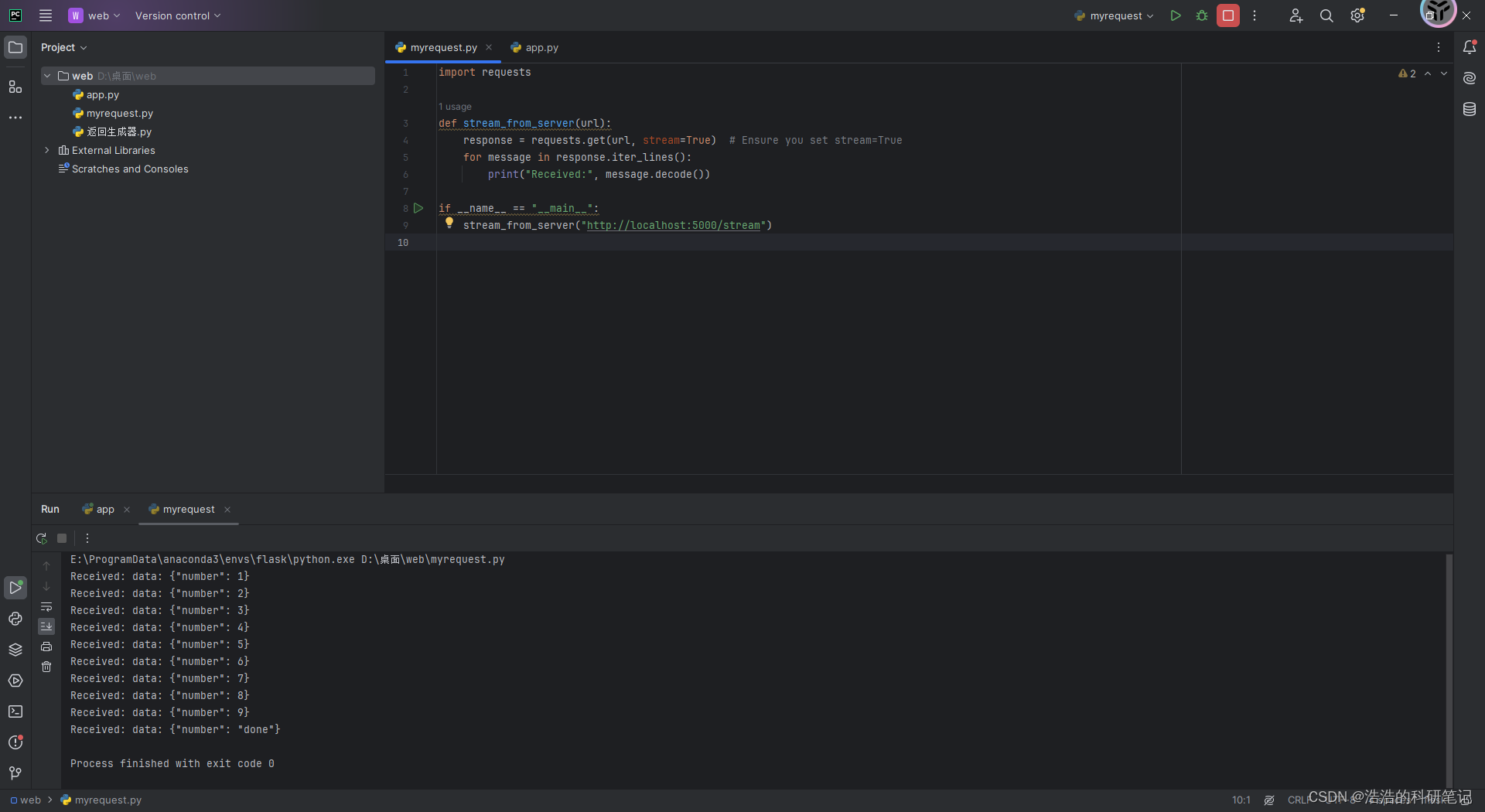
import requestsdef stream_from_server(url):response = requests.get(url, stream=True) # Ensure you set stream=Truefor message in response.iter_lines():print("Received:", message.decode())if __name__ == "__main__":stream_from_server("http://localhost:5000/stream")
3.设置跨域
跨域资源共享(CORS,Cross-Origin Resource Sharing)是一种安全功能,它允许一个网页的资源能够被其他域名(origin)的网页访问。默认情况下,浏览器的同源策略会阻止从一个域中加载的网页去请求另一个域的资源。这是为了防止恶意网站访问或操作用户数据。
由于目前公司里前端的同事使用的都是js,在使用js访问我们python的服务的时候,有很多奇怪的现象,如果我如果不开跨域,js的同事也能访问到我的数据,但实现不了流式输出的格式,等等,因此在开发python服务的时候,开着跨域能节省很多麻烦。在python中实现跨域需要安装一个新的库。flask_cors。
pip install flask_cors
在安装成果之后从flask_cors导入CORS然后给app套一层CORS(app, resources="/*")就可以实现跨域resources这个是设置允许跨域访问我们的地址,设置成"/*"表示允许所有地址k跨域访问我们。
from flask import Flask, Response
from flask_cors import CORS
app = Flask(__name__)
CORS(app, resources="/*")
完整代码如下:
import time
from flask import Flask, Response
from flask_cors import CORS
app = Flask(__name__)
CORS(app, resources="/*")@app.route('/stream')
def stream_numbers():def generate_numbers():for number in range(1, 10):yield f"{number}\n" # 每次生成一个数字就发送time.sleep(0.5) # 为了演示,加入短暂延迟return Response(generate_numbers())if __name__ == "__main__":app.run(host="0.0.0.0", port=5000)
4.设置响应头和响应类型
js前端对于接收我们的要求非常苛刻,跨域开了之后,要服务器发送事件(Server-Sent Events, SSE)输出,还要响应头的内容类型对上,然后还得再响应头里把,时间类型,是否缓存,是否有响应缓冲都设置上,才能确保正常显示流式输出操作,增加了响应头和配置响应头相关内容的代码如下。
import time
from flask import Flask, Response
from flask_cors import CORS
app = Flask(__name__)
CORS(app, resources="/*")@app.route('/stream')
def stream_numbers():def generate_numbers():for number in range(1, 10):yield f"{number}\n" # 每次生成一个数字就发送time.sleep(0.5) # 为了演示,加入短暂延迟headers = {'Content-Type': 'text/event-stream','Cache-Control': 'no-cache','X-Accel-Buffering': 'no',}return Response(generate_numbers(),headers=headers)if __name__ == "__main__":app.run(host="0.0.0.0", port=5000)
响应头中的配置的内容解释如下。
Content-Type: text/event-stream(必须要):- 这个响应头对于服务器发送事件(SSE)至关重要,这是一种从服务器向客户端推送事件的标准方式。它告诉客户端响应是一个事件流,客户端应该保持连接打开,并准备接收多个事件。
Cache-Control: no-cache(必须要):- 这个头部指示浏览器或其他中间代理不要缓存当前的响应。在实时数据传输和事件流中,保证客户端接收的是最新的数据非常重要,而不是从缓存中提取的可能已经过时的数据。
X-Accel-Buffering: no(这个看情况使用):- 这是一个非标准的响应头,主要用于控制Nginx反向代理服务器的缓冲行为。设置为
no意味着禁止Nginx缓冲这个响应,这对于实时数据流非常重要,因为缓冲可能会导致数据延迟到达客户端。这个设置确保数据能够尽可能快地直接传输给客户端。
- 这是一个非标准的响应头,主要用于控制Nginx反向代理服务器的缓冲行为。设置为
5.设置SSE格式输出
然后SSE格式的输出说明参考GPT-4。
服务器发送事件(Server-Sent Events, SSE)是一种允许服务器主动向浏览器或客户端发送信息的技术。SSE 通常用于创建到服务器的单向持久连接,服务器可以通过这个连接发送任意数量的消息。这种方法主要用于实时应用,如实时通知、股票行情更新等。
SSE 数据的格式比较简单,以下是一个基本的示例:
data: This is a message
每条消息都以一个或多个以 “data:” 开头的行组成,后面跟随实际的消息内容,最后以一个空行结束,表示消息的结束。客户端会在收到空行后处理消息。
除了基本的消息外,SSE 还支持为消息指定事件类型和ID,这样客户端可以更精确地控制不同类型的消息处理。以下是一个包含事件类型和ID的完整示例:
plaintextCopy codeid: 1
event: user-update
data: { "username": "alice", "time": "2024-04-28T12:34:56Z" }
- id: 这个字段是可选的,用于设置消息的唯一标识。在客户端断开连接后重新连接时,可以通过发送最后接收到的ID来请求服务器发送丢失的消息。
- event: 也是可选的,指定事件的类型。客户端可以基于事件类型来决定如何处理接收到的数据。
- data: 包含实际的消息内容。如果消息数据跨多行,每一行都需要以 “data:” 开始。
在上述代码的基础上我们要进行如下的改动,才能保证js使用EventSource接口接收正常。
- 将输出整体改成SSE格式
- 将SSE各种中的data变为json格式
- 再返回完主要内容之后最后还要额外返回一次done给出截至条件。
json.dumps()将字典转换为json格式
import json
import timefrom flask import Flask, Response, json
from flask_cors import CORSapp = Flask(__name__)
CORS(app, resources="/*")@app.route('/stream')
def stream_numbers():def generate_numbers():for number in range(1, 10):json_data = json.dumps({"number": number})yield f"data: {json_data}\n" # 每次生成一个数字就发送time.sleep(0.5) # 为了演示,加入短暂延迟json_data = json.dumps({"number": "done"})yield f"data: {json_data}\n" # 发送完成信号headers = {'Content-Type': 'text/event-stream','Cache-Control': 'no-cache','X-Accel-Buffering': 'no',}return Response(generate_numbers(), headers=headers)if __name__ == "__main__":app.run(host="0.0.0.0", port=5000)
接收结果:
结束
以上技术就是实现一个自己的网页然后模拟ChatGPT流式输出的一块重要拼图,目前找了我的一个学弟用vue负责做前端,去做一下这个小项目,已经基本完成,之后会开源前后端代码和gitee的地址。
这篇关于Flask框架进阶-Flask流式输出和受访配置--纯净详解版的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







