本文主要是介绍架构师技能:技术深度硬实力透过问题看本质--深入分析nginx偶尔502错误根因,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
以架构师的能力标准去分析每个问题,过后由表及里分析问题的本质,复盘总结经验,并把总结内容记录下来。当你解决各种各样的问题,也就积累了丰富的解决问题的经验,解决问题的能力也将自然得到极大的提升。励志做架构师的撸码人,认知很重要。
本文主要想表达的是解决问题的态度:透过问题看本质,由虚到实,往深层次地挖掘。
一、问题和目的
1、问题现象:
接入层nginx集群某个接口偶尔出现502,但是业务nginx没有看到502日志,业务服务端口正常。

2、 本次总结的目的:积累沉淀
1)、知识学习路径:

1、最好的学习,实现90%的知识转化,分享是最好的方式。
2、知识输出:把知识内化为自己的智慧。
3、把智慧升华为世界观和方法论。
2)、不要轻视任何小问题,追根溯源问题的本质,才积累丰富的解决问题的经验。
首先需要了解nginx运行原理。Nginx工作原理和优化总结。_nginx原理-CSDN博客
nginx的健康检查机制:Nginx健康检查机制-CSDN博客
海恩法则
· 事故的发生是量的积累的结果。
· 再好的技术、再完美的规章 , 在实际操作层面也无法取代人自身的素质和责任心 。
薛定谔的猫
“薛定谔的猫”告诉我们,事物发展不是确定的,而是量子态的叠加。
墨菲定律
· 任何事情都没有表面看起来那么简单 。
· 所有事情的发展都会比你预计的时间长 。
· 会出错的事总会出错。
· 如果你担心某种情况发生,那么它更有可能发生 。
蝴蝶效应
世界会因一些微小因素的变动,而发生很大的变化。
熵增原理
“热力学第二定律”(熵增原理)告诉我们,世界总是在变得更加混乱无序。
警示我们对生产环境发生的任何怪异现象和问题都不要轻易忽视,对于其背后的原因一定要彻查。同样,海恩法则也强调任何严重事故的背后 都是多次小问题的积累,积累到一定的量级后会导致质变,严重的问题就会浮出水面 。 那么,我们需要对线上服务产生的任何征兆,哪怕是一个小问题,也要刨根问底: 这就需要我们有技术攻关的能力,对任何现象都要秉着以下原则: 为什么发生? 发生了怎么应对? 怎么恢复? 怎么避免? 对问题要彻查,不能因为问题的现象不明显而忽略 。
3)、总结错误处理经验,快速定位和解决问题。
不回避问题,不怕攻关,不惧挑战。在其位要积极主动去分析排查问题,而不是被动去接受问题。
解决问题的思路是一种思维工具,通过提出问题、分析问题和解决问题的过程,可以帮助我们主动思考和积极学习。在解决问题过程中帮助我们更深入地理解和应用知识技能。
二、问题定位
出现这种问题,肯定是需要彻查日志定位和分析。
1、查接入层nginx日志:
nginx出现错误日志:(110: Connection timed out) while reading response header from upstream 一般是nginx读取来自upstream的响应头时超时。

主要接口xxxx/container请求超时。
2、排查是否存在:no live upsteams

接口/user/autch/check出现no live upsteams,即报出502错误。
3、业务nginx查询接口xxxx/container日志情况:
接口xxxx/container请求频繁(相对历史),http code=499,即service服务处理超时,接入层直接断开请求了。

初步定位:
由于接口接口xxxx/container大量请求超时,可能导致接入层nginx会剔除业务nginx服务,然后接口/user/autch/check出现no live upsteams,即报出502错误。
验证定位:
接口xxxx/container限流降级,在业务nginx特殊处理直接返回200:
localtion /xxxx/container {
return 200 "ok";
}
nginx -s reload后,接入层nginx的502日志消失。确定接口xxxx/container大量请求超时引起。
三、问题分析
1、为啥业务nginx明明存活负载很低,但是接入层偶尔出现502。
这个就需要了解nginx的健康检查机制:
我们接入层nginx upstream配置:
upstream upstream_6f6a3h8a0e5e1
{
server 192.168.1.21;
server 192.168.1.22;
}
nginx本身是没有针对负载均衡后端节点的健康检查的,但是可以通过默认自带的 ngx_http_proxy_module 模块 和ngx_http_upstream_module模块中的相关指令来完成当后端节点出现故障时,自动切换到健康节点来提供访问。
ngx_http_upstream_module模块中的server指令范例:
upstream name {
server 10.1.1.110:8080 max_fails=1 fail_timeout=10s;
server 10.1.1.122:8080 max_fails=1 fail_timeout=10s;
}
当upstream没有配置max_fails和fail_timeout,即nginx使用默认值fail_timeout为10s,max_fails为1次。
由于Nginx ngx_http_upstream_module模块是基于连接探测的,如果发现后端异常,在单位周期为fail_timeout设置的时间中失败次数达到max_fails次,这个周期次数内,如果后端同一个节点不可用,那么就将把节点标记为不可用,并等待下一个周期(同样时长为fail_timeout)再一次去请求,判断是否连接是否成功。
即在10s以内后端失败了1次【即一次请求超时】,那么这个后端就被标识为不可用了,所以在接下来的10s期间,nginx都会把请求分配给正常的后端【即多次的请求正常】。
关于502伴随出现错误no live upstreams while connecting to upstream的原因:在文章Nginx中常见问题与错误处理-CSDN博客
2、为啥业务nginx 出现499,接入层nginx显示响应超时。
这是因为接入层nginx配置响应超时为30s:
proxy_read_timeout 30s;
proxy_connect_timeout 5s;
而业务nginx超时是60s,即接入层nginx超时30s会主动断开和业务nginx连接。
此时业务nginx请求日志就会出现499.
3、接口xxxx/container大量请求超时
依赖底层一个服务出现变动,导致接口处理超时。
四、解决问题
本质还是需要优化超时接口,但是为了预防某个接口出现问题进而导致整个服务不能用的情况,需要做一些预防措施。
方案1:优化 upstream 默认健康检测,主要降低出现502到概率。
upstream upstream_6f6a3h8a0e5e1 {
server 192.168.1.21 max_fails=3 fail_timeout=60s;
server 192.168.1.22 max_fails=3 fail_timeout=60s;
}
即在30s以内后端失败了3次那么这个后端才被标识为不可用了。
同时可以增加业务nginx数量,这样业务nginx完全被剔除概率就更低
upstream upstream_6f6a3h8a0e5e1 {
server 192.168.1.21 max_fails=3 fail_timeout=60s;
server 192.168.1.22 max_fails=3 fail_timeout=60s;
server 192.168.1.23 max_fails=3 fail_timeout=60s;
server 192.168.1.24 max_fails=3 fail_timeout=60s;
}
方案三:nginx_upstream_check_module模块主动检测:
在nginx.conf配置文件里面的upstream加入健康检查,如下: upstream name {
server 192.168.0.21:80;
server 192.168.0.22:80;
check interval=3000 rise=2 fall=5 timeout=1000 type=tcp;
}
对name这个负载均衡条目中的所有节点,每个3秒检测一次端口是否存活,请求2次正常则标记 realserver状态为up,如果检测 5 次都失败,则标记 realserver的状态为down,超时时间为1秒。
目前这个是比较好的解决方案,确保正常流量都能进入到后端业务服务进行处理。
具体安装:
yum -y install pcre-devel openssl openssl-devel
cd /usr/local/src/
wget http://nginx.org/download/nginx-1.12.1.tar.gz
tar -zxvf nginx-1.12.1.tar.gz
cd /usr/local/src
wget https://codeload.github.com/openresty/echo-nginx-module/tar.gz/refs/tags/v0.62
tar zxvf v0.62
#下载 nginx_upstream_check_module模块
cd /usr/local/src
wget https://codeload.github.com/yaoweibin/nginx_upstream_check_module/zip/master
unzip master
#为nginx打补丁
cd nginx-1.12.1
#查看对应nginx版本: ll ../nginx_upstream_check_module-master/
patch -p1 < ../nginx_upstream_check_module-master/check_1.12.1+.patch
#安装nginx
./configure --prefix=/usr/local/nginx --with-http_stub_status_module --with-http_ssl_module --with-http_stub_status_module --with-http_ssl_module --add-module=/usr/local/src/echo-nginx-module-0.62 --add-module=/usr/local/src/nginx_upstream_check_module-master
make -j2
make install
原因:我安装的nginx版本为1.12.1,在安装nginx_upstream_check_module模块时忘记修改补丁文件版本(先安装了1.5.12+,后面发现错了又安装1.12.1+),导致在在make时报错.
关于nginx健康检查机制:Nginx健康检查机制-CSDN博客
五、技术深度硬实力:透过问题看本质,解决问题和绕开问题。
透过问题看本质则是由虚到实,往深层次地挖掘:
大部分人看到这个502,就表面的认为偶尔服务异常不用关注。但问题的本质原因是什么?没深层次去挖掘。
在实践中遇到问题,不仅只解决问题,还要对问题刨根问底,深入挖掘问题发生的根本原因,这样可以系统性地修复问题,从而使其永久消失。从问题本身着手,沿着因果关系链条,顺藤摸瓜,穿越不同的抽象层面,直至找出原有问题的根本原因.
我们中国古代以来就有“打破沙锅问到底”的习惯;“打破沙锅问到底”是一句俗语,形象表达了锲而不舍、不断探索的精神,这是人们常挂在嘴边的一句口头禅。
我们遇到问题,从外到里,逐层分析:
1、问题表象是什么
2、直接原因是什么?
3、中间原因是什么?
4、根本原因是什么?
深层次挖掘:接入nginx-》业务nginx-》service 。
直接原因:直接原因是接口xxxx/container大量请求超时,解决接口xxxx/container超时后,到这虽然可以解决本次问题,但下次是否还会出现?
中间原因:接入层nginx健康检查机制配置不合理,负责nginx的人员应该具备这些专业知识。作为接入层,是不能拦截正常的业务请求,要确保业务请求流量都转发待业务nignx,如果不解决好,下次另外的接口处理频繁处理超时,是不是也要剔除业务nginx?
根本原因:接入层单纯做负载均衡,健康检查最好是使用只检测端口存活,具体http异常应该由业务nginx进行处理。
表象:是http应用协议调用,接口xxxx/container大量请求超时导致。
中层:tcp/ip跨网络调用。
底层:操作系统如何封装tcp/ip,然后通过网卡,路由器等介质进行传输。
透过问题看本质能够敏锐地发现底层之真实,系统性端到端地思考问题,识别木桶的短板并解决之。
4、挖掘本质
又回到由浅入深学习层次:了解——熟悉——掌握——精通——专家
1、了解:入门,简单的认知和记忆,表示知道。是最低水平的认知学习结果。
2、熟悉:概念,了解概念得清楚,清楚地知道概念;(对某种技术或学问)侧重于知道得清楚,比了解更进一层。
2、掌握:规则、应用规则到实践,是在熟悉的基础上能充分加以运用。
3、精通:高级规则,深入底层。
4、专家:扩展创新。
将世界万物理解为原子,将整个互联网理解成0和1,这倒的确是非常本质了,不过并不能解答任何问题。从问题现象看本质,实质上是一个从表层逐步深入的过程。
说到透过现象看本质,其实就是黄金思维圈,你在技术上遇到每一件事情, 首先问“为什么”, 所谓黄金思维圈, 其实是我们认知世界的方式。 我们看问题的方式。
可以分为三个层面——
第一个层面是what层面, 也就是事情的表象, 我们具体做的每一件事;
第二个层面是how层面, 也就是我们如何实现我们想要做的事情;
第三个层面是why层面, 也就是我们为什么做这样的事情。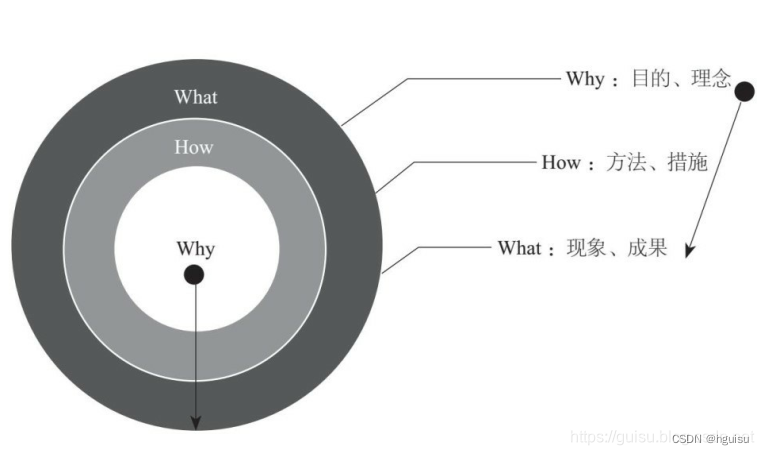
六、nginx常见错误总结
Nginx中常见问题与错误处理-CSDN博客
错误日志[Error.log]
| 错误信息 | 错误说明 |
| “upstream prematurely(过早的) closed connection” | 请求uri的时候出现的异常,是由于upstream还未返回应答给用户时用户断掉连接造成的,对系统没有影响,可以忽略 |
| “recv() failed (104: Connection reset by peer)” | (1)服务器的并发连接数超过了其承载量,服务器会将其中一些连接Down掉; (2)客户关掉了浏览器,而服务器还在给客户端发送数据; (3)浏览器端按了Stop |
| “(111: Connection refused) while connecting to upstream” | 用户在连接时,若遇到后端upstream挂掉或者不通,会收到该错误 |
| “(111: Connection refused) while reading response header from upstream” | 用户在连接成功后读取数据时,若遇到后端upstream挂掉或者不通,会收到该错误 |
| “(111: Connection refused) while sending request to upstream” | Nginx和upstream连接成功后发送数据时,若遇到后端upstream挂掉或者不通,会收到该错误 |
| “(110: Connection timed out) while connecting to upstream” | nginx连接后面的upstream时超时 |
| “(110: Connection timed out) while reading upstream” | nginx读取来自upstream的响应时超时 |
| “(110: Connection timed out) while reading response header from upstream” | nginx读取来自upstream的响应头时超时 |
| “(110: Connection timed out) while reading upstream” | nginx读取来自upstream的响应时超时 |
| “(104: Connection reset by peer) while connecting to upstream” | upstream发送了RST,将连接重置 |
| “upstream sent invalid header while reading response header from upstream” | upstream发送的响应头无效 |
| “upstream sent no valid HTTP/1.0 header while reading response header from upstream” | upstream发送的响应头无效 |
| “client intended to send too large body” | 用于设置允许接受的客户端请求内容的最大值,默认值是1M,client发送的body超过了设置值 |
| “reopening logs” | 用户发送kill -USR1命令 |
| “gracefully shutting down”, | 用户发送kill -WINCH命令 |
| “no servers are inside upstream” | upstream下未配置server |
| “no live upstreams while connecting to upstream” | upstream下的server全都挂了 |
| “SSL_do_handshake() failed” | SSL握手失败 |
| “SSL_write() failed (SSL:) while sending to client” | |
| “(13: Permission denied) while reading upstream” | |
| “(98: Address already in use) while connecting to upstream” | |
| “(99: Cannot assign requested address) while connecting to upstream” | |
| “ngx_slab_alloc() failed: no memory in SSL session shared cache” | ssl_session_cache大小不够等原因造成 |
| “could not add new SSL session to the session cache while SSL handshaking” | ssl_session_cache大小不够等原因造成 |
| “send() failed (111: Connection refused)” |
七、最后的总结
深度是根基,广度是枝叶。根深才能蒂固,枝繁才能叶茂,十年方可树木。
深度是专业:根深,事情做到专业职业,专业才能可靠。
广度是全面:枝繁,业务掌握全面透彻,全面才能靠谱
这篇关于架构师技能:技术深度硬实力透过问题看本质--深入分析nginx偶尔502错误根因的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





